 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViDa: Visualizing DNA hybridization trajectories with biophysics-informed deep graph embeddings
Nov 06, 2023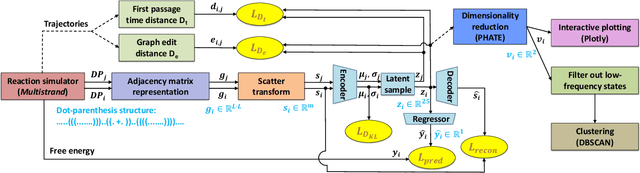

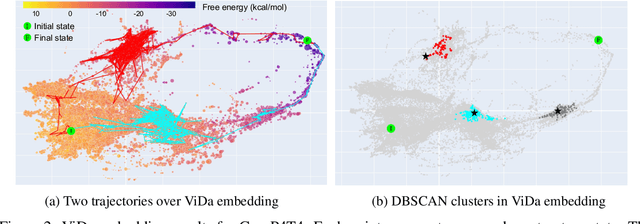

Visualization tools can help synthetic biologists and molecular programmers understand the complex reactive pathways of nucleic acid reactions, which can be designed for many potential applications and can be modelled using a continuous-time Markov chain (CTMC). Here we present ViDa, a new visualization approach for DNA reaction trajectories that uses a 2D embedding of the secondary structure state space underlying the CTMC model. To this end, we integrate a scattering transform of the secondary structure adjacency, a variational autoencoder, and a nonlinear dimensionality reduction method. We augment the training loss with domain-specific supervised terms that capture both thermodynamic and kinetic features. We assess ViDa on two well-studied DNA hybridization reactions. Our results demonstrate that the domain-specific features lead to significant quality improvements over the state-of-the-art in DNA state space visualization, successfully separating different folding pathways and thus providing useful insights into dominant reaction mechanisms.
Planning as Inference in Epidemiological Models
Apr 03, 2020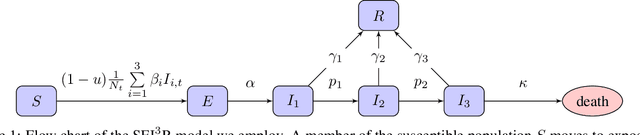
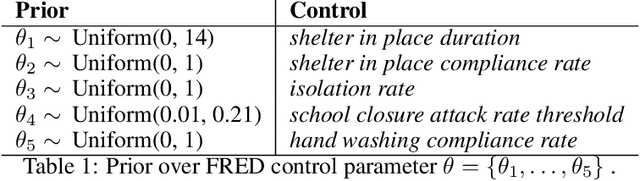
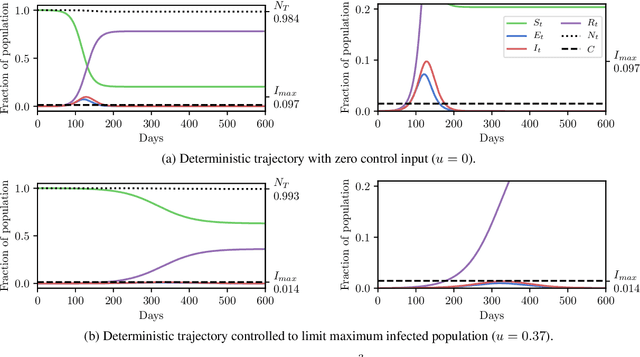
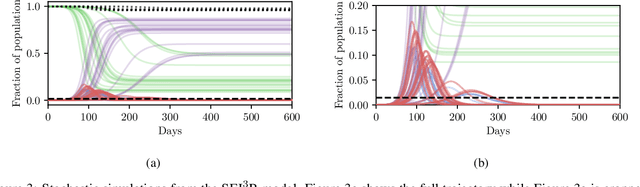
In this work we demonstrate how existing software tools can be used to automate parts of infectious disease-control policy-making via performing inference in existing epidemiological dynamics models. The kind of inference tasks undertaken include computing, for planning purposes, the posterior distribution over putatively controllable, via direct policy-making choices, simulation model parameters that give rise to acceptable disease progression outcomes. Neither the full capabilities of such inference automation software tools nor their utility for planning is widely disseminated at the current time. Timely gains in understanding about these tools and how they can be used may lead to more fine-grained and less economically damaging policy prescriptions, particularly during the current COVID-19 pandemic.
Sparse Variational Inference: Bayesian Coresets from Scratch
Jun 07, 2019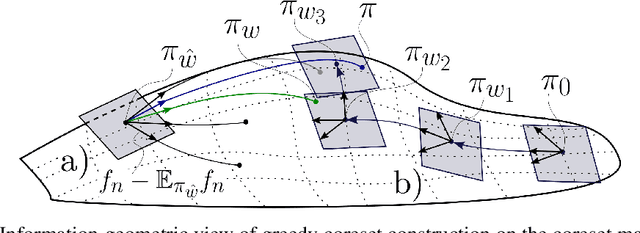
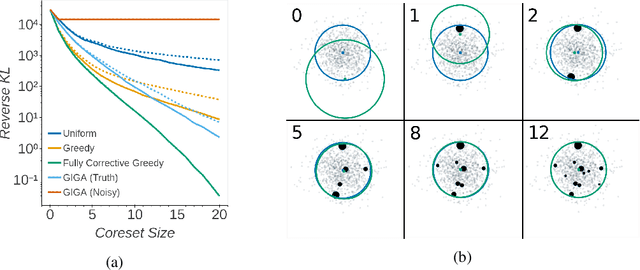
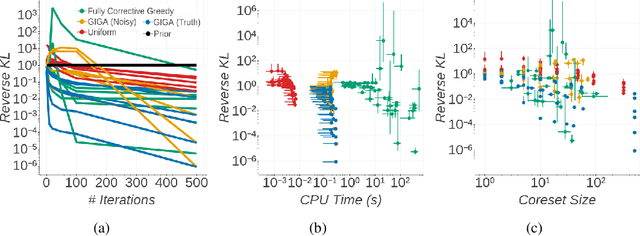
The proliferation of automated inference algorithms in Bayesian statistics has provided practitioners newfound access to fast, reproducible data analysis and powerful statistical models. Designing automated methods that are also both computationally scalable and theoretically sound, however, remains a significant challenge. Recent work on Bayesian coresets takes the approach of compressing the dataset before running a standard inference algorithm, providing both scalability and guarantees on posterior approximation error. But the automation of past coreset methods is limited because they depend on the availability of a reasonable coarse posterior approximation, which is difficult to specify in practice. In the present work we remove this requirement by formulating coreset construction as sparsity-constrained variational inference within an exponential family. This perspective leads to a novel construction via greedy optimization, and also provides a unifying information-geometric view of present and past methods. The proposed Riemannian coreset construction algorithm is fully automated, requiring no inputs aside from the dataset, probabilistic model, desired coreset size, and sample size used for Monte Carlo estimates. In addition to being easier to use than past methods, experiments demonstrate that the proposed algorithm achieves state-of-the-art Bayesian dataset summarization.