 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst Logit Boosting: Visual Grounding Method to Mitigate Object Hallucination in Large Vision-Language Models
Apr 01, 2026Recent Large Vision-Language Models (LVLMs) have demonstrated remarkable performance across various multimodal tasks that require understanding both visual and linguistic inputs. However, object hallucination -- the generation of nonexistent objects in answers -- remains a persistent challenge. Although several approaches such as retraining and external grounding methods have been proposed to mitigate this issue, they still suffer from high data costs or structural complexity. Training-free methods such as Contrastive Decoding (CD) are more cost-effective, avoiding additional training or external models, but still suffer from long-term decay, where visual grounding weakens and language priors dominate as the generation progresses. In this paper, we propose First Logit Boosting (FLB), a simple yet effective training-free technique designed to alleviate long-term decay in LVLMs. FLB stores the logit of the first generated token and adds it to subsequent token predictions, effectively mitigating long-term decay of visual information. We observe that FLB (1) sustains the visual information embedded in the first token throughout generation, and (2) suppresses hallucinated words through the stabilizing effect of the ``The'' token. Experimental results show that FLB significantly reduces object hallucination across various tasks, benchmarks, and backbone models. Notably, it causes negligible inference overhead, making it highly applicable to real-time multimodal systems. Code is available at https://github.com/jiwooha20/FLB
AROMMA: Unifying Olfactory Embeddings for Single Molecules and Mixtures
Jan 27, 2026Public olfaction datasets are small and fragmented across single molecules and mixtures, limiting learning of generalizable odor representations. Recent works either learn single-molecule embeddings or address mixtures via similarity or pairwise label prediction, leaving representations separate and unaligned. In this work, we propose AROMMA, a framework that learns a unified embedding space for single molecules and two-molecule mixtures. Each molecule is encoded by a chemical foundation model and the mixtures are composed by an attention-based aggregator, ensuring both permutation invariance and asymmetric molecular interactions. We further align odor descriptor sets using knowledge distillation and class-aware pseudo-labeling to enrich missing mixture annotations. AROMMA achieves state-of-the-art performance in both single-molecule and molecule-pair datasets, with up to 19.1% AUROC improvement, demonstrating a robust generalization in two domains.
Universal Auto-encoder Framework for MIMO CSI Feedback
Mar 01, 2024Existing auto-encoder (AE)-based channel state information (CSI) frameworks have focused on a specific configuration of user equipment (UE) and base station (BS), and thus the input and output sizes of the AE are fixed. However, in the real-world scenario, the input and output sizes may vary depending on the number of antennas of the BS and UE and the allocated resource block in the frequency dimension. A naive approach to support the different input and output sizes is to use multiple AE models, which is impractical for the UE due to the limited HW resources. In this paper, we propose a universal AE framework that can support different input sizes and multiple compression ratios. The proposed AE framework significantly reduces the HW complexity while providing comparable performance in terms of compression ratio-distortion trade-off compared to the naive and state-of-the-art approaches.
FedSpace: An Efficient Federated Learning Framework at Satellites and Ground Stations
Feb 02, 2022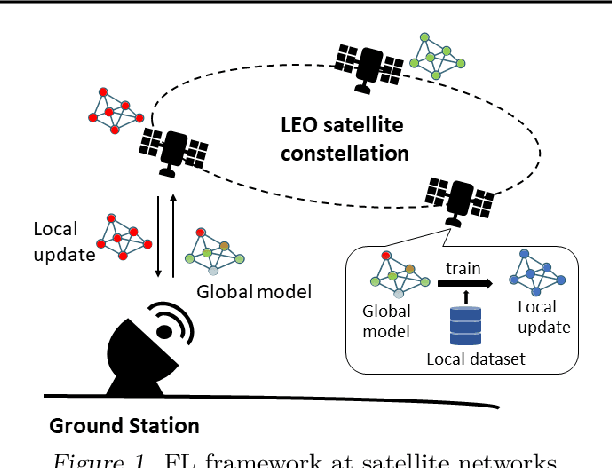

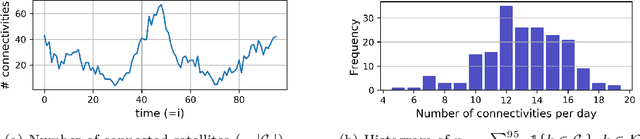

Large-scale deployments of low Earth orbit (LEO) satellites collect massive amount of Earth imageries and sensor data, which can empower machine learning (ML) to address global challenges such as real-time disaster navigation and mitigation. However, it is often infeasible to download all the high-resolution images and train these ML models on the ground because of limited downlink bandwidth, sparse connectivity, and regularization constraints on the imagery resolution. To address these challenges, we leverage Federated Learning (FL), where ground stations and satellites collaboratively train a global ML model without sharing the captured images on the satellites. We show fundamental challenges in applying existing FL algorithms among satellites and ground stations, and we formulate an optimization problem which captures a unique trade-off between staleness and idleness. We propose a novel FL framework, named FedSpace, which dynamically schedules model aggregation based on the deterministic and time-varying connectivity according to satellite orbits. Extensive numerical evaluations based on real-world satellite images and satellite networks show that FedSpace reduces the training time by 1.7 days (38.6%) over the state-of-the-art FL algorithms.
