 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVOID: Video Object and Interaction Deletion
Apr 02, 2026Existing video object removal methods excel at inpainting content "behind" the object and correcting appearance-level artifacts such as shadows and reflections. However, when the removed object has more significant interactions, such as collisions with other objects, current models fail to correct them and produce implausible results. We present VOID, a video object removal framework designed to perform physically-plausible inpainting in these complex scenarios. To train the model, we generate a new paired dataset of counterfactual object removals using Kubric and HUMOTO, where removing an object requires altering downstream physical interactions. During inference, a vision-language model identifies regions of the scene affected by the removed object. These regions are then used to guide a video diffusion model that generates physically consistent counterfactual outcomes. Experiments on both synthetic and real data show that our approach better preserves consistent scene dynamics after object removal compared to prior video object removal methods. We hope this framework sheds light on how to make video editing models better simulators of the world through high-level causal reasoning.
Rolling Ahead Diffusion for Traffic Scene Simulation
Feb 13, 2025



Realistic driving simulation requires that NPCs not only mimic natural driving behaviors but also react to the behavior of other simulated agents. Recent developments in diffusion-based scenario generation focus on creating diverse and realistic traffic scenarios by jointly modelling the motion of all the agents in the scene. However, these traffic scenarios do not react when the motion of agents deviates from their modelled trajectories. For example, the ego-agent can be controlled by a stand along motion planner. To produce reactive scenarios with joint scenario models, the model must regenerate the scenario at each timestep based on new observations in a Model Predictive Control (MPC) fashion. Although reactive, this method is time-consuming, as one complete possible future for all NPCs is generated per simulation step. Alternatively, one can utilize an autoregressive model (AR) to predict only the immediate next-step future for all NPCs. Although faster, this method lacks the capability for advanced planning. We present a rolling diffusion based traffic scene generation model which mixes the benefits of both methods by predicting the next step future and simultaneously predicting partially noised further future steps at the same time. We show that such model is efficient compared to diffusion model based AR, achieving a beneficial compromise between reactivity and computational efficiency.
Semantically Consistent Video Inpainting with Conditional Diffusion Models
Apr 30, 2024Current state-of-the-art methods for video inpainting typically rely on optical flow or attention-based approaches to inpaint masked regions by propagating visual information across frames. While such approaches have led to significant progress on standard benchmarks, they struggle with tasks that require the synthesis of novel content that is not present in other frames. In this paper we reframe video inpainting as a conditional generative modeling problem and present a framework for solving such problems with conditional video diffusion models. We highlight the advantages of using a generative approach for this task, showing that our method is capable of generating diverse, high-quality inpaintings and synthesizing new content that is spatially, temporally, and semantically consistent with the provided context.
Trans-Dimensional Generative Modeling via Jump Diffusion Models
May 25, 2023We propose a new class of generative models that naturally handle data of varying dimensionality by jointly modeling the state and dimension of each datapoint. The generative process is formulated as a jump diffusion process that makes jumps between different dimensional spaces. We first define a dimension destroying forward noising process, before deriving the dimension creating time-reversed generative process along with a novel evidence lower bound training objective for learning to approximate it. Simulating our learned approximation to the time-reversed generative process then provides an effective way of sampling data of varying dimensionality by jointly generating state values and dimensions. We demonstrate our approach on molecular and video datasets of varying dimensionality, reporting better compatibility with test-time diffusion guidance imputation tasks and improved interpolation capabilities versus fixed dimensional models that generate state values and dimensions separately.
Visual Chain-of-Thought Diffusion Models
Mar 28, 2023Recent progress with conditional image diffusion models has been stunning, and this holds true whether we are speaking about models conditioned on a text description, a scene layout, or a sketch. Unconditional image diffusion models are also improving but lag behind, as do diffusion models which are conditioned on lower-dimensional features like class labels. We propose to close the gap between conditional and unconditional models using a two-stage sampling procedure. In the first stage we sample an embedding describing the semantic content of the image. In the second stage we sample the image conditioned on this embedding and then discard the embedding. Doing so lets us leverage the power of conditional diffusion models on the unconditional generation task, which we show improves FID by 25-50% compared to standard unconditional generation.
Flexible Diffusion Modeling of Long Videos
May 23, 2022
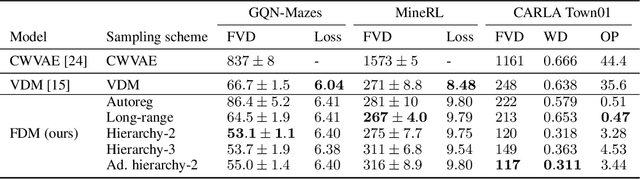

