 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBigO(Bench) -- Can LLMs Generate Code with Controlled Time and Space Complexity?
Mar 20, 2025We introduce BigO(Bench), a novel coding benchmark designed to evaluate the capabilities of generative language models in understanding and generating code with specified time and space complexities. This benchmark addresses the gap in current evaluations that often overlook the ability of models to comprehend and produce code constrained by computational complexity. BigO(Bench) includes tooling to infer the algorithmic complexity of any Python function from profiling measurements, including human- or LLM-generated solutions. BigO(Bench) also includes of set of 3,105 coding problems and 1,190,250 solutions from Code Contests annotated with inferred (synthetic) time and space complexity labels from the complexity framework, as well as corresponding runtime and memory footprint values for a large set of input sizes. We present results from evaluating multiple state-of-the-art language models on this benchmark, highlighting their strengths and weaknesses in handling complexity requirements. In particular, token-space reasoning models are unrivaled in code generation but not in complexity understanding, hinting that they may not generalize well to tasks for which no reward was given at training time.
SpiRit-LM: Interleaved Spoken and Written Language Model
Feb 08, 2024We introduce SPIRIT-LM, a foundation multimodal language model that freely mixes text and speech. Our model is based on a pretrained text language model that we extend to the speech modality by continuously training it on text and speech units. Speech and text sequences are concatenated as a single set of tokens, and trained with a word-level interleaving method using a small automatically-curated speech-text parallel corpus. SPIRIT-LM comes in two versions: a BASE version that uses speech semantic units and an EXPRESSIVE version that models expressivity using pitch and style units in addition to the semantic units. For both versions, the text is encoded with subword BPE tokens. The resulting model displays both the semantic abilities of text models and the expressive abilities of speech models. Additionally, we demonstrate that SPIRIT-LM is able to learn new tasks in a few-shot fashion across modalities (i.e. ASR, TTS, Speech Classification).
Generative Spoken Language Model based on continuous word-sized audio tokens
Oct 08, 2023



In NLP, text language models based on words or subwords are known to outperform their character-based counterparts. Yet, in the speech community, the standard input of spoken LMs are 20ms or 40ms-long discrete units (shorter than a phoneme). Taking inspiration from word-based LM, we introduce a Generative Spoken Language Model (GSLM) based on word-size continuous-valued audio embeddings that can generate diverse and expressive language output. This is obtained by replacing lookup table for lexical types with a Lexical Embedding function, the cross entropy loss by a contrastive loss, and multinomial sampling by k-NN sampling. The resulting model is the first generative language model based on word-size continuous embeddings. Its performance is on par with discrete unit GSLMs regarding generation quality as measured by automatic metrics and subjective human judgements. Moreover, it is five times more memory efficient thanks to its large 200ms units. In addition, the embeddings before and after the Lexical Embedder are phonetically and semantically interpretable.
XLS-R fine-tuning on noisy word boundaries for unsupervised speech segmentation into words
Oct 08, 2023



Due to the absence of explicit word boundaries in the speech stream, the task of segmenting spoken sentences into word units without text supervision is particularly challenging. In this work, we leverage the most recent self-supervised speech models that have proved to quickly adapt to new tasks through fine-tuning, even in low resource conditions. Taking inspiration from semi-supervised learning, we fine-tune an XLS-R model to predict word boundaries themselves produced by top-tier speech segmentation systems: DPDP, VG-HuBERT, GradSeg and DP-Parse. Once XLS-R is fine-tuned, it is used to infer new word boundary labels that are used in turn for another fine-tuning step. Our method consistently improves the performance of each system and sets a new state-of-the-art that is, on average 130% higher than the previous one as measured by the F1 score on correctly discovered word tokens on five corpora featuring different languages. Finally, our system can segment speech from languages unseen during fine-tuning in a zero-shot fashion.
