 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Data Aware Neural Architecture Search via Supernet Accelerated Evaluation
Feb 18, 2025



Tiny machine learning (TinyML) promises to revolutionize fields such as healthcare, environmental monitoring, and industrial maintenance by running machine learning models on low-power embedded systems. However, the complex optimizations required for successful TinyML deployment continue to impede its widespread adoption. A promising route to simplifying TinyML is through automatic machine learning (AutoML), which can distill elaborate optimization workflows into accessible key decisions. Notably, Hardware Aware Neural Architecture Searches - where a computer searches for an optimal TinyML model based on predictive performance and hardware metrics - have gained significant traction, producing some of today's most widely used TinyML models. Nevertheless, limiting optimization solely to neural network architectures can prove insufficient. Because TinyML systems must operate under extremely tight resource constraints, the choice of input data configuration, such as resolution or sampling rate, also profoundly impacts overall system efficiency. Achieving truly optimal TinyML systems thus requires jointly tuning both input data and model architecture. Despite its importance, this "Data Aware Neural Architecture Search" remains underexplored. To address this gap, we propose a new state-of-the-art Data Aware Neural Architecture Search technique and demonstrate its effectiveness on the novel TinyML ``Wake Vision'' dataset. Our experiments show that across varying time and hardware constraints, Data Aware Neural Architecture Search consistently discovers superior TinyML systems compared to purely architecture-focused methods, underscoring the critical role of data-aware optimization in advancing TinyML.
EdgeMark: An Automation and Benchmarking System for Embedded Artificial Intelligence Tools
Feb 03, 2025The integration of artificial intelligence (AI) into embedded devices, a paradigm known as embedded artificial intelligence (eAI) or tiny machine learning (TinyML), is transforming industries by enabling intelligent data processing at the edge. However, the many tools available in this domain leave researchers and developers wondering which one is best suited to their needs. This paper provides a review of existing eAI tools, highlighting their features, trade-offs, and limitations. Additionally, we introduce EdgeMark, an open-source automation system designed to streamline the workflow for deploying and benchmarking machine learning (ML) models on embedded platforms. EdgeMark simplifies model generation, optimization, conversion, and deployment while promoting modularity, reproducibility, and scalability. Experimental benchmarking results showcase the performance of widely used eAI tools, including TensorFlow Lite Micro (TFLM), Edge Impulse, Ekkono, and Renesas eAI Translator, across a wide range of models, revealing insights into their relative strengths and weaknesses. The findings provide guidance for researchers and developers in selecting the most suitable tools for specific application requirements, while EdgeMark lowers the barriers to adoption of eAI technologies.
Wake Vision: A Large-scale, Diverse Dataset and Benchmark Suite for TinyML Person Detection
May 01, 2024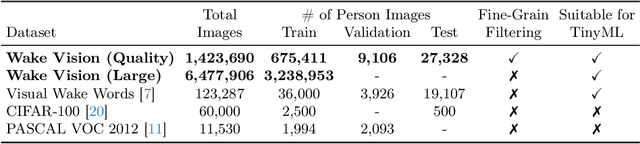



Machine learning applications on extremely low-power devices, commonly referred to as tiny machine learning (TinyML), promises a smarter and more connected world. However, the advancement of current TinyML research is hindered by the limited size and quality of pertinent datasets. To address this challenge, we introduce Wake Vision, a large-scale, diverse dataset tailored for person detection -- the canonical task for TinyML visual sensing. Wake Vision comprises over 6 million images, which is a hundredfold increase compared to the previous standard, and has undergone thorough quality filtering. Using Wake Vision for training results in a 2.41\% increase in accuracy compared to the established benchmark. Alongside the dataset, we provide a collection of five detailed benchmark sets that assess model performance on specific segments of the test data, such as varying lighting conditions, distances from the camera, and demographic characteristics of subjects. These novel fine-grained benchmarks facilitate the evaluation of model quality in challenging real-world scenarios that are often ignored when focusing solely on overall accuracy. Through an evaluation of a MobileNetV2 TinyML model on the benchmarks, we show that the input resolution plays a more crucial role than the model width in detecting distant subjects and that the impact of quantization on model robustness is minimal, thanks to the dataset quality. These findings underscore the importance of a detailed evaluation to identify essential factors for model development. The dataset, benchmark suite, code, and models are publicly available under the CC-BY 4.0 license, enabling their use for commercial use cases.
A Centralized Reinforcement Learning Framework for Adaptive Clustering with Low Control Overhead in IoT Networks
Jan 28, 2024



