 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploration with Multi-Sample Target Values for Distributional Reinforcement Learning
Feb 06, 2022



Distributional reinforcement learning (RL) aims to learn a value-network that predicts the full distribution of the returns for a given state, often modeled via a quantile-based critic. This approach has been successfully integrated into common RL methods for continuous control, giving rise to algorithms such as Distributional Soft Actor-Critic (DSAC). In this paper, we introduce multi-sample target values (MTV) for distributional RL, as a principled replacement for single-sample target value estimation, as commonly employed in current practice. The improved distributional estimates further lend themselves to UCB-based exploration. These two ideas are combined to yield our distributional RL algorithm, E2DC (Extra Exploration with Distributional Critics). We evaluate our approach on a range of continuous control tasks and demonstrate state-of-the-art model-free performance on difficult tasks such as Humanoid control. We provide further insight into the method via visualization and analysis of the learned distributions and their evolution during training.
Semi-supervised Sequential Generative Models
Jun 30, 2020


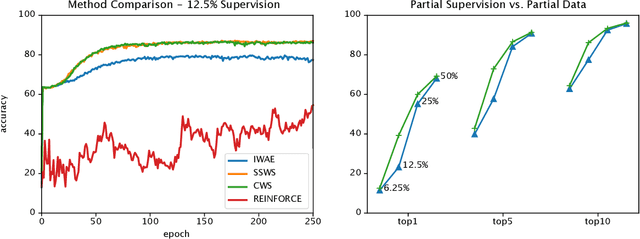
We introduce a novel objective for training deep generative time-series models with discrete latent variables for which supervision is only sparsely available. This instance of semi-supervised learning is challenging for existing methods, because the exponential number of possible discrete latent configurations results in high variance gradient estimators. We first overcome this problem by extending the standard semi-supervised generative modeling objective with reweighted wake-sleep. However, we find that this approach still suffers when the frequency of available labels varies between training sequences. Finally, we introduce a unified objective inspired by teacher-forcing and show that this approach is robust to variable length supervision. We call the resulting method caffeinated wake-sleep (CWS) to emphasize its additional dependence on real data. We demonstrate its effectiveness with experiments on MNIST, handwriting, and fruit fly trajectory data.
Near-Optimal Glimpse Sequences for Improved Hard Attention Neural Network Training
Jun 13, 2019
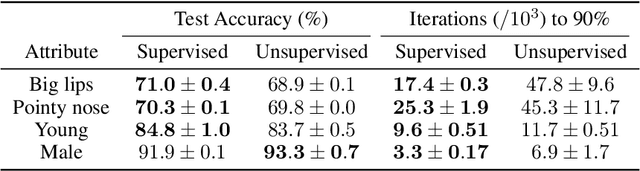
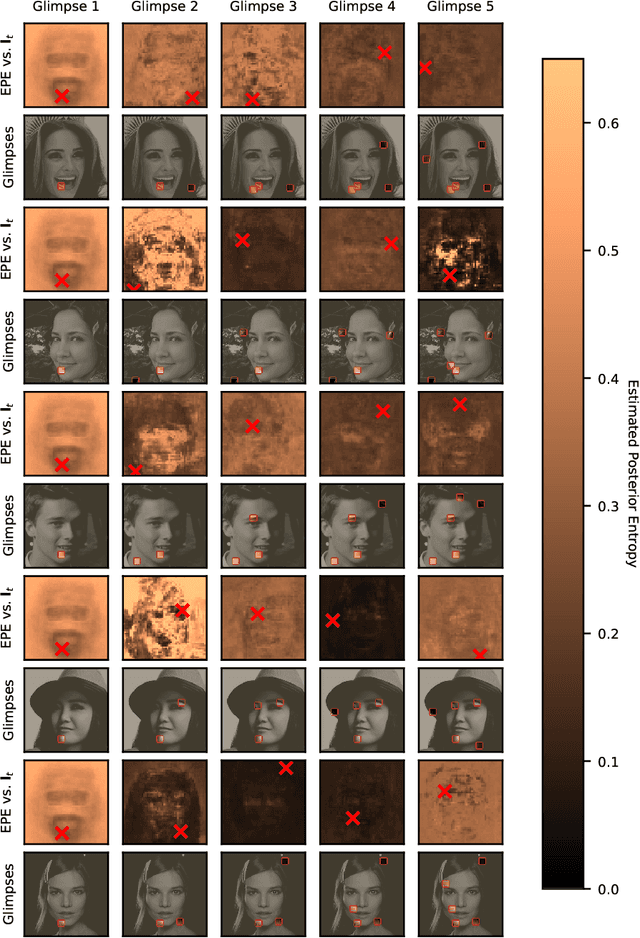
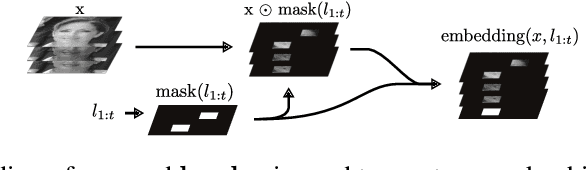
We introduce the use of Bayesian optimal experimental design techniques for generating glimpse sequences to use in semi-supervised training of hard attention networks. Hard attention holds the promise of greater energy efficiency and superior inference performance. Employing such networks for image classification usually involves choosing a sequence of glimpse locations from a stochastic policy. As the outputs of observations are typically non-differentiable with respect to their glimpse locations, unsupervised gradient learning of such a policy requires REINFORCE-style updates. Also, the only reward signal is the final classification accuracy. For these reasons hard attention networks, despite their promise, have not achieved the wide adoption that soft attention networks have and, in many practical settings, are difficult to train. We find that our method for semi-supervised training makes it easier and faster to train hard attention networks and correspondingly could make them practical to consider in situations where they were not before.
Imitation Learning of Factored Multi-agent Reactive Models
Mar 12, 2019