Speech Sequence Embeddings using Nearest Neighbors Contrastive Learning
Apr 11, 2022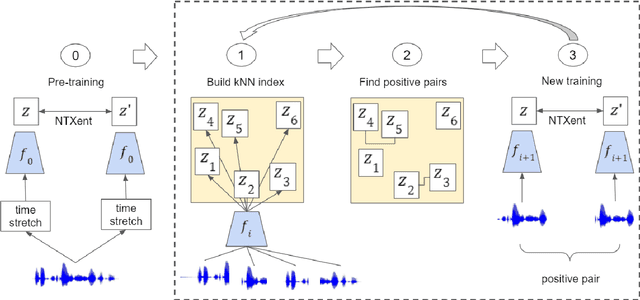
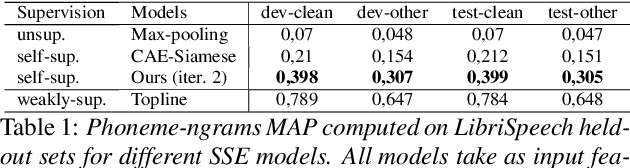
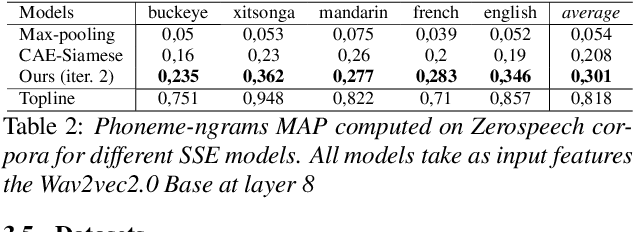

We introduce a simple neural encoder architecture that can be trained using an unsupervised contrastive learning objective which gets its positive samples from data-augmented k-Nearest Neighbors search. We show that when built on top of recent self-supervised audio representations, this method can be applied iteratively and yield competitive SSE as evaluated on two tasks: query-by-example of random sequences of speech, and spoken term discovery. On both tasks our method pushes the state-of-the-art by a significant margin across 5 different languages. Finally, we establish a benchmark on a query-by-example task on the LibriSpeech dataset to monitor future improvements in the field.
Generative Spoken Dialogue Language Modeling
Mar 30, 2022
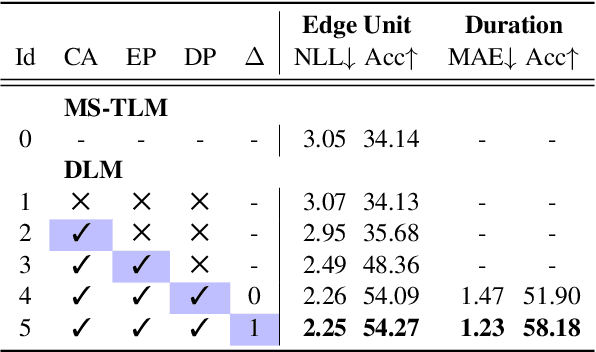
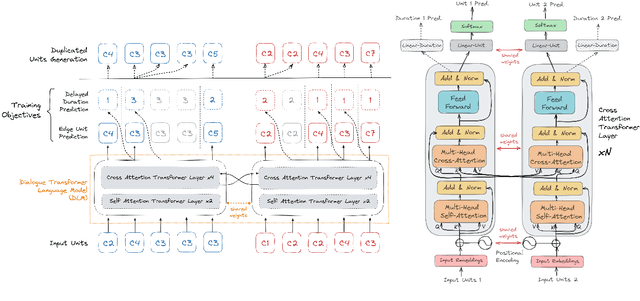
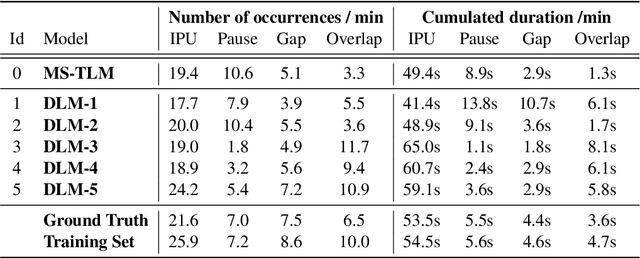
We introduce dGSLM, the first "textless" model able to generate audio samples of naturalistic spoken dialogues. It uses recent work on unsupervised spoken unit discovery coupled with a dual-tower transformer architecture with cross-attention trained on 2000 hours of two-channel raw conversational audio (Fisher dataset) without any text or labels. It is able to generate speech, laughter and other paralinguistic signals in the two channels simultaneously and reproduces naturalistic turn taking. Generation samples can be found at: https://speechbot.github.io/dgslm.
Are discrete units necessary for Spoken Language Modeling?
