 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Documents In-Scope of a Collection from Web Archives
Paper and Code
Sep 02, 2020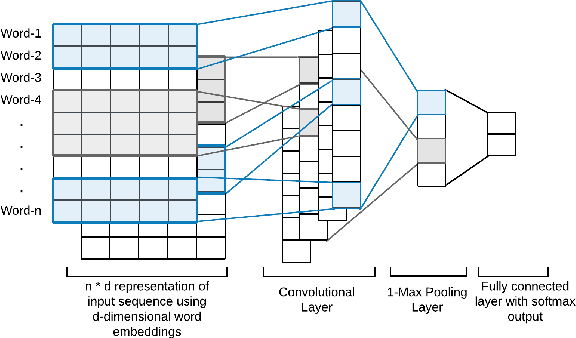

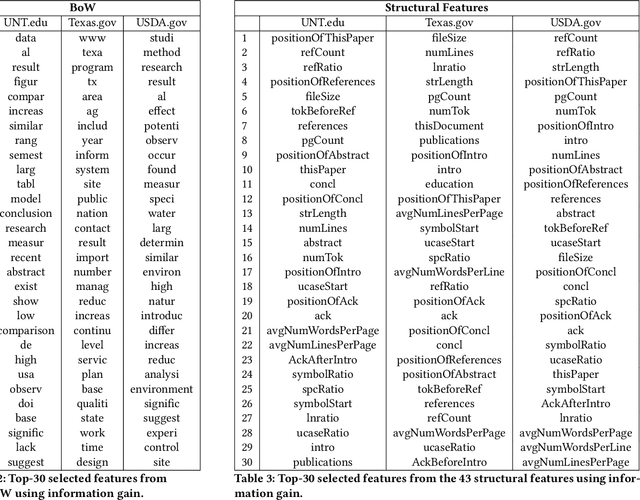

Web archive data usually contains high-quality documents that are very useful for creating specialized collections of documents, e.g., scientific digital libraries and repositories of technical reports. In doing so, there is a substantial need for automatic approaches that can distinguish the documents of interest for a collection out of the huge number of documents collected by web archiving institutions. In this paper, we explore different learning models and feature representations to determine the best performing ones for identifying the documents of interest from the web archived data. Specifically, we study both machine learning and deep learning models and "bag of words" (BoW) features extracted from the entire document or from specific portions of the document, as well as structural features that capture the structure of documents. We focus our evaluation on three datasets that we created from three different Web archives. Our experimental results show that the BoW classifiers that focus only on specific portions of the documents (rather than the full text) outperform all compared methods on all three datasets.