 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurbo-Aggregate: Breaking the Quadratic Aggregation Barrier in Secure Federated Learning
Paper and Code
Feb 11, 2020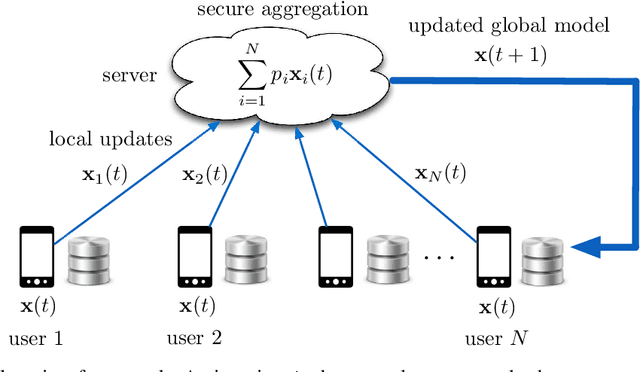
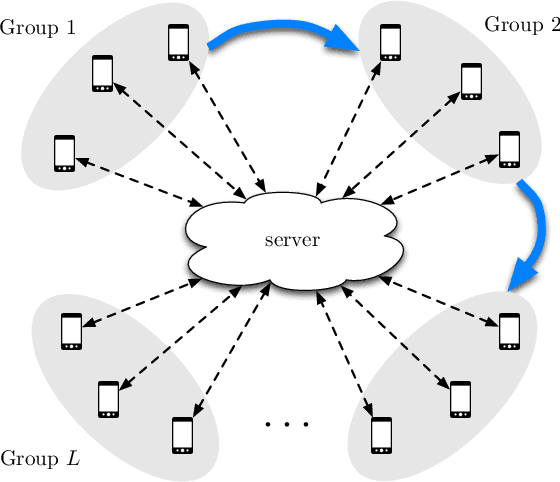
