 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the reliability of acoustic speech embeddings
Jul 27, 2020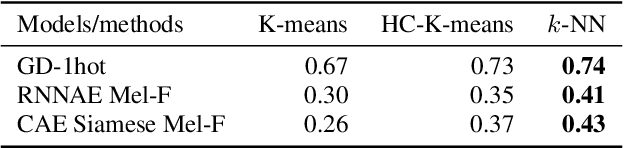
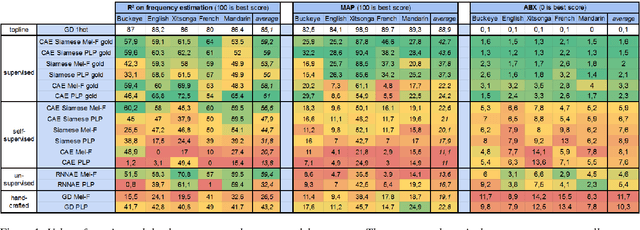

Speech embeddings are fixed-size acoustic representations of variable-length speech sequences. They are increasingly used for a variety of tasks ranging from information retrieval to unsupervised term discovery and speech segmentation. However, there is currently no clear methodology to compare or optimise the quality of these embeddings in a task-neutral way. Here, we systematically compare two popular metrics, ABX discrimination and Mean Average Precision (MAP), on 5 languages across 17 embedding methods, ranging from supervised to fully unsupervised, and using different loss functions (autoencoders, correspondence autoencoders, siamese). Then we use the ABX and MAP to predict performances on a new downstream task: the unsupervised estimation of the frequencies of speech segments in a given corpus. We find that overall, ABX and MAP correlate with one another and with frequency estimation. However, substantial discrepancies appear in the fine-grained distinctions across languages and/or embedding methods. This makes it unrealistic at present to propose a task-independent silver bullet method for computing the intrinsic quality of speech embeddings. There is a need for more detailed analysis of the metrics currently used to evaluate such embeddings.