 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehind Maya: Building a Multilingual Vision Language Model
May 15, 2025
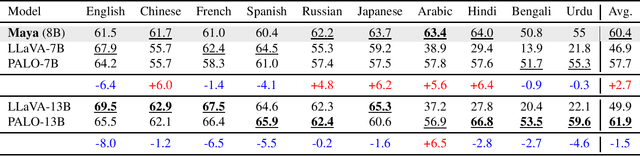
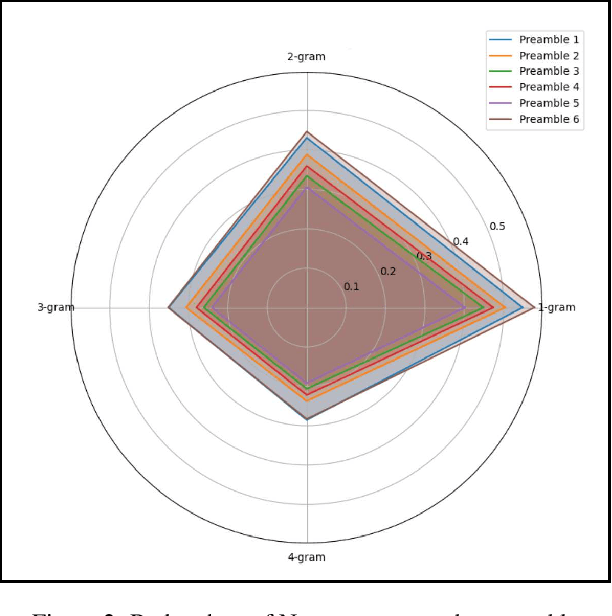

In recent times, we have seen a rapid development of large Vision-Language Models (VLMs). They have shown impressive results on academic benchmarks, primarily in widely spoken languages but lack performance on low-resource languages and varied cultural contexts. To address these limitations, we introduce Maya, an open-source Multilingual VLM. Our contributions are: 1) a multilingual image-text pretraining dataset in eight languages, based on the LLaVA pretraining dataset; and 2) a multilingual image-text model supporting these languages, enhancing cultural and linguistic comprehension in vision-language tasks. Code available at https://github.com/nahidalam/maya.
What's In Your Field? Mapping Scientific Research with Knowledge Graphs and Large Language Models
Mar 12, 2025


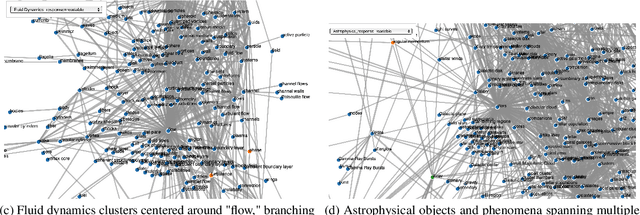
The scientific literature's exponential growth makes it increasingly challenging to navigate and synthesize knowledge across disciplines. Large language models (LLMs) are powerful tools for understanding scientific text, but they fail to capture detailed relationships across large bodies of work. Unstructured approaches, like retrieval augmented generation, can sift through such corpora to recall relevant facts; however, when millions of facts influence the answer, unstructured approaches become cost prohibitive. Structured representations offer a natural complement -- enabling systematic analysis across the whole corpus. Recent work enhances LLMs with unstructured or semistructured representations of scientific concepts; to complement this, we try extracting structured representations using LLMs. By combining LLMs' semantic understanding with a schema of scientific concepts, we prototype a system that answers precise questions about the literature as a whole. Our schema applies across scientific fields and we extract concepts from it using only 20 manually annotated abstracts. To demonstrate the system, we extract concepts from 30,000 papers on arXiv spanning astrophysics, fluid dynamics, and evolutionary biology. The resulting database highlights emerging trends and, by visualizing the knowledge graph, offers new ways to explore the ever-growing landscape of scientific knowledge. Demo: abby101/surveyor-0 on HF Spaces. Code: https://github.com/chiral-carbon/kg-for-science.
