 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety through Permissibility: Shield Construction for Fast and Safe Reinforcement Learning
May 29, 2024Designing Reinforcement Learning (RL) solutions for real-life problems remains a significant challenge. A major area of concern is safety. "Shielding" is a popular technique to enforce safety in RL by turning user-defined safety specifications into safe agent behavior. However, these methods either suffer from extreme learning delays, demand extensive human effort in designing models and safe domains in the problem, or require pre-computation. In this paper, we propose a new permissibility-based framework to deal with safety and shield construction. Permissibility was originally designed for eliminating (non-permissible) actions that will not lead to an optimal solution to improve RL training efficiency. This paper shows that safety can be naturally incorporated into this framework, i.e. extending permissibility to include safety, and thereby we can achieve both safety and improved efficiency. Experimental evaluation using three standard RL applications shows the effectiveness of the approach.
Semantic Novelty Detection and Characterization in Factual Text Involving Named Entities
Oct 31, 2022

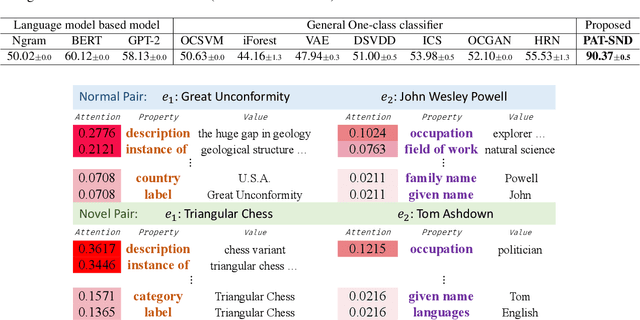
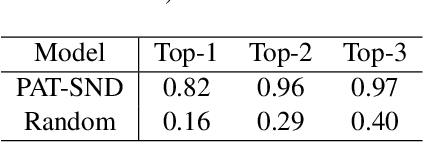
Much of the existing work on text novelty detection has been studied at the topic level, i.e., identifying whether the topic of a document or a sentence is novel or not. Little work has been done at the fine-grained semantic level (or contextual level). For example, given that we know Elon Musk is the CEO of a technology company, the sentence "Elon Musk acted in the sitcom The Big Bang Theory" is novel and surprising because normally a CEO would not be an actor. Existing topic-based novelty detection methods work poorly on this problem because they do not perform semantic reasoning involving relations between named entities in the text and their background knowledge. This paper proposes an effective model (called PAT-SND) to solve the problem, which can also characterize the novelty. An annotated dataset is also created. Evaluation shows that PAT-SND outperforms 10 baselines by large margins.
Assessing Graph-based Deep Learning Models for Predicting Flash Point
Feb 26, 2020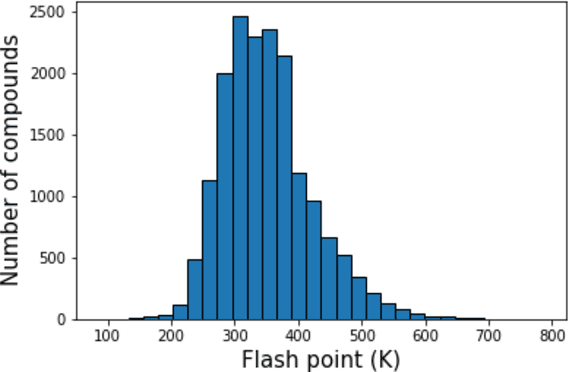
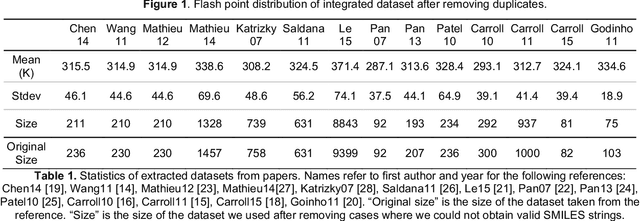
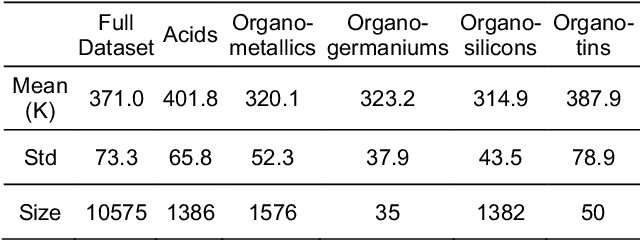
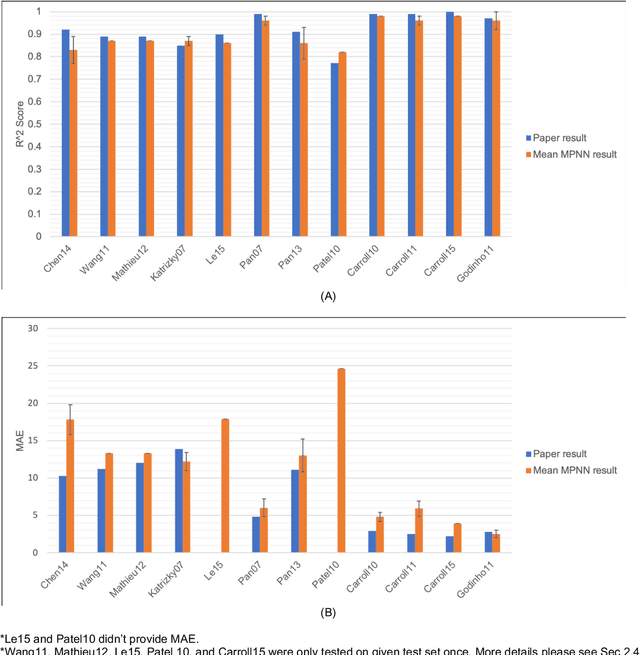
Flash points of organic molecules play an important role in preventing flammability hazards and large databases of measured values exist, although millions of compounds remain unmeasured. To rapidly extend existing data to new compounds many researchers have used quantitative structure-property relationship (QSPR) analysis to effectively predict flash points. In recent years graph-based deep learning (GBDL) has emerged as a powerful alternative method to traditional QSPR. In this paper, GBDL models were implemented in predicting flash point for the first time. We assessed the performance of two GBDL models, message-passing neural network (MPNN) and graph convolutional neural network (GCNN), by comparing methods. Our result shows that MPNN both outperforms GCNN and yields slightly worse but comparable performance with previous QSPR studies. The average R2 and Mean Absolute Error (MAE) scores of MPNN are, respectively, 2.3% lower and 2.0 K higher than previous comparable studies. To further explore GBDL models, we collected the largest flash point dataset to date, which contains 10575 unique molecules. The optimized MPNN gives a test data R2 of 0.803 and MAE of 17.8 K on the complete dataset. We also extracted 5 datasets from our integrated dataset based on molecular types (acids, organometallics, organogermaniums, organosilicons, and organotins) and explore the quality of the model in these classes.against 12 previous QSPR studies using more traditional
* 26 pages, 6 tabels, 3 figures