Secure Aggregation for Buffered Asynchronous Federated Learning
Oct 05, 2021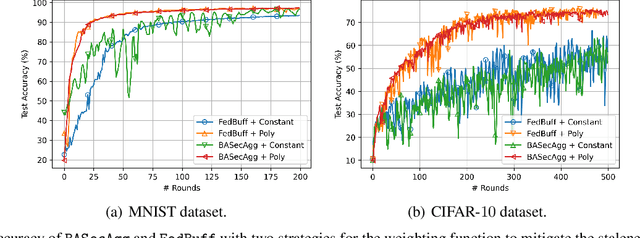
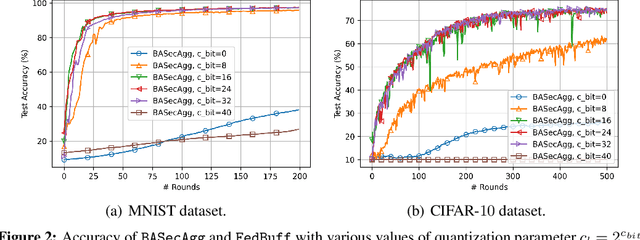
Federated learning (FL) typically relies on synchronous training, which is slow due to stragglers. While asynchronous training handles stragglers efficiently, it does not ensure privacy due to the incompatibility with the secure aggregation protocols. A buffered asynchronous training protocol known as FedBuff has been proposed recently which bridges the gap between synchronous and asynchronous training to mitigate stragglers and to also ensure privacy simultaneously. FedBuff allows the users to send their updates asynchronously while ensuring privacy by storing the updates in a trusted execution environment (TEE) enabled private buffer. TEEs, however, have limited memory which limits the buffer size. Motivated by this limitation, we develop a buffered asynchronous secure aggregation (BASecAgg) protocol that does not rely on TEEs. The conventional secure aggregation protocols cannot be applied in the buffered asynchronous setting since the buffer may have local models corresponding to different rounds and hence the masks that the users use to protect their models may not cancel out. BASecAgg addresses this challenge by carefully designing the masks such that they cancel out even if they correspond to different rounds. Our convergence analysis and experiments show that BASecAgg almost has the same convergence guarantees as FedBuff without relying on TEEs.
