 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRA-Muon: Spectral Steepest Descent on the Low-Rank Manifold
Jun 11, 2026Low-Rank Adaptation (LoRA) significantly reduces compute and memory costs for finetuning Deep Learning models but is often harder to tune than dense training: when using factor-wise optimizers such as AdamW, it is sensitive to initialization choices, its optimal learning rates transfer poorly across ranks, and it often fails to beat dense baselines. We derive LoRA-Muon by applying the Muon optimizer's spectral steepest-descent rule to the low-rank setting. Along with our split weight-decay rule, our main claim is that LoRA-Muon is a good low-rank proxy for full-rank Muon and Shampoo-family optimizers. Its optimal learning rates transfer across rank, width, depth, and factor-rescaling. In our compute-matched TinyShakespeare study, a rank-$2$ proxy recovers the dense best tested learning rate, and a rank-$32$ LoRA-Muon run attains lower mean validation loss than the dense baseline in the seed-averaged sweep. We further show that the Spectron optimizer depends on arbitrary factor scaling, so it would likely be a poor fit when finetuning starts from badly imbalanced factors, and that LoRA-RITE's simplified QR-coordinate core implements the same spectral update. LoRA-Muon computes that update without QR-decomposition and avoids storing second moments, making it more accelerator-friendly and memory-efficient.
Scalable High-Resolution Pixel-Space Image Synthesis with Hourglass Diffusion Transformers
Jan 21, 2024We present the Hourglass Diffusion Transformer (HDiT), an image generative model that exhibits linear scaling with pixel count, supporting training at high-resolution (e.g. $1024 \times 1024$) directly in pixel-space. Building on the Transformer architecture, which is known to scale to billions of parameters, it bridges the gap between the efficiency of convolutional U-Nets and the scalability of Transformers. HDiT trains successfully without typical high-resolution training techniques such as multiscale architectures, latent autoencoders or self-conditioning. We demonstrate that HDiT performs competitively with existing models on ImageNet $256^2$, and sets a new state-of-the-art for diffusion models on FFHQ-$1024^2$.
LAION-5B: An open large-scale dataset for training next generation image-text models
Oct 16, 2022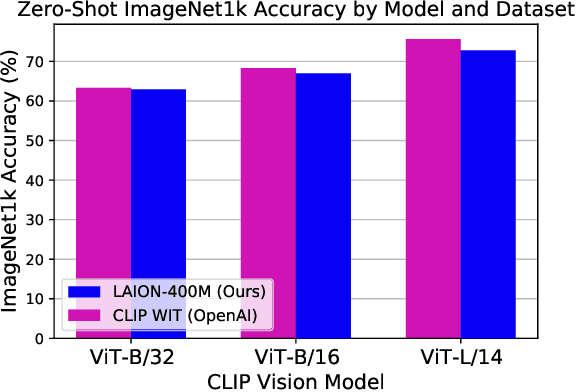
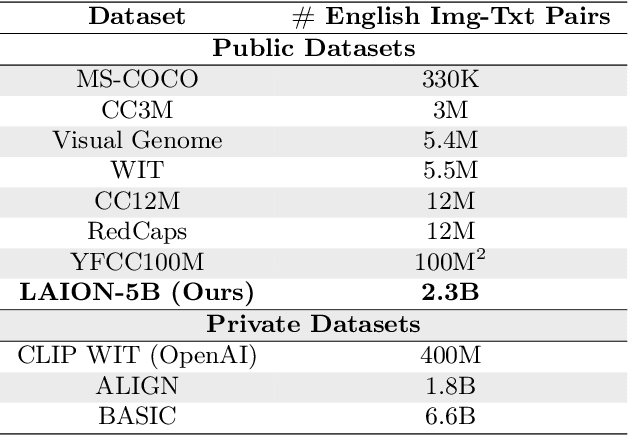
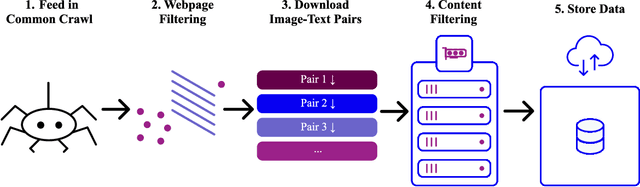
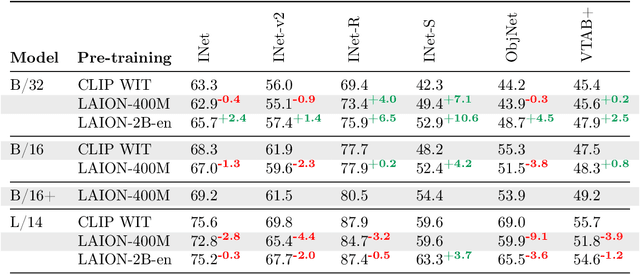
Groundbreaking language-vision architectures like CLIP and DALL-E proved the utility of training on large amounts of noisy image-text data, without relying on expensive accurate labels used in standard vision unimodal supervised learning. The resulting models showed capabilities of strong text-guided image generation and transfer to downstream tasks, while performing remarkably at zero-shot classification with noteworthy out-of-distribution robustness. Since then, large-scale language-vision models like ALIGN, BASIC, GLIDE, Flamingo and Imagen made further improvements. Studying the training and capabilities of such models requires datasets containing billions of image-text pairs. Until now, no datasets of this size have been made openly available for the broader research community. To address this problem and democratize research on large-scale multi-modal models, we present LAION-5B - a dataset consisting of 5.85 billion CLIP-filtered image-text pairs, of which 2.32B contain English language. We show successful replication and fine-tuning of foundational models like CLIP, GLIDE and Stable Diffusion using the dataset, and discuss further experiments enabled with an openly available dataset of this scale. Additionally we provide several nearest neighbor indices, an improved web-interface for dataset exploration and subset generation, and detection scores for watermark, NSFW, and toxic content detection. Announcement page https://laion.ai/laion-5b-a-new-era-of-open-large-scale-multi-modal-datasets/
VQGAN-CLIP: Open Domain Image Generation and Editing with Natural Language Guidance
Apr 18, 2022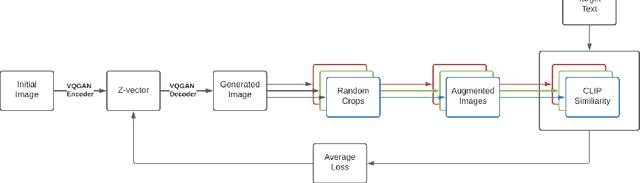
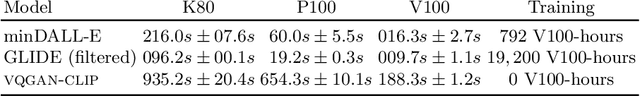


Generating and editing images from open domain text prompts is a challenging task that heretofore has required expensive and specially trained models. We demonstrate a novel methodology for both tasks which is capable of producing images of high visual quality from text prompts of significant semantic complexity without any training by using a multimodal encoder to guide image generations. We demonstrate on a variety of tasks how using CLIP [37] to guide VQGAN [11] produces higher visual quality outputs than prior, less flexible approaches like DALL-E [38], GLIDE [33] and Open-Edit [24], despite not being trained for the tasks presented. Our code is available in a public repository.