 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstructing Reference Sets from Unstructured, Ungrammatical Text
Paper and Code
Jan 16, 2014

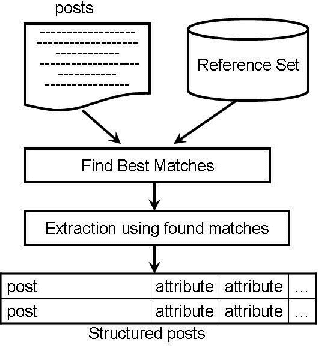

Vast amounts of text on the Web are unstructured and ungrammatical, such as classified ads, auction listings, forum postings, etc. We call such text "posts." Despite their inconsistent structure and lack of grammar, posts are full of useful information. This paper presents work on semi-automatically building tables of relational information, called "reference sets," by analyzing such posts directly. Reference sets can be applied to a number of tasks such as ontology maintenance and information extraction. Our reference-set construction method starts with just a small amount of background knowledge, and constructs tuples representing the entities in the posts to form a reference set. We also describe an extension to this approach for the special case where even this small amount of background knowledge is impossible to discover and use. To evaluate the utility of the machine-constructed reference sets, we compare them to manually constructed reference sets in the context of reference-set-based information extraction. Our results show the reference sets constructed by our method outperform manually constructed reference sets. We also compare the reference-set-based extraction approach using the machine-constructed reference set to supervised extraction approaches using generic features. These results demonstrate that using machine-constructed reference sets outperforms the supervised methods, even though the supervised methods require training data.