 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecuring Secure Aggregation: Mitigating Multi-Round Privacy Leakage in Federated Learning
Paper and Code
Jun 07, 2021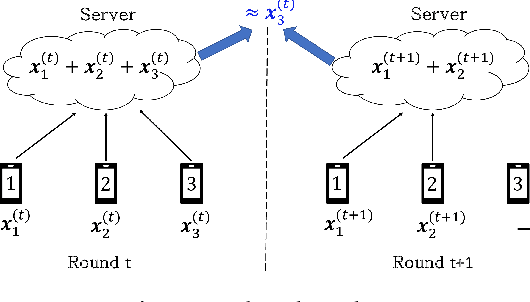
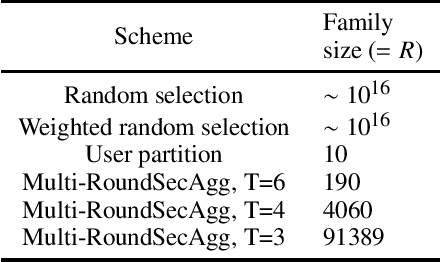
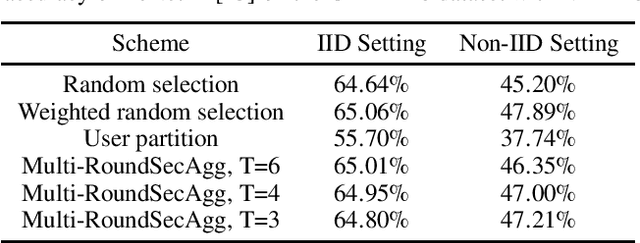
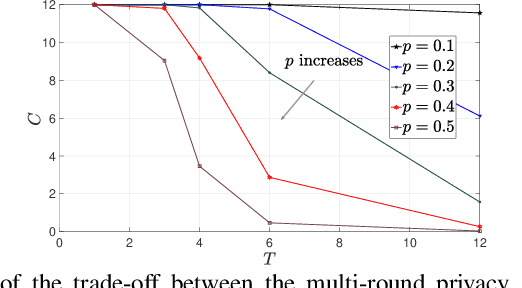
Secure aggregation is a critical component in federated learning, which enables the server to learn the aggregate model of the users without observing their local models. Conventionally, secure aggregation algorithms focus only on ensuring the privacy of individual users in a single training round. We contend that such designs can lead to significant privacy leakages over multiple training rounds, due to partial user selection/participation at each round of federated learning. In fact, we empirically show that the conventional random user selection strategies for federated learning lead to leaking users' individual models within number of rounds linear in the number of users. To address this challenge, we introduce a secure aggregation framework with multi-round privacy guarantees. In particular, we introduce a new metric to quantify the privacy guarantees of federated learning over multiple training rounds, and develop a structured user selection strategy that guarantees the long-term privacy of each user (over any number of training rounds). Our framework also carefully accounts for the fairness and the average number of participating users at each round. We perform several experiments on MNIST and CIFAR-10 datasets in the IID and the non-IID settings to demonstrate the performance improvement over the baseline algorithms, both in terms of privacy protection and test accuracy.