Maya: An Instruction Finetuned Multilingual Multimodal Model
Dec 10, 2024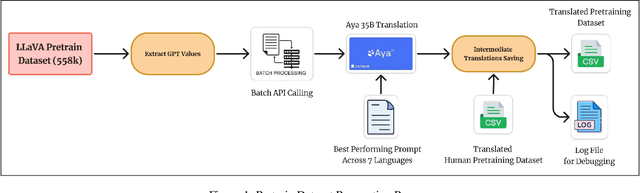
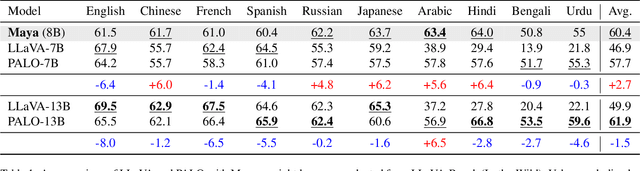
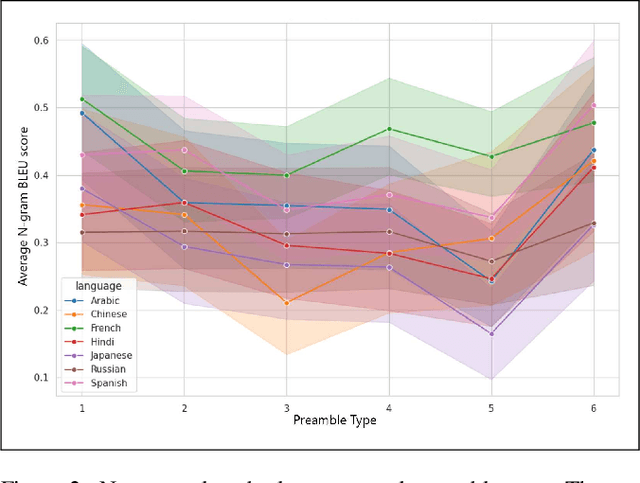
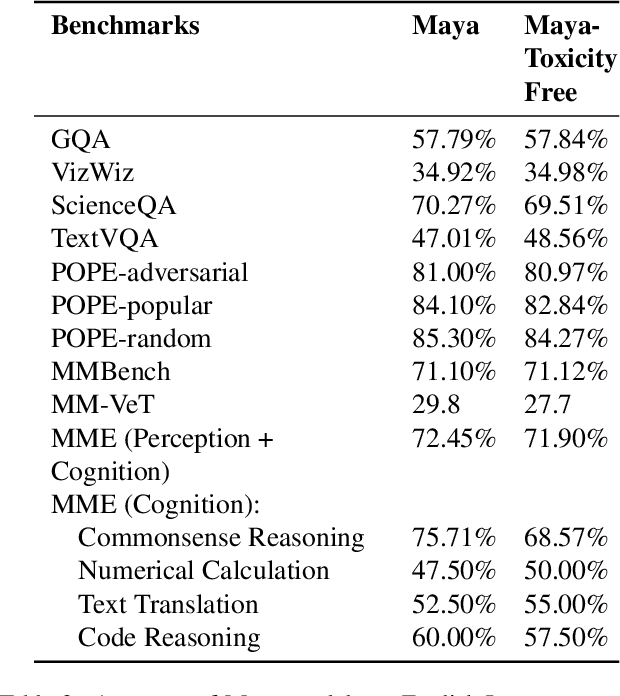
The rapid development of large Vision-Language Models (VLMs) has led to impressive results on academic benchmarks, primarily in widely spoken languages. However, significant gaps remain in the ability of current VLMs to handle low-resource languages and varied cultural contexts, largely due to a lack of high-quality, diverse, and safety-vetted data. Consequently, these models often struggle to understand low-resource languages and cultural nuances in a manner free from toxicity. To address these limitations, we introduce Maya, an open-source Multimodal Multilingual model. Our contributions are threefold: 1) a multilingual image-text pretraining dataset in eight languages, based on the LLaVA pretraining dataset; 2) a thorough analysis of toxicity within the LLaVA dataset, followed by the creation of a novel toxicity-free version across eight languages; and 3) a multilingual image-text model supporting these languages, enhancing cultural and linguistic comprehension in vision-language tasks. Code available at https://github.com/nahidalam/maya.