 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTBF-33: A multi-temporal building footprint dataset for 33 counties in the United States
Mar 21, 2022
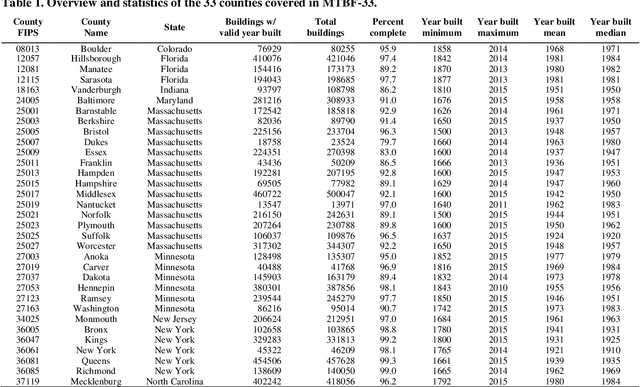
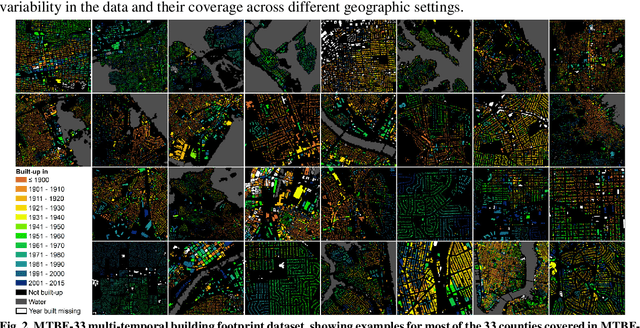
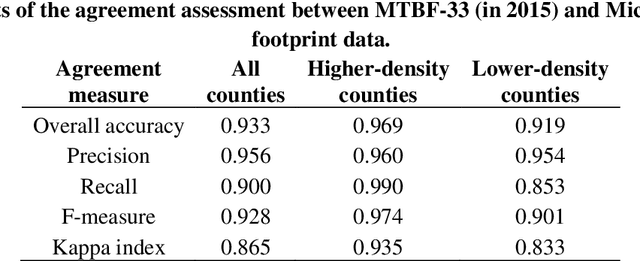
Despite abundant data on the spatial distribution of contemporary human settlements, historical data on the long-term evolution of human settlements at fine spatial and temporal granularity is scarce, limiting our quantitative understanding of long-term changes of built-up areas. This is because commonly used mapping methods (e.g., image classification) and suitable data sources (i.e., aerial imagery, multi-spectral remote sensing data, LiDAR) have only been available in recent decades. However, there are alternative data sources such as cadastral records that are digitally available, containing relevant information such as building age information, allowing for an approximate, digital reconstruction of past building distributions. We conducted a non-exhaustive search of open and publicly available data resources from administrative institutions in the United States and gathered, integrated, and harmonized cadastral parcel data, tax assessment data, and building footprint data for 33 counties, wherever building footprint geometries and building construction year information was available. The result of this effort is a unique dataset which we call the Multi-Temporal Building Footprint Dataset for 33 U.S. Counties (MTBF-33). MTBF-33 contains over 6.2 million building footprints including their construction year, and can be used to derive retrospective depictions of built-up areas from 1900 to 2015, at fine spatial and temporal grain and can be used for data validation purposes, or to train statistical learning approaches aiming to extract historical information on human settlements from remote sensing data, historical maps, or similar data sources. MTBF-33 is available at http://doi.org/10.17632/w33vbvjtdy.
Towards the automated large-scale reconstruction of past road networks from historical maps
Feb 11, 2022


Transportation infrastructure, such as road or railroad networks, represent a fundamental component of our civilization. For sustainable planning and informed decision making, a thorough understanding of the long-term evolution of transportation infrastructure such as road networks is crucial. However, spatially explicit, multi-temporal road network data covering large spatial extents are scarce and rarely available prior to the 2000s. Herein, we propose a framework that employs increasingly available scanned and georeferenced historical map series to reconstruct past road networks, by integrating abundant, contemporary road network data and color information extracted from historical maps. Specifically, our method uses contemporary road segments as analytical units and extracts historical roads by inferring their existence in historical map series based on image processing and clustering techniques. We tested our method on over 300,000 road segments representing more than 50,000 km of the road network in the United States, extending across three study areas that cover 53 historical topographic map sheets dated between 1890 and 1950. We evaluated our approach by comparison to other historical datasets and against manually created reference data, achieving F-1 scores of up to 0.95, and showed that the extracted road network statistics are highly plausible over time, i.e., following general growth patterns. We demonstrated that contemporary geospatial data integrated with information extracted from historical map series open up new avenues for the quantitative analysis of long-term urbanization processes and landscape changes far beyond the era of operational remote sensing and digital cartography.