LightSecAgg: Rethinking Secure Aggregation in Federated Learning
Sep 29, 2021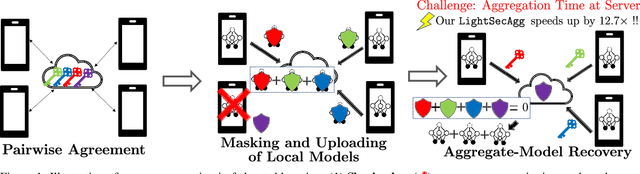
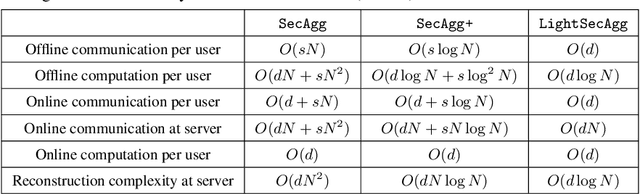
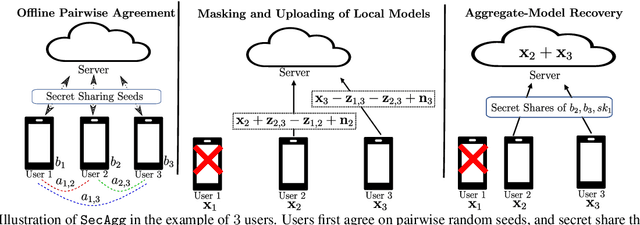
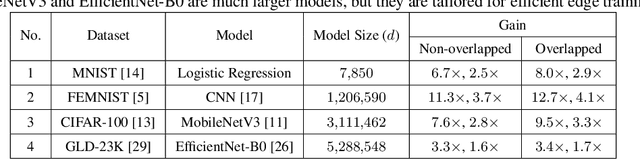
Secure model aggregation is a key component of federated learning (FL) that aims at protecting the privacy of each user's individual model, while allowing their global aggregation. It can be applied to any aggregation-based approaches, including algorithms for training a global model, as well as personalized FL frameworks. Model aggregation needs to also be resilient to likely user dropouts in FL system, making its design substantially more complex. State-of-the-art secure aggregation protocols essentially rely on secret sharing of the random-seeds that are used for mask generations at the users, in order to enable the reconstruction and cancellation of those belonging to dropped users. The complexity of such approaches, however, grows substantially with the number of dropped users. We propose a new approach, named LightSecAgg, to overcome this bottleneck by turning the focus from "random-seed reconstruction of the dropped users" to "one-shot aggregate-mask reconstruction of the active users". More specifically, in LightSecAgg each user protects its local model by generating a single random mask. This mask is then encoded and shared to other users, in such a way that the aggregate-mask of any sufficiently large set of active users can be reconstructed directly at the server via encoded masks. We show that LightSecAgg achieves the same privacy and dropout-resiliency guarantees as the state-of-the-art protocols, while significantly reducing the overhead for resiliency to dropped users. Furthermore, our system optimization helps to hide the runtime cost of offline processing by parallelizing it with model training. We evaluate LightSecAgg via extensive experiments for training diverse models on various datasets in a realistic FL system, and demonstrate that LightSecAgg significantly reduces the total training time, achieving a performance gain of up to $12.7\times$ over baselines.
Securing Secure Aggregation: Mitigating Multi-Round Privacy Leakage in Federated Learning
Jun 07, 2021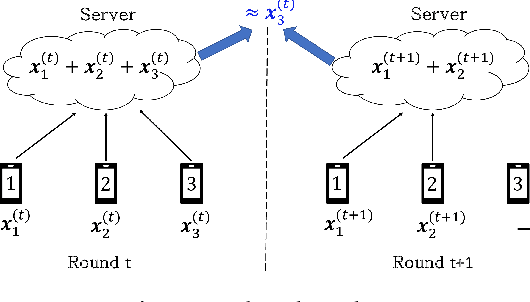
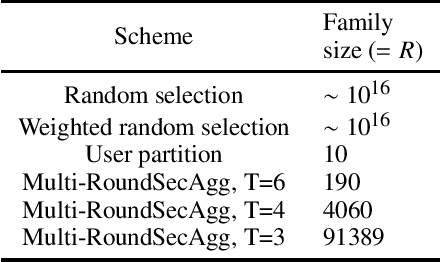
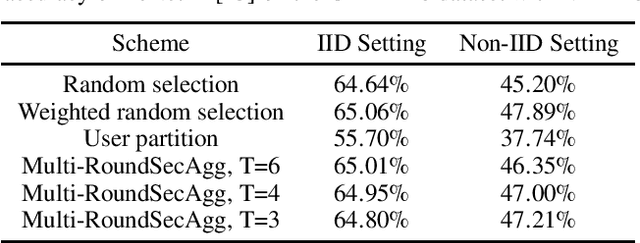
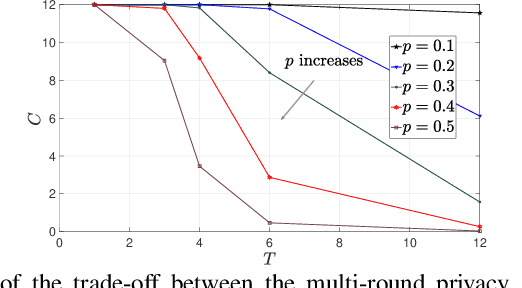
Secure aggregation is a critical component in federated learning, which enables the server to learn the aggregate model of the users without observing their local models. Conventionally, secure aggregation algorithms focus only on ensuring the privacy of individual users in a single training round. We contend that such designs can lead to significant privacy leakages over multiple training rounds, due to partial user selection/participation at each round of federated learning. In fact, we empirically show that the conventional random user selection strategies for federated learning lead to leaking users' individual models within number of rounds linear in the number of users. To address