Mar 11, 2022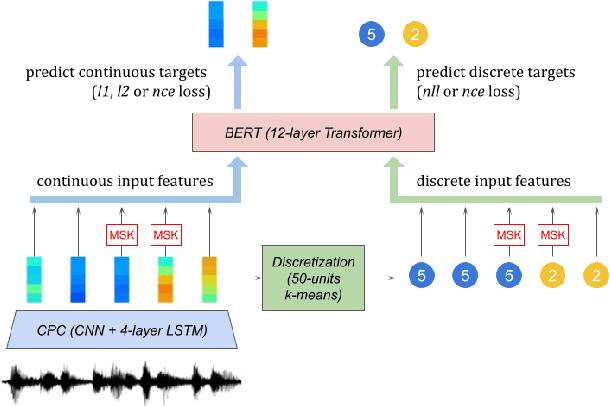
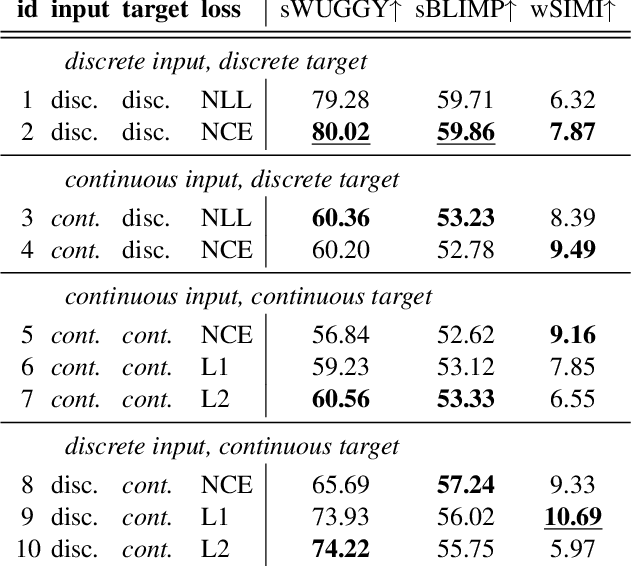
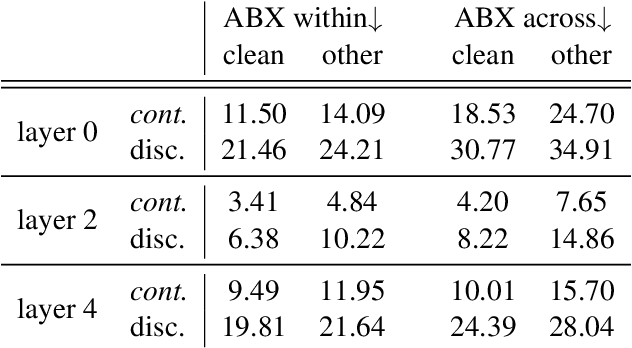
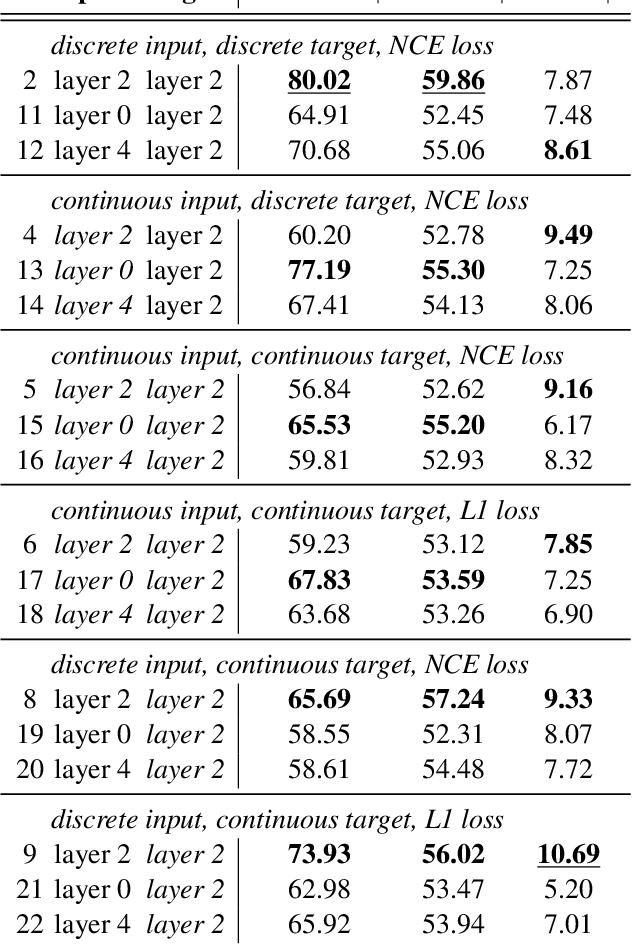
Recent work in spoken language modeling shows the possibility of learning a language unsupervisedly from raw audio without any text labels. The approach relies first on transforming the audio into a sequence of discrete units (or pseudo-text) and then training a language model directly on such pseudo-text. Is such a discrete bottleneck necessary, potentially introducing irreversible errors in the encoding of the speech signal, or could we learn a language model without discrete units at all? In this work, show that discretization is indeed essential for good results in spoken language modeling, but that can omit the discrete bottleneck if we use using discrete target features from a higher level than the input features. We also show that an end-to-end model trained with discrete target like HuBERT achieves similar results as the best language model trained on pseudo-text on a set of zero-shot spoken language modeling metrics from the Zero Resource Speech Challenge 2021.
