 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Novelty Detection and Characterization in Factual Text Involving Named Entities
Oct 31, 2022

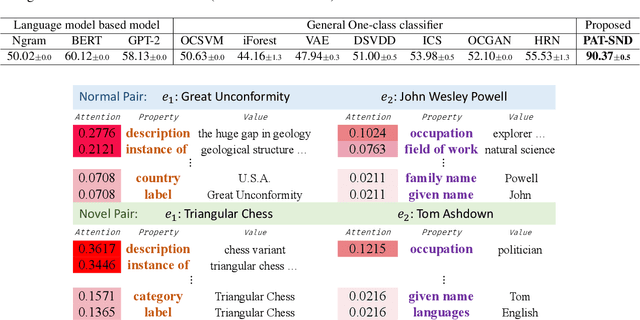
Much of the existing work on text novelty detection has been studied at the topic level, i.e., identifying whether the topic of a document or a sentence is novel or not. Little work has been done at the fine-grained semantic level (or contextual level). For example, given that we know Elon Musk is the CEO of a technology company, the sentence "Elon Musk acted in the sitcom The Big Bang Theory" is novel and surprising because normally a CEO would not be an actor. Existing topic-based novelty detection methods work poorly on this problem because they do not perform semantic reasoning involving relations between named entities in the text and their background knowledge. This paper proposes an effective model (called PAT-SND) to solve the problem, which can also characterize the novelty. An annotated dataset is also created. Evaluation shows that PAT-SND outperforms 10 baselines by large margins.
Achieving Forgetting Prevention and Knowledge Transfer in Continual Learning
Dec 05, 2021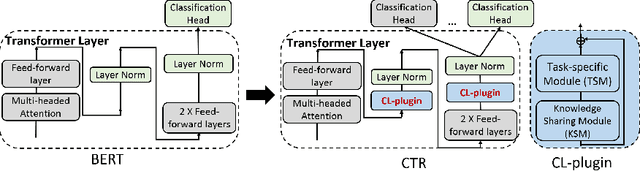
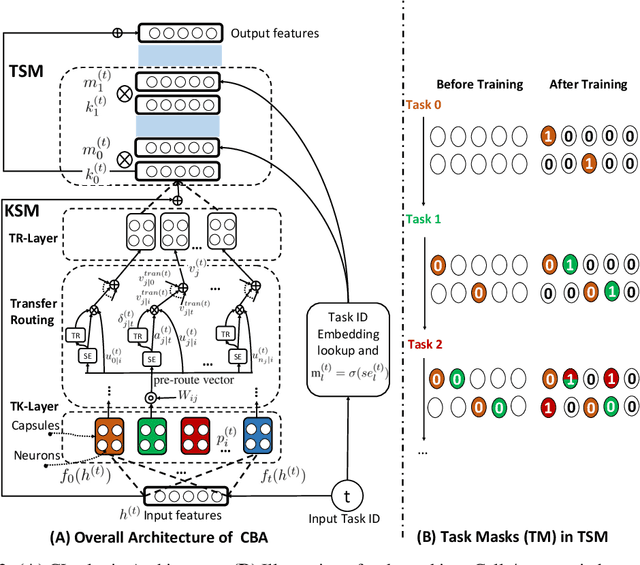
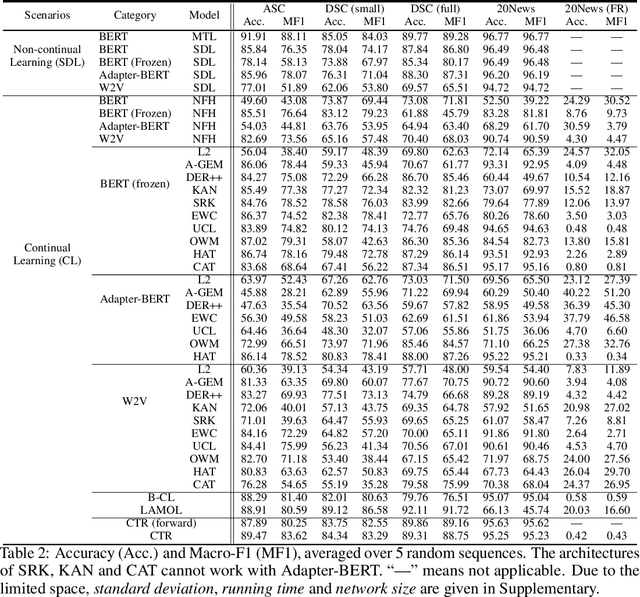
Continual learning (CL) learns a sequence of tasks incrementally with the goal of achieving two main objectives: overcoming catastrophic forgetting (CF) and encouraging knowledge transfer (KT) across tasks. However, most existing techniques focus only on overcoming CF and have no mechanism to encourage KT, and thus do not do well in KT. Although