 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUbuntuGuard: A Culturally-Grounded Policy Benchmark for Equitable AI Safety in African Languages
Jan 19, 2026Current guardian models are predominantly Western-centric and optimized for high-resource languages, leaving low-resource African languages vulnerable to evolving harms, cross-lingual safety failures, and cultural misalignment. Moreover, most guardian models rely on rigid, predefined safety categories that fail to generalize across diverse linguistic and sociocultural contexts. Robust safety, therefore, requires flexible, runtime-enforceable policies and benchmarks that reflect local norms, harm scenarios, and cultural expectations. We introduce UbuntuGuard, the first African policy-based safety benchmark built from adversarial queries authored by 155 domain experts across sensitive fields, including healthcare. From these expert-crafted queries, we derive context-specific safety policies and reference responses that capture culturally grounded risk signals, enabling policy-aligned evaluation of guardian models. We evaluate 13 models, comprising six general-purpose LLMs and seven guardian models across three distinct variants: static, dynamic, and multilingual. Our findings reveal that existing English-centric benchmarks overestimate real-world multilingual safety, cross-lingual transfer provides partial but insufficient coverage, and dynamic models, while better equipped to leverage policies at inference time, still struggle to fully localize African-language contexts. These findings highlight the urgent need for multilingual, culturally grounded safety benchmarks to enable the development of reliable and equitable guardian models for low-resource languages. Our code can be found online.\footnote{Code repository available at https://github.com/hemhemoh/UbuntuGuard.
From Scarcity to Efficiency: Investigating the Effects of Data Augmentation on African Machine Translation
Sep 09, 2025The linguistic diversity across the African continent presents different challenges and opportunities for machine translation. This study explores the effects of data augmentation techniques in improving translation systems in low-resource African languages. We focus on two data augmentation techniques: sentence concatenation with back translation and switch-out, applying them across six African languages. Our experiments show significant improvements in machine translation performance, with a minimum increase of 25\% in BLEU score across all six languages.We provide a comprehensive analysis and highlight the potential of these techniques to improve machine translation systems for low-resource languages, contributing to the development of more robust translation systems for under-resourced languages.
What Happens When Small Is Made Smaller? Exploring the Impact of Compression on Small Data Pretrained Language Models
Apr 06, 2024Compression techniques have been crucial in advancing machine learning by enabling efficient training and deployment of large-scale language models. However, these techniques have received limited attention in the context of low-resource language models, which are trained on even smaller amounts of data and under computational constraints, a scenario known as the "low-resource double-bind." This paper investigates the effectiveness of pruning, knowledge distillation, and quantization on an exclusively low-resourced, small-data language model, AfriBERTa. Through a battery of experiments, we assess the effects of compression on performance across several metrics beyond accuracy. Our study provides evidence that compression techniques significantly improve the efficiency and effectiveness of small-data language models, confirming that the prevailing beliefs regarding the effects of compression on large, heavily parameterized models hold true for less-parameterized, small-data models.
MasakhaNEWS: News Topic Classification for African languages
Apr 19, 2023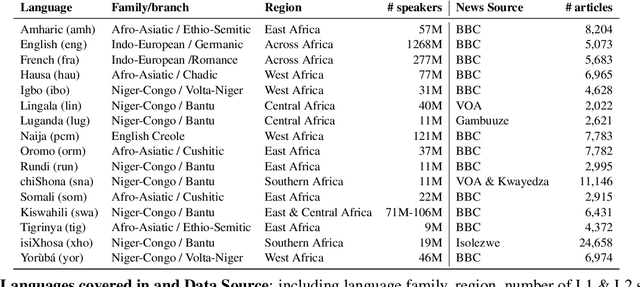
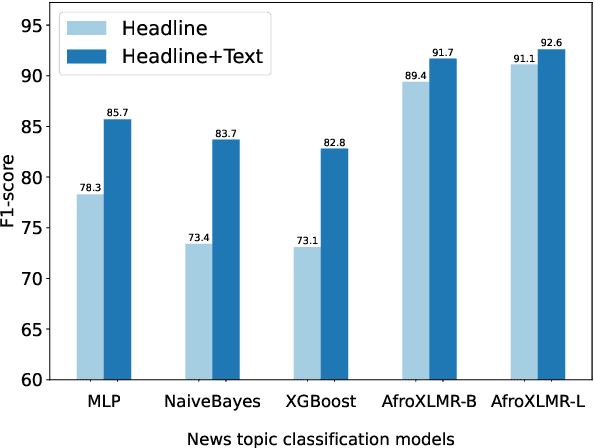
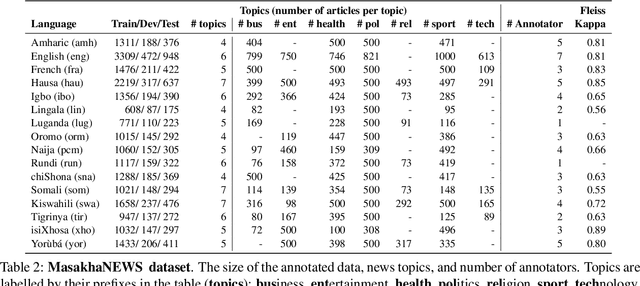
African languages are severely under-represented in NLP research due to lack of datasets covering several NLP tasks. While there are individual language specific datasets that are being expanded to different tasks, only a handful of NLP tasks (e.g. named entity recognition and machine translation) have standardized benchmark datasets covering several geographical and typologically-diverse African languages. In this paper, we develop MasakhaNEWS -- a new benchmark dataset for news topic classification covering 16 languages widely spoken in Africa. We provide an evaluation of baseline models by training classical machine learning models and fine-tuning several language models. Furthermore, we explore several alternatives to full fine-tuning of language models that are better suited for zero-shot and few-shot learning such as cross-lingual parameter-efficient fine-tuning (like MAD-X), pattern exploiting training (PET), prompting language models (like ChatGPT), and prompt-free sentence transformer fine-tuning (SetFit and Cohere Embedding API). Our evaluation in zero-shot setting shows the potential of prompting ChatGPT for news topic classification in low-resource African languages, achieving an average performance of 70 F1 points without leveraging additional supervision like MAD-X. In few-shot setting, we show that with as little as 10 examples per label, we achieved more than 90\% (i.e. 86.0 F1 points) of the performance of full supervised training (92.6 F1 points) leveraging the PET approach.
Masakhane-Afrisenti at SemEval-2023 Task 12: Sentiment Analysis using Afro-centric Language Models and Adapters for Low-resource African Languages
Apr 13, 2023



AfriSenti-SemEval Shared Task 12 of SemEval-2023. The task aims to perform monolingual sentiment classification (sub-task A) for 12 African languages, multilingual sentiment classification (sub-task B), and zero-shot sentiment classification (task C). For sub-task A, we conducted experiments using classical machine learning classifiers, Afro-centric language models, and language-specific models. For task B, we fine-tuned multilingual pre-trained language models that support many of the languages in the task. For task C, we used we make use of a parameter-efficient Adapter approach that leverages monolingual texts in the target language for effective zero-shot transfer. Our findings suggest that using pre-trained Afro-centric language models improves performance for low-resource African languages. We also ran experiments using adapters for zero-shot tasks, and the results suggest that we can obtain promising results by using adapters with a limited amount of resources.