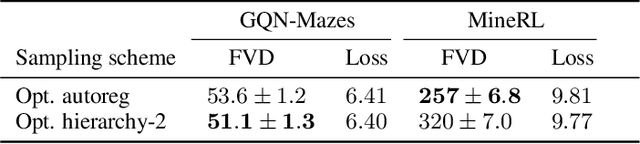
We present a framework for video modeling based on denoising diffusion probabilistic models that produces long-duration video completions in a variety of realistic environments. We introduce a generative model that can at test-time sample any arbitrary subset of video frames conditioned on any other subset and present an architecture adapted for this purpose. Doing so allows us to efficiently compare and optimize a variety of schedules for the order in which frames in a long video are sampled and use selective sparse and long-range conditioning on previously sampled frames. We demonstrate improved video modeling over prior work on a number of datasets and sample temporally coherent videos over 25 minutes in length. We additionally release a new video modeling dataset and semantically meaningful metrics based on videos generated in the CARLA self-driving car simulator.
Image Completion via Inference in Deep Generative Models
Feb 24, 2021
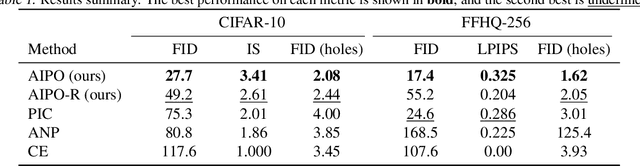
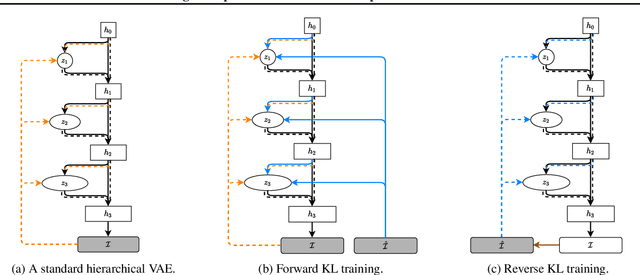

We consider image completion from the perspective of amortized inference in an image generative model. We leverage recent state of the art variational auto-encoder architectures that have been shown to produce photo-realistic natural images at non-trivial resolutions. Through amortized inference in such a model we can train neural artifacts that produce diverse, realistic image completions even when the vast majority of an image is missing. We demonstrate superior sample quality and diversity compared to prior art on the CIFAR-10 and FFHQ-256 datasets. We conclude by describing and demonstrating an application that requires an in-painting model with the capabilities ours exhibits: the use of Bayesian optimal experimental design to select the most informative sequence of small field of view x-rays for chest pathology detection.
Assisting the Adversary to Improve GAN Training
Oct 03, 2020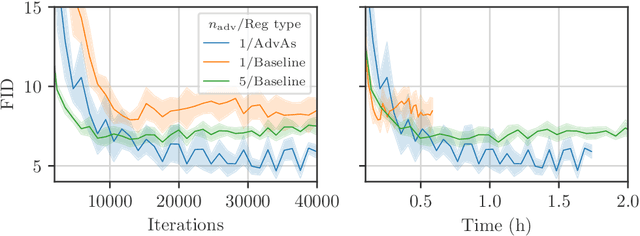
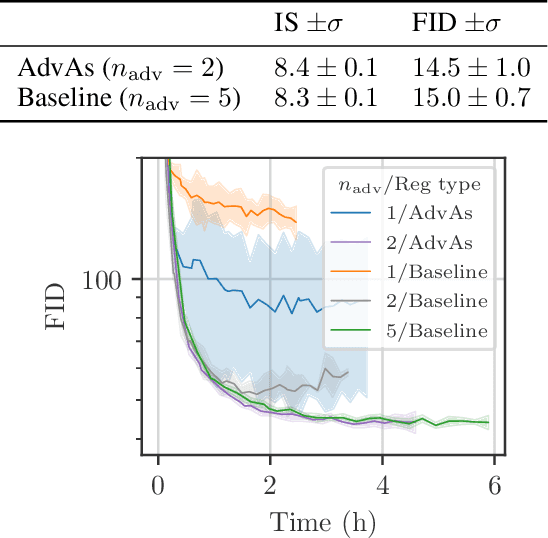
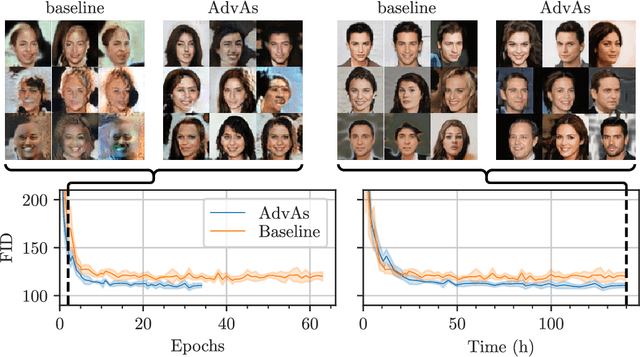