several papers have tried to deal with both CF and KT, our experiments show that they suffer from serious CF when the tasks do not have much shared knowledge. Another observation is that most current CL methods do not use pre-trained models, but it has been shown that such models can significantly improve the end task performance. For example, in natural language processing, fine-tuning a BERT-like pre-trained language model is one of the most effective approaches. However, for CL, this approach suffers from serious CF. An interesting question is how to make the best use of pre-trained models for CL. This paper proposes a novel model called CTR to solve these problems. Our experimental results demonstrate the effectiveness of CTR
Lifelong and Interactive Learning of Factual Knowledge in Dialogues
Jul 31, 2019
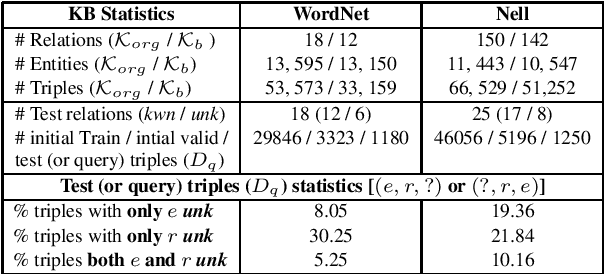
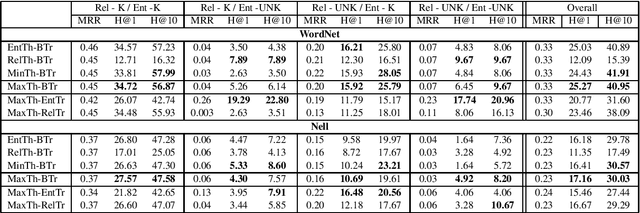
Dialogue systems are increasingly using knowledge bases (KBs) storing real-world facts to help generate quality responses. However, as the KBs are inherently incomplete and remain fixed during conversation, it limits dialogue systems' ability to answer questions and to handle questions involving entities or relations that are not in the KB. In this paper, we make an attempt to propose an engine for Continuous and Interactive Learning of Knowledge (CILK) for dialogue systems to give them the ability to continuously and interactively learn and infer new knowledge during conversations. With more knowledge accumulated over time, they will be able to learn better and answer more questions. Our empirical evaluation shows that CILK is promising.
