 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Rebatching for Efficient Early-Exit Inference with DREX
Dec 17, 2025Early-Exit (EE) is a Large Language Model (LLM) architecture that accelerates inference by allowing easier tokens to be generated using only a subset of the model's layers. However, traditional batching frameworks are ill-suited for EE LLMs, as not all requests in a batch may be ready to exit at the same time. Existing solutions either force a uniform decision on the batch, which overlooks EE opportunities, or degrade output quality by forcing premature exits. We propose Dynamic Rebatching, a solution where we dynamically reorganize the batch at each early-exit point. Requests that meet the exit criteria are immediately processed, while those that continue are held in a buffer, re-grouped into a new batch, and forwarded to deeper layers. We introduce DREX, an early-exit inference system that implements Dynamic Rebatching with two key optimizations: 1) a copy-free rebatching buffer that avoids physical data movement, and 2) an EE and SLA-aware scheduler that analytically predicts whether a given rebatching operation will be profitable. DREX also efficiently handles the missing KV cache from skipped layers using memory-efficient state-copying. Our evaluation shows that DREX improves throughput by 2-12% compared to baseline approaches while maintaining output quality. Crucially, DREX completely eliminates involuntary exits, providing a key guarantee for preserving the output quality intended by the EE model.
Towards Safer Heuristics With XPlain
Oct 19, 2024



Many problems that cloud operators solve are computationally expensive, and operators often use heuristic algorithms (that are faster and scale better than optimal) to solve them more efficiently. Heuristic analyzers enable operators to find when and by how much their heuristics underperform. However, these tools do not provide enough detail for operators to mitigate the heuristic's impact in practice: they only discover a single input instance that causes the heuristic to underperform (and not the full set), and they do not explain why. We propose XPlain, a tool that extends these analyzers and helps operators understand when and why their heuristics underperform. We present promising initial results that show such an extension is viable.
FedSpace: An Efficient Federated Learning Framework at Satellites and Ground Stations
Feb 02, 2022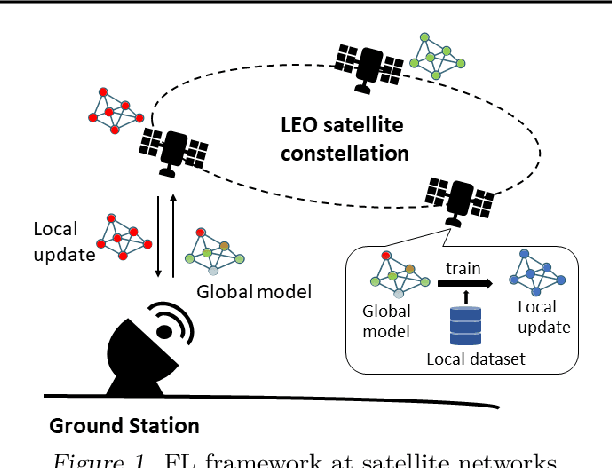

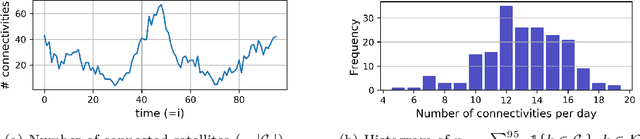

Large-scale deployments of low Earth orbit (LEO) satellites collect massive amount of Earth imageries and sensor data, which can empower machine learning (ML) to address global challenges such as real-time disaster navigation and mitigation. However, it is often infeasible to download all the high-resolution images and train these ML models on the ground because of limited downlink bandwidth, sparse connectivity, and regularization constraints on the imagery resolution. To address these challenges, we leverage Federated Learning (FL), where ground stations and satellites collaboratively train a global ML model without sharing the captured images on the satellites. We show fundamental challenges in applying existing FL algorithms among satellites and ground stations, and we formulate an optimization problem which captures a unique trade-off between staleness and idleness. We propose a novel FL framework, named FedSpace, which dynamically schedules model aggregation based on the deterministic and time-varying connectivity according to satellite orbits. Extensive numerical evaluations based on real-world satellite images and satellite networks show that FedSpace reduces the training time by 1.7 days (38.6%) over the state-of-the-art FL algorithms.
Interpret-able feedback for AutoML systems
Feb 22, 2021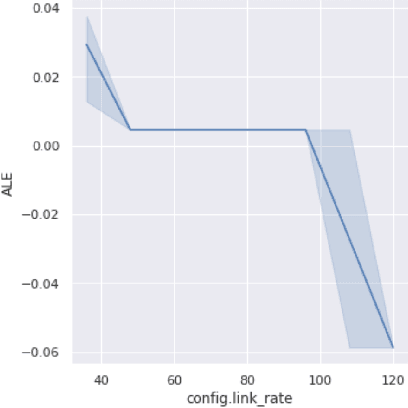


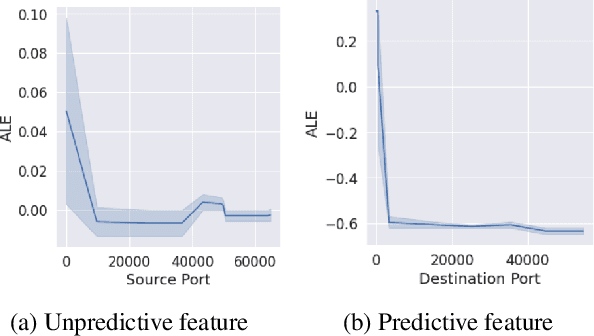
Automated machine learning (AutoML) systems aim to enable training machine learning (ML) models for non-ML experts. A shortcoming of these systems is that when they fail to produce a model with high accuracy, the user has no path to improve the model other than hiring a data scientist or learning ML -- this defeats the purpose of AutoML and limits its adoption. We introduce an interpretable data feedback solution for AutoML. Our solution suggests new data points for the user to label (without requiring a pool of unlabeled data) to improve the model's accuracy. Our solution analyzes how features influence the prediction among all ML models in an AutoML ensemble, and we suggest more data samples from feature ranges that have high variance in such analysis. Our evaluation shows that our solution can improve the accuracy of AutoML by 7-8% and significantly outperforms popular active learning solutions in data efficiency, all the while providing the added benefit of being interpretable.