We propose a method for improved training of generative adversarial networks (GANs). Some of the most popular methods for improving the stability and performance of GANs involve constraining or regularizing the discriminator. Our method, on the other hand, involves regularizing the generator. It can be used alongside existing approaches to GAN training and is simple and straightforward to implement. Our method is motivated by a common mismatch between theoretical analysis and practice: analysis often assumes that the discriminator reaches its optimum on each iteration. In practice, this is essentially never true, often leading to poor gradient estimates for the generator. To address this, we introduce the Adversary's Assistant (AdvAs). It is a theoretically motivated penalty imposed on the generator based on the norm of the gradients used to train the discriminator. This encourages the generator to move towards points where the discriminator is optimal. We demonstrate the effect of applying AdvAs to several GAN objectives, datasets and network architectures. The results indicate a reduction in the mismatch between theory and practice and that AdvAs can lead to improvement of GAN training, as measured by FID scores.
Planning as Inference in Epidemiological Models
Apr 03, 2020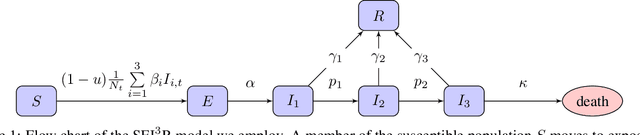
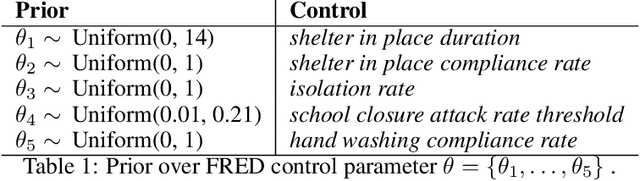
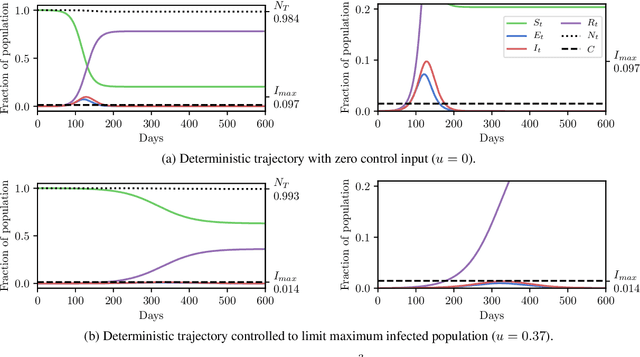
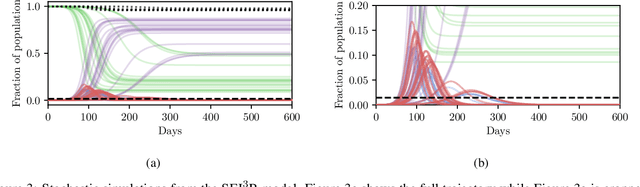
In this work we demonstrate how existing software tools can be used to automate parts of infectious disease-control policy-making via performing inference in existing epidemiological dynamics models. The kind of inference tasks undertaken include computing, for planning purposes, the posterior distribution over putatively controllable, via direct policy-making choices, simulation model parameters that give rise to acceptable disease progression outcomes. Neither the full capabilities of such inference automation software tools nor their utility for planning is widely disseminated at the current time. Timely gains in understanding about these tools and how they can be used may lead to more fine-grained and less economically damaging policy prescriptions, particularly during the current COVID-19 pandemic.
Attention for Inference Compilation
Oct 25, 2019

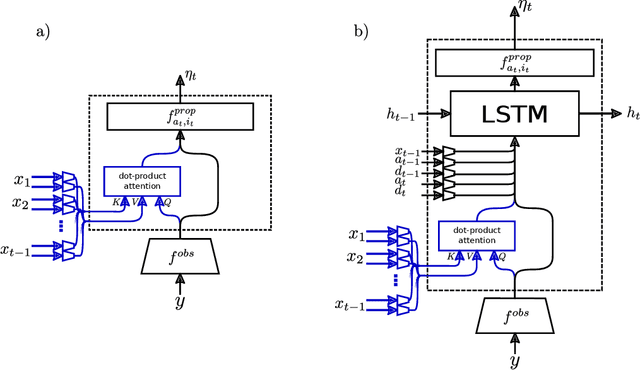
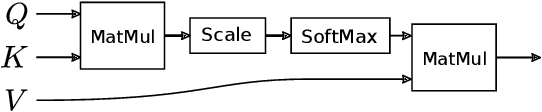
We present a new approach to automatic amortized inference in universal probabilistic programs which improves performance compared to current methods. Our approach is a variation of inference compilation (IC) which leverages deep neural networks to approximate a posterior distribution over latent variables in a probabilistic program. A challenge with existing IC network architectures is that they can fail to model long-range dependencies between latent variables. To address this, we introduce an attention mechanism that attends to the most salient variables previously sampled in the execution of a probabilistic program. We demonstrate that the addition of attention allows the proposal distributions to better match the true posterior, enhancing inference about latent variables in simulators.