A Label Correction Algorithm Using Prior Information for Automatic and Accurate Geospatial Object Recognition
Dec 10, 2021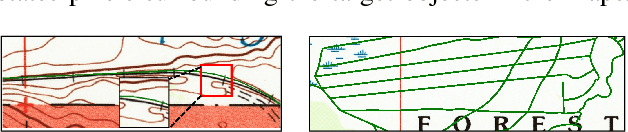
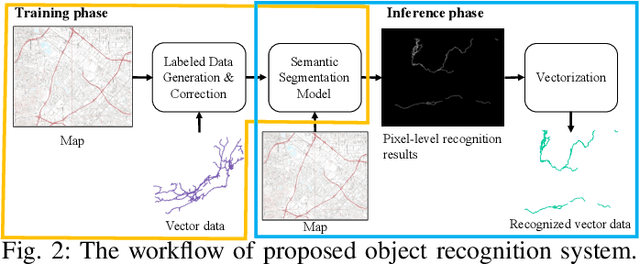

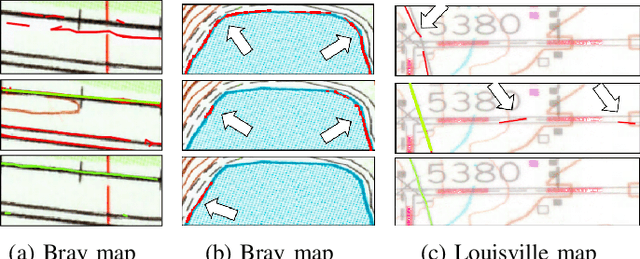
Thousands of scanned historical topographic maps contain valuable information covering long periods of time, such as how the hydrography of a region has changed over time. Efficiently unlocking the information in these maps requires training a geospatial objects recognition system, which needs a large amount of annotated data. Overlapping geo-referenced external vector data with topographic maps according to their coordinates can annotate the desired objects' locations in the maps automatically. However, directly overlapping the two datasets causes misaligned and false annotations because the publication years and coordinate projection systems of topographic maps are different from the external vector data. We propose a label correction algorithm, which leverages the color information of maps and the prior shape information of the external vector data to reduce misaligned and false annotations. The experiments show that the precision of annotations from the proposed algorithm is 10% higher than the annotations from a state-of-the-art algorithm. Consequently, recognition results using the proposed algorithm's annotations achieve 9% higher correctness than using the annotations from the state-of-the-art algorithm.
Guided Generative Models using Weak Supervision for Detecting Object Spatial Arrangement in Overhead Images
Dec 10, 2021
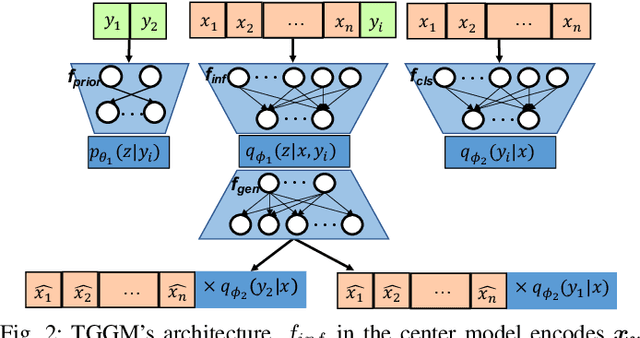
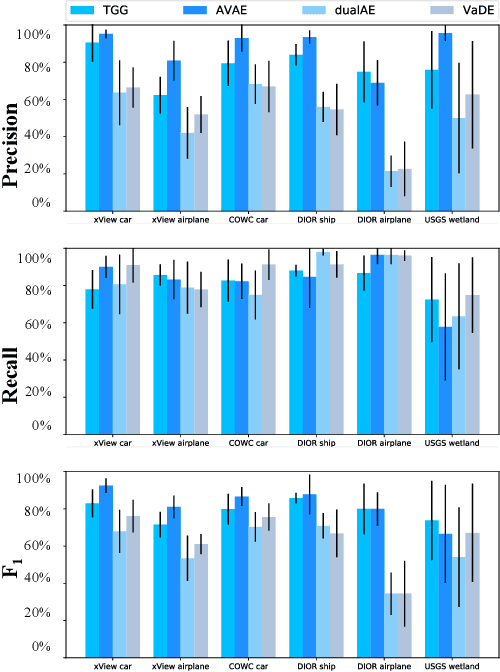

The increasing availability and accessibility of numerous overhead images allows us to estimate and assess the spatial arrangement of groups of geospatial target objects, which can benefit many applications, such as traffic monitoring and agricultural monitoring. Spatial arrangement estimation is the process of identifying the areas which contain the desired objects in overhead images. Traditional supervised object detection approaches can estimate accurate spatial arrangement but require large amounts of bounding box annotations. Recent semi-supervised clustering approaches can reduce manual labeling but still require annotations for all object categories in the image. This paper presents the target-guided generative model (TGGM), under the Variational Auto-encoder (VAE) framework, which uses Gaussian Mixture Models (GMM) to estimate the distributions of both hidden and decoder variables in VAE. Modeling both hidden and decoder variables by GMM reduces the required manual annotations significantly for spatial arrangement estimation. Unlike existing approaches that the training process can only update the GMM as a whole in the optimization iterations (e.g., a "minibatch"), TGGM allows the update of individual GMM components separately in the same optimization iteration. Optimizing GMM components separately allows TGGM to exploit the semantic relationships in spatial data and requires only a few labels to initiate and guide the generative process. Our experiments shows that TGGM achieves results comparable to the state-of-the-art semi-supervised methods and outperforms unsupervised methods by 10% based on the $F_{1}$ scores, while requiring significantly fewer labeled data.