Evaluating the reliability of acoustic speech embeddings
Jul 27, 2020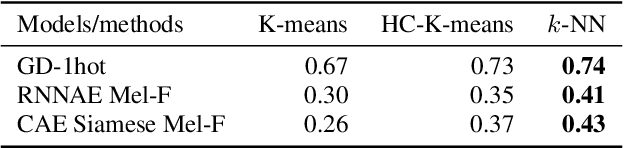
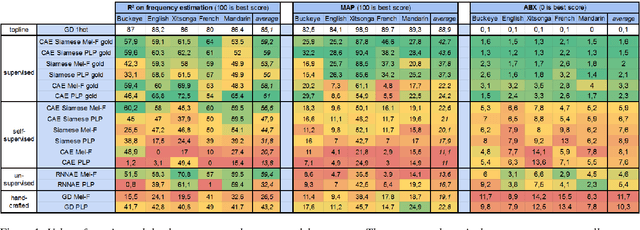

Speech embeddings are fixed-size acoustic representations of variable-length speech sequences. They are increasingly used for a variety of tasks ranging from information retrieval to unsupervised term discovery and speech segmentation. However, there is currently no clear methodology to compare or optimise the quality of these embeddings in a task-neutral way. Here, we systematically compare two popular metrics, ABX discrimination and Mean Average Precision (MAP), on 5 languages across 17 embedding methods, ranging from supervised to fully unsupervised, and using different loss functions (autoencoders, correspondence autoencoders, siamese). Then we use the ABX and MAP to predict performances on a new downstream task: the unsupervised estimation of the frequencies of speech segments in a given corpus. We find that overall, ABX and MAP correlate with one another and with frequency estimation. However, substantial discrepancies appear in the fine-grained distinctions across languages and/or embedding methods. This makes it unrealistic at present to propose a task-independent silver bullet method for computing the intrinsic quality of speech embeddings. There is a need for more detailed analysis of the metrics currently used to evaluate such embeddings.
Can Multilingual Language Models Transfer to an Unseen Dialect? A Case Study on North African Arabizi
May 01, 2020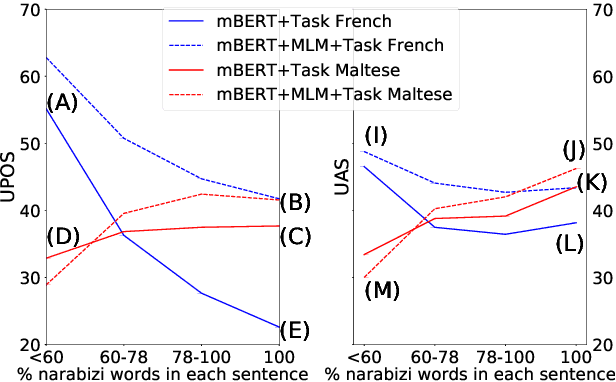
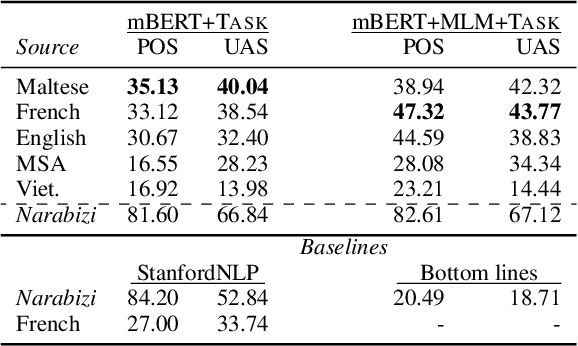


Building natural language processing systems for non standardized and low resource languages is a difficult challenge. The recent success of large-scale multilingual pretrained language models provides new modeling tools to tackle this. In this work, we study the ability of multilingual language models to process an unseen dialect. We take user generated North-African Arabic as our case study, a resource-poor dialectal variety of Arabic with frequent code-mixing with French and written in Arabizi, a non-standardized transliteration of Arabic to Latin script. Focusing on two tasks, part-of-speech tagging and dependency parsing, we show in zero-shot and unsupervised adaptation scenarios that multilingual language models are able to transfer to such an unseen dialect, specifically in two extreme cases: (i) across scripts, using Modern Standard Arabic as a source language, and (ii) from a distantly related language, unseen during pretraining, namely Maltese. Our results constitute the first successful transfer experiments on this dialect, paving thus the way for the development of an NLP ecosystem for resource-scarce, non-standardized and highly variable vernacular languages.