 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMERLIN: A Testbed for Multilingual Multimodal Entity Recognition and Linking
Oct 16, 2025This paper introduces MERLIN, a novel testbed system for the task of Multilingual Multimodal Entity Linking. The created dataset includes BBC news article titles, paired with corresponding images, in five languages: Hindi, Japanese, Indonesian, Vietnamese, and Tamil, featuring over 7,000 named entity mentions linked to 2,500 unique Wikidata entities. We also include several benchmarks using multilingual and multimodal entity linking methods exploring different language models like LLaMa-2 and Aya-23. Our findings indicate that incorporating visual data improves the accuracy of entity linking, especially for entities where the textual context is ambiguous or insufficient, and particularly for models that do not have strong multilingual abilities. For the work, the dataset, methods are available here at https://github.com/rsathya4802/merlin
Pangea: A Fully Open Multilingual Multimodal LLM for 39 Languages
Oct 21, 2024Despite recent advances in multimodal large language models (MLLMs), their development has predominantly focused on English- and western-centric datasets and tasks, leaving most of the world's languages and diverse cultural contexts underrepresented. This paper introduces Pangea, a multilingual multimodal LLM trained on PangeaIns, a diverse 6M instruction dataset spanning 39 languages. PangeaIns features: 1) high-quality English instructions, 2) carefully machine-translated instructions, and 3) culturally relevant multimodal tasks to ensure cross-cultural coverage. To rigorously assess models' capabilities, we introduce PangeaBench, a holistic evaluation suite encompassing 14 datasets covering 47 languages. Results show that Pangea significantly outperforms existing open-source models in multilingual settings and diverse cultural contexts. Ablation studies further reveal the importance of English data proportions, language popularity, and the number of multimodal training samples on overall performance. We fully open-source our data, code, and trained checkpoints, to facilitate the development of inclusive and robust multilingual MLLMs, promoting equity and accessibility across a broader linguistic and cultural spectrum.
An image speaks a thousand words, but can everyone listen? On translating images for cultural relevance
Apr 01, 2024



Given the rise of multimedia content, human translators increasingly focus on culturally adapting not only words but also other modalities such as images to convey the same meaning. While several applications stand to benefit from this, machine translation systems remain confined to dealing with language in speech and text. In this work, we take a first step towards translating images to make them culturally relevant. First, we build three pipelines comprising state-of-the-art generative models to do the task. Next, we build a two-part evaluation dataset: i) concept: comprising 600 images that are cross-culturally coherent, focusing on a single concept per image, and ii) application: comprising 100 images curated from real-world applications. We conduct a multi-faceted human evaluation of translated images to assess for cultural relevance and meaning preservation. We find that as of today, image-editing models fail at this task, but can be improved by leveraging LLMs and retrievers in the loop. Best pipelines can only translate 5% of images for some countries in the easier concept dataset and no translation is successful for some countries in the application dataset, highlighting the challenging nature of the task. Our code and data is released here: https://github.com/simran-khanuja/image-transcreation.
IMAGINATOR: Pre-Trained Image+Text Joint Embeddings using Word-Level Grounding of Images
May 12, 2023



Word embeddings, i.e., semantically meaningful vector representation of words, are largely influenced by the distributional hypothesis "You shall know a word by the company it keeps" (Harris, 1954), whereas modern prediction-based neural network embeddings rely on design choices and hyperparameter optimization. Word embeddings like Word2Vec, GloVe etc. well capture the contextuality and real-world analogies but contemporary convolution-based image embeddings such as VGGNet, AlexNet, etc. do not capture contextual knowledge. The popular king-queen analogy does not hold true for most commonly used vision embeddings. In this paper, we introduce a pre-trained joint embedding (JE), named IMAGINATOR, trained on 21K distinct image objects level from 1M image+text pairs. JE is a way to encode multimodal data into a vector space where the text modality serves as the ground-ing key, which the complementary modality (in this case, the image) is anchored with. IMAGINATOR encapsulates three individual representations: (i) object-object co-location, (ii) word-object co-location, and (iii) word-object correlation. These three ways capture complementary aspects of the two modalities which are further combined to obtain the final JEs. Generated JEs are intrinsically evaluated to assess how well they capture the contextuality and real-world analogies. We also evaluate pre-trained IMAGINATOR JEs on three downstream tasks: (i) image captioning, (ii) Image2Tweet, and (iii) text-based image retrieval. IMAGINATOR establishes a new standard on the aforementioned down-stream tasks by outperforming the current SoTA on all the selected tasks. IMAGINATOR will be made publicly available. The codes are available at https://github.com/varunakk/IMAGINATOR
Memotion Analysis through the Lens of Joint Embedding
Dec 03, 2021
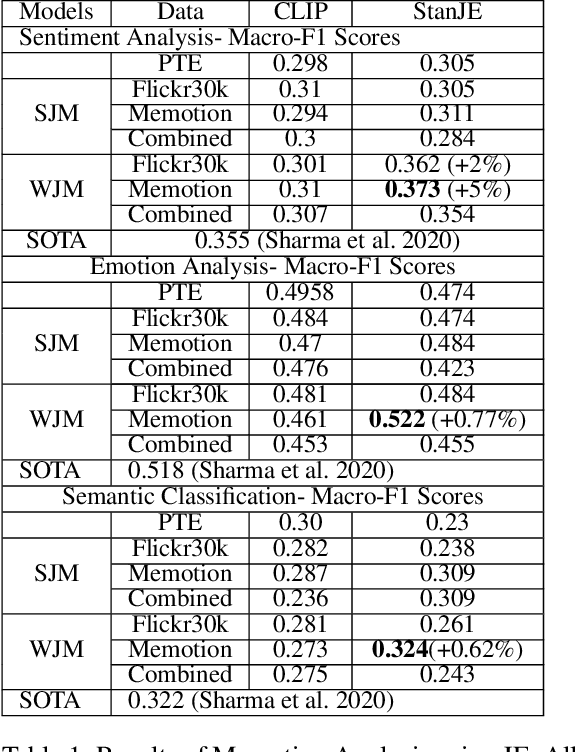
Joint embedding (JE) is a way to encode multi-modal data into a vector space where text remains as the grounding key and other modalities like image are to be anchored with such keys. Meme is typically an image with embedded text onto it. Although, memes are commonly used for fun, they could also be used to spread hate and fake information. That along with its growing ubiquity over several social platforms has caused automatic analysis of memes to become a widespread topic of research. In this paper, we report our initial experiments on Memotion Analysis problem through joint embeddings. Results are marginally yielding SOTA.