this challenge, we introduce a secure aggregation framework with multi-round privacy guarantees. In particular, we introduce a new metric to quantify the privacy guarantees of federated learning over multiple training rounds, and develop a structured user selection strategy that guarantees the long-term privacy of each user (over any number of training rounds). Our framework also carefully accounts for the fairness and the average number of participating users at each round. We perform several experiments on MNIST and CIFAR-10 datasets in the IID and the non-IID settings to demonstrate the performance improvement over the baseline algorithms, both in terms of privacy protection and test accuracy.
On Polynomial Approximations for Privacy-Preserving and Verifiable ReLU Networks
Nov 11, 2020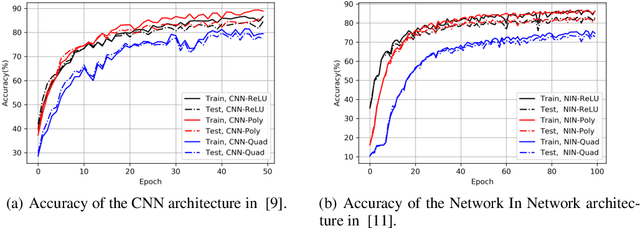
Outsourcing neural network inference tasks to an untrusted cloud raises data privacy and integrity concerns. In order to address these challenges, several privacy-preserving and verifiable inference techniques have been proposed based on replacing the non-polynomial activation functions such as the rectified linear unit (ReLU) function with polynomial activation functions. Such techniques usually require the polynomial coefficients to be in a finite field. Motivated by such requirements, several works proposed replacing the ReLU activation function with the square activation function. In this work, we empirically show that the square function is not the best second-degree polynomial that can replace the ReLU function in deep neural networks. We instead propose a second-degree polynomial activation function with a first order term and empirically show that it can lead to much better models. Our experiments on the CIFAR-$10$ dataset show that our proposed polynomial activation function significantly outperforms the square activation function.
A Scalable Approach for Privacy-Preserving Collaborative Machine Learning
Nov 03, 2020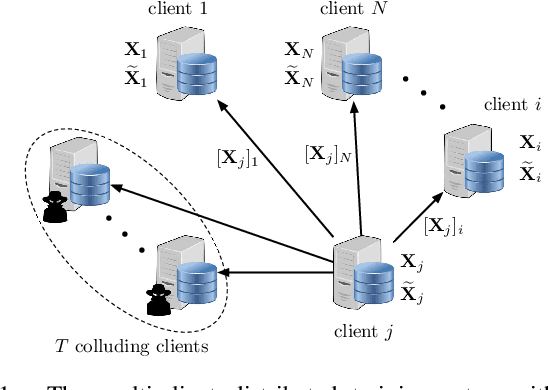

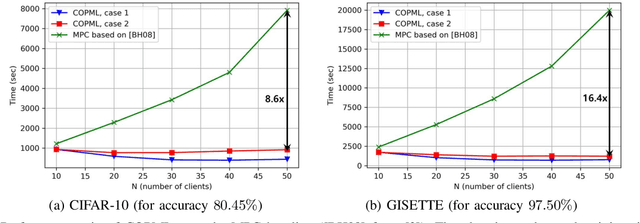
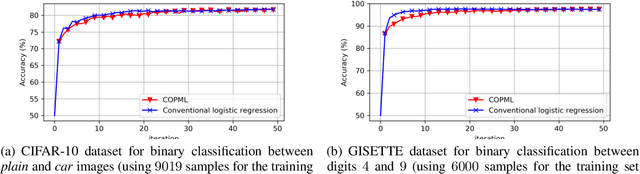
We consider a collaborative learning scenario in which multiple data-owners wish to jointly train a logistic regression model, while keeping their individual datasets private from the other parties. We propose COPML, a fully-decentralized training framework that achieves scalability and privacy-protection simultaneously. The key idea of COPML is to securely encode the individual datasets to distribute the computation load effectively across many parties and to perform the training computations as well as the model updates in a distributed manner on the securely encoded data. We provide the privacy analysis of COPML and prove its convergence. Furthermore, we experimentally demonstrate that COPML can achieve significant speedup in training over the benchmark protocols. Our protocol provides strong statistical privacy guarantees against colluding parties (adversaries) with unbounded computational power, while achieving up to $16\times$ speedup in the training time against the benchmark protocols.