An Automatic Approach for Generating Rich, Linked Geo-Metadata from Historical Map Images
Dec 03, 2021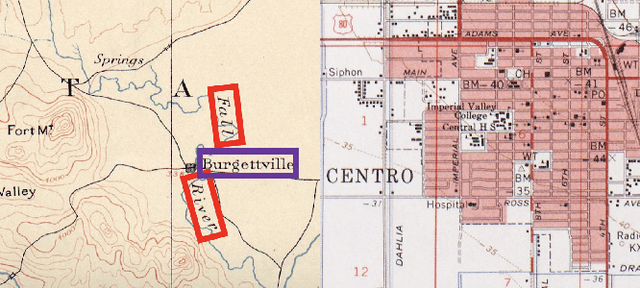
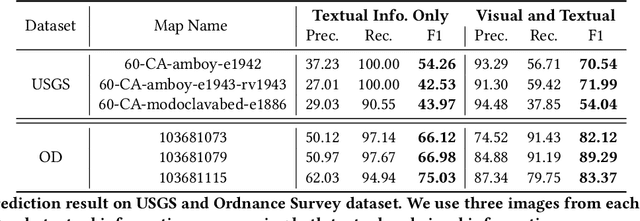
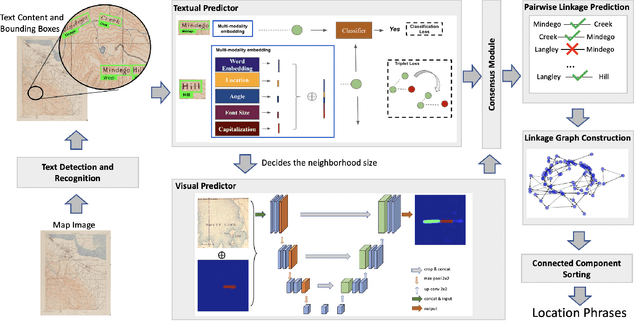
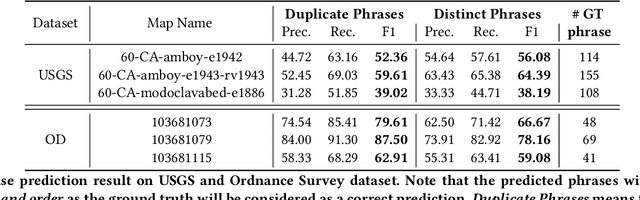
Historical maps contain detailed geographic information difficult to find elsewhere covering long-periods of time (e.g., 125 years for the historical topographic maps in the US). However, these maps typically exist as scanned images without searchable metadata. Existing approaches making historical maps searchable rely on tedious manual work (including crowd-sourcing) to generate the metadata (e.g., geolocations and keywords). Optical character recognition (OCR) software could alleviate the required manual work, but the recognition results are individual words instead of location phrases (e.g., "Black" and "Mountain" vs. "Black Mountain"). This paper presents an end-to-end approach to address the real-world problem of finding and indexing historical map images. This approach automatically processes historical map images to extract their text content and generates a set of metadata that is linked to large external geospatial knowledge bases. The linked metadata in the RDF (Resource Description Framework) format support complex queries for finding and indexing historical maps, such as retrieving all historical maps covering mountain peaks higher than 1,000 meters in California. We have implemented the approach in a system called mapKurator. We have evaluated mapKurator using historical maps from several sources with various map styles, scales, and coverage. Our results show significant improvement over the state-of-the-art methods. The code has been made publicly available as modules of the Kartta Labs project at https://github.com/kartta-labs/Project.