Wireless Sensor Networks (WSNs) play a pivotal role in enabling Internet of Things (IoT) devices with sensing and actuation capabilities. Operating in remote and resource-constrained environments, these IoT devices face challenges related to energy consumption, crucial for network longevity. Clustering protocols have emerged as an effective solution to alleviate energy burdens on IoT devices. This paper introduces Low-Energy Adaptive Clustering Hierarchy with Reinforcement Learning-based Controller (LEACH-RLC), a novel clustering protocol that employs a Mixed Integer Linear Programming (MILP) for strategic selection of cluster heads (CHs) and node-to-cluster assignments. Additionally, it integrates a Reinforcement Learning (RL) agent to minimize control overhead by learning optimal timings for generating new clusters. Addressing key research questions, LEACH-RLC seeks to balance control overhead reduction without compromising overall network performance. Through extensive simulations, this paper investigates the frequency and opportune moments for generating new clustering solutions. Results demonstrate the superior performance of LEACH-RLC over conventional LEACH and LEACH-C, showcasing enhanced network lifetime, reduced average energy consumption, and minimized control overhead. The proposed protocol contributes to advancing the efficiency and adaptability of WSNs, addressing critical challenges in IoT deployments.
Data Aware Neural Architecture Search
Apr 04, 2023Neural Architecture Search (NAS) is a popular tool for automatically generating Neural Network (NN) architectures. In early NAS works, these tools typically optimized NN architectures for a single metric, such as accuracy. However, in the case of resource constrained Machine Learning, one single metric is not enough to evaluate a NN architecture. For example, a NN model achieving a high accuracy is not useful if it does not fit inside the flash memory of a given system. Therefore, recent works on NAS for resource constrained systems have investigated various approaches to optimize for multiple metrics. In this paper, we propose that, on top of these approaches, it could be beneficial for NAS optimization of resource constrained systems to also consider input data granularity. We name such a system "Data Aware NAS", and we provide experimental evidence of its benefits by comparing it to traditional NAS.
Towards Federated Learning: Robustness Analytics to Data Heterogeneity
Feb 12, 2020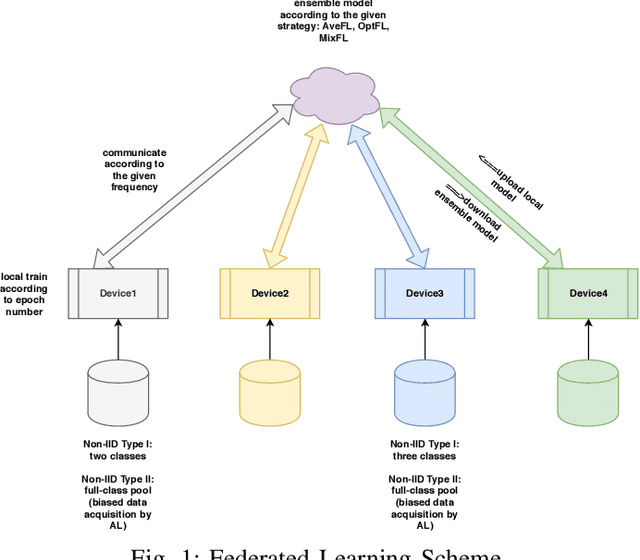
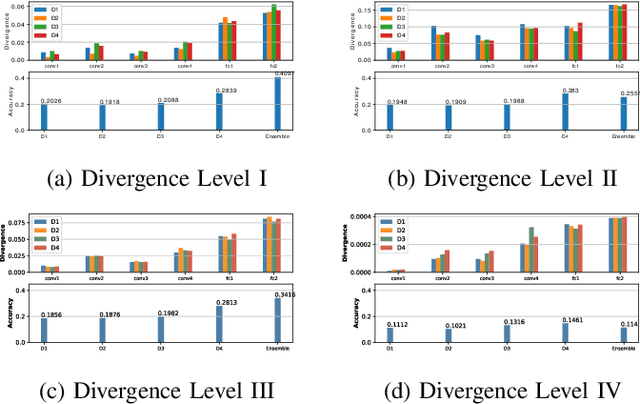
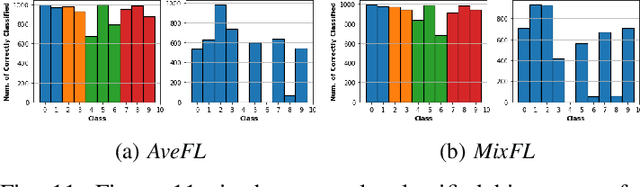
Federated Learning allows remote centralized server training models without to access the data stored in distributed (edge) devices. Most work assume the data generated from edge devices is identically and independently sampled from a common population distribution. However, such ideal sampling may not be realistic in many contexts where edge devices correspond to units in variable context. Also, models based on intrinsic agency, such as active sampling schemes, may lead to highly biased sampling. So an imminent question is how robust Federated Learning is to biased sampling? In this work, we investigate two such scenarios. First, we study Federated Learning of a classifier from data with edge device class distribution heterogeneity. Second, we study Federated Learning of a classifier with active sampling at the edge. We present evidence in both scenarios, that federated learning is robust to data heterogeneity.