 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Emotion Recognition from Low Quality and Low Bit Rate Video: A Deep Learning Approach
Paper and Code

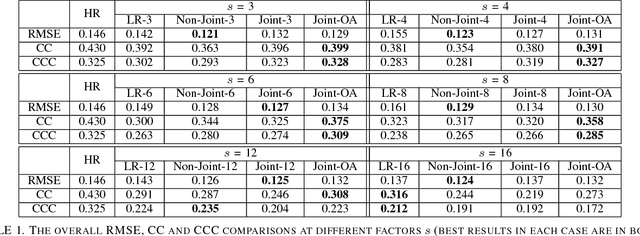

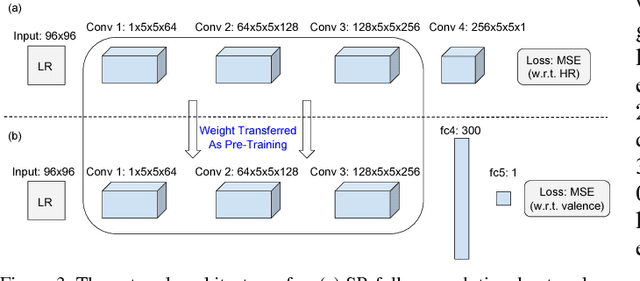
Emotion recognition from facial expressions is tremendously useful, especially when coupled with smart devices and wireless multimedia applications. However, the inadequate network bandwidth often limits the spatial resolution of the transmitted video, which will heavily degrade the recognition reliability. We develop a novel framework to achieve robust emotion recognition from low bit rate video. While video frames are downsampled at the encoder side, the decoder is embedded with a deep network model for joint super-resolution (SR) and recognition. Notably, we propose a novel max-mix training strategy, leading to a single "One-for-All" model that is remarkably robust to a vast range of downsampling factors. That makes our framework well adapted for the varied bandwidths in real transmission scenarios, without hampering scalability or efficiency. The proposed framework is evaluated on the AVEC 2016 benchmark, and demonstrates significantly improved stand-alone recognition performance, as well as rate-distortion (R-D) performance, than either directly recognizing from LR frames, or separating SR and recognition.