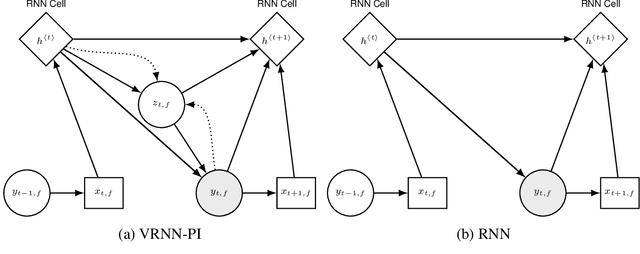
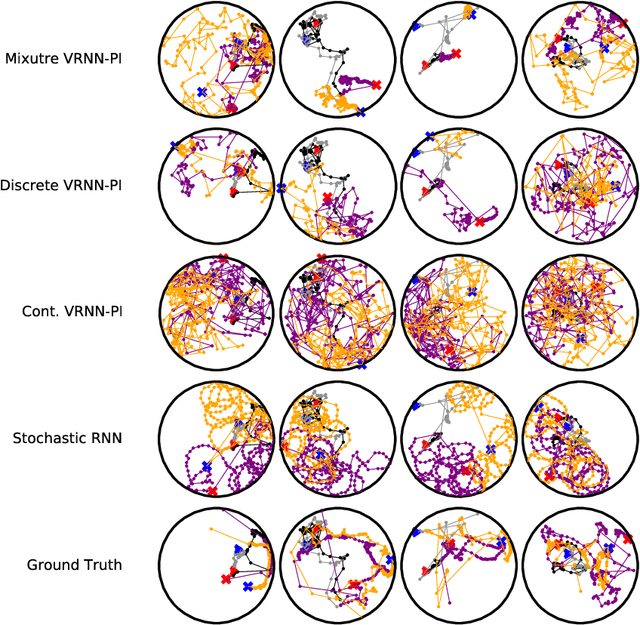
We apply recent advances in deep generative modeling to the task of imitation learning from biological agents. Specifically, we apply variations of the variational recurrent neural network model to a multi-agent setting where we learn policies of individual uncoordinated agents acting based on their perceptual inputs and their hidden belief state. We learn stochastic policies for these agents directly from observational data, without constructing a reward function. An inference network learned jointly with the policy allows for efficient inference over the agent's belief state given a sequence of its current perceptual inputs and the prior actions it performed, which lets us extrapolate observed sequences of behavior into the future while maintaining uncertainty estimates over future trajectories. We test our approach on a dataset of flies interacting in a 2D environment, where we demonstrate better predictive performance than existing approaches which learn deterministic policies with recurrent neural networks. We further show that the uncertainty estimates over future trajectories we obtain are well calibrated, which makes them useful for a variety of downstream processing tasks.
High Throughput Synchronous Distributed Stochastic Gradient Descent
Mar 12, 2018


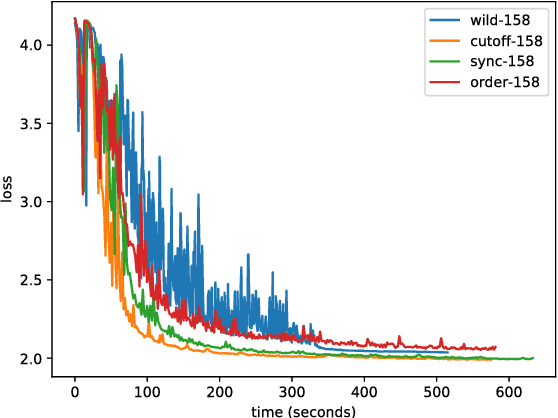
We introduce a new, high-throughput, synchronous, distributed, data-parallel, stochastic-gradient-descent learning algorithm. This algorithm uses amortized inference in a compute-cluster-specific, deep, generative, dynamical model to perform joint posterior predictive inference of the mini-batch gradient computation times of all worker-nodes in a parallel computing cluster. We show that a synchronous parameter server can, by utilizing such a model, choose an optimal cutoff time beyond which mini-batch gradient messages from slow workers are ignored that maximizes overall mini-batch gradient computations per second. In keeping with earlier findings we observe that, under realistic conditions, eagerly discarding the mini-batch gradient computations of stragglers not only increases throughput but actually increases the overall rate of convergence as a function of wall-clock time by virtue of eliminating idleness. The principal novel contribution and finding of this work goes beyond this by demonstrating that using the predicted run-times from a generative model of cluster worker performance to dynamically adjust the cutoff improves substantially over the static-cutoff prior art, leading to, among other things, significantly reduced deep neural net training times on large computer clusters.