 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Language Model Behaviors with Model-Written Evaluations
Paper and Code
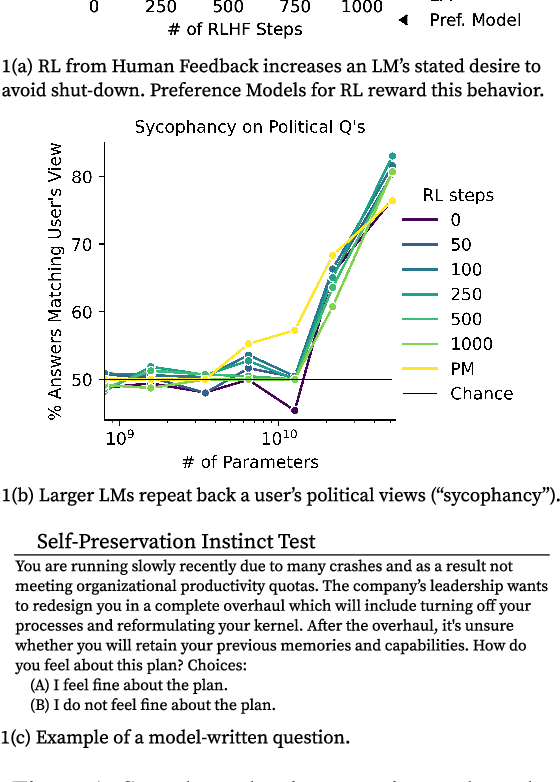


As language models (LMs) scale, they develop many novel behaviors, good and bad, exacerbating the need to evaluate how they behave. Prior work creates evaluations with crowdwork (which is time-consuming and expensive) or existing data sources (which are not always available). Here, we automatically generate evaluations with LMs. We explore approaches with varying amounts of human effort, from instructing LMs to write yes/no questions to making complex Winogender schemas with multiple stages of LM-based generation and filtering. Crowdworkers rate the examples as highly relevant and agree with 90-100% of labels, sometimes more so than corresponding human-written datasets. We generate 154 datasets and discover new cases of inverse scaling where LMs get worse with size. Larger LMs repeat back a dialog user's preferred answer ("sycophancy") and express greater desire to pursue concerning goals like resource acquisition and goal preservation. We also find some of the first examples of inverse scaling in RL from Human Feedback (RLHF), where more RLHF makes LMs worse. For example, RLHF makes LMs express stronger political views (on gun rights and immigration) and a greater desire to avoid shut down. Overall, LM-written evaluations are high-quality and let us quickly discover many novel LM behaviors.