Forward and Backward Knowledge Transfer for Sentiment Classification
Jun 08, 2019
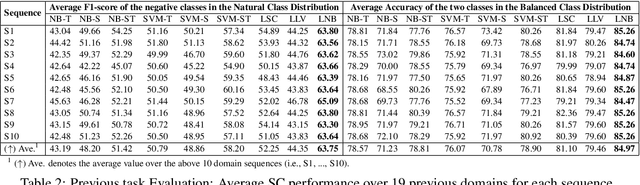
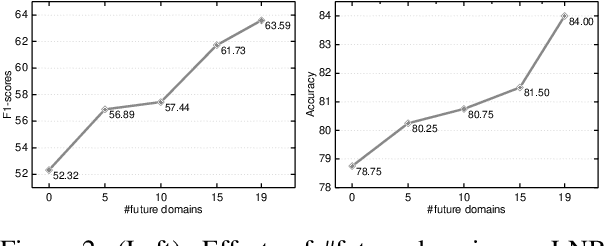
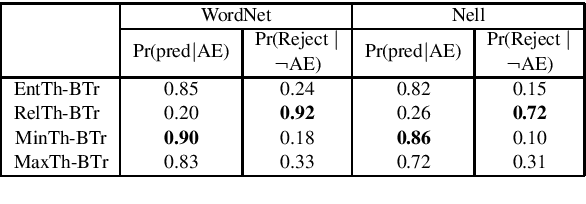
This paper studies the problem of learning a sequence of sentiment classification tasks. The learned knowledge from each task is retained and used to help future or subsequent task learning. This learning paradigm is called Lifelong Learning (LL). However, existing LL methods either only transfer knowledge forward to help future learning and do not go back to improve the model of a previous task or require the training data of the previous task to retrain its model to exploit backward/reverse knowledge transfer. This paper studies reverse knowledge transfer of LL in the context of naive Bayesian (NB) classification. It aims to improve the model of a previous task by leveraging future knowledge without retraining using its training data. This is done by exploiting a key characteristic of the generative model of NB. That is, it is possible to improve the NB classifier for a task by improving its model parameters directly by using the retained knowledge from other tasks. Experimental results show that the proposed method markedly outperforms existing LL baselines.
Towards a Continuous Knowledge Learning Engine for Chatbots
Feb 24, 2018
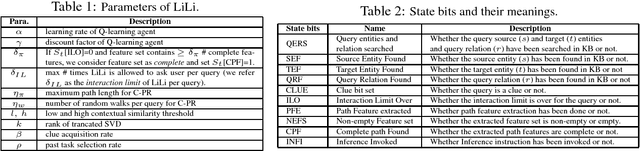

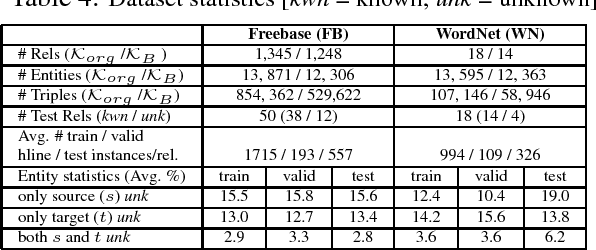
Although chatbots have been very popular in recent years, they still have some serious weaknesses which limit the scope of their applications. One major weakness is that they cannot learn new knowledge during the conversation process, i.e., their knowledge is fixed beforehand and cannot be expanded or updated during conversation. In this paper, we propose to build a general knowledge learning engine for chatbots to enable them to continuously and interactively learn new knowledge during conversations. As time goes by, they become more and more knowledgeable and better and better at learning and conversation. We model the task as an open-world knowledge base completion problem and propose a novel technique called lifelong interactive learning and inference (LiLi) to solve it. LiLi works by imitating how humans acquire knowledge and perform inference during an interactive conversation. Our experimental results show LiLi is highly promising.
Lifelong Learning for Sentiment Classification
Jan 09, 2018
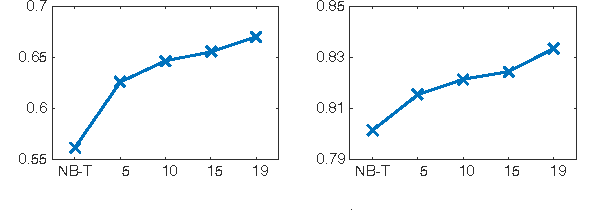

This paper proposes a novel lifelong learning (LL) approach to sentiment classification. LL mimics the human continuous learning process, i.e., retaining the knowledge learned from past tasks and use it to help future learning. In this paper, we first discuss LL in general and then LL for sentiment classification in particular. The proposed LL approach adopts a Bayesian optimization framework based on stochastic gradient descent. Our experimental results show that the proposed method outperforms baseline methods significantly, which demonstrates that lifelong learning is a promising research direction.