FedML: A Research Library and Benchmark for Federated Machine Learning
Jul 27, 2020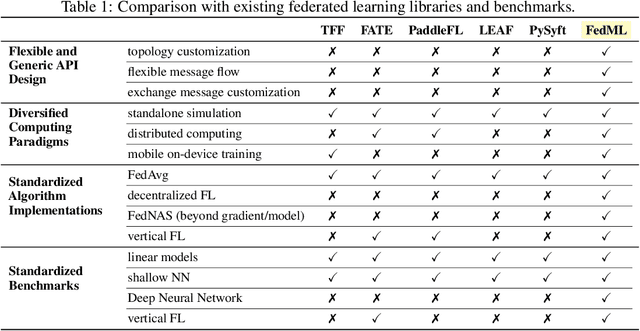
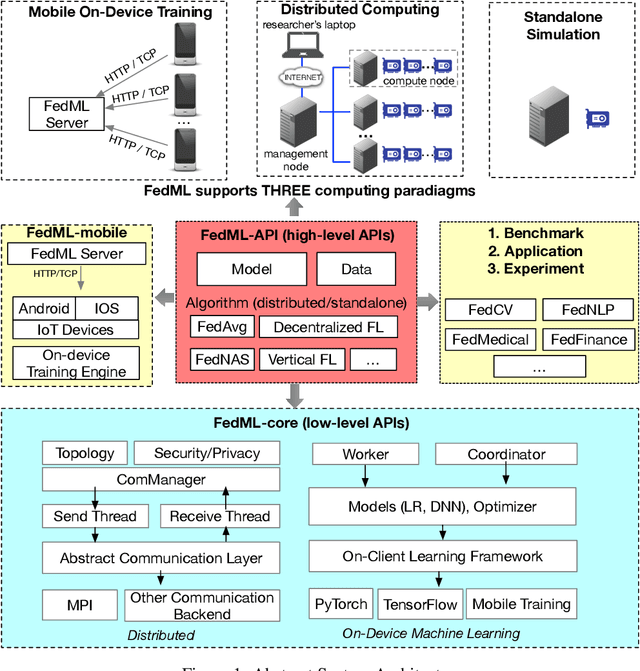


Federated learning is a rapidly growing research field in the machine learning domain. Although considerable research efforts have been made, existing libraries cannot adequately support diverse algorithmic development (e.g., diverse topology and flexible message exchange), and inconsistent dataset and model usage in experiments make fair comparisons difficult. In this work, we introduce FedML, an open research library and benchmark that facilitates the development of new federated learning algorithms and fair performance comparisons. FedML supports three computing paradigms (distributed training, mobile on-device training, and standalone simulation) for users to conduct experiments in different system environments. FedML also promotes diverse algorithmic research with flexible and generic API design and reference baseline implementations. A curated and comprehensive benchmark dataset for the non-I.I.D setting aims at making a fair comparison. We believe FedML can provide an efficient and reproducible means of developing and evaluating algorithms for the federated learning research community. We maintain the source code, documents, and user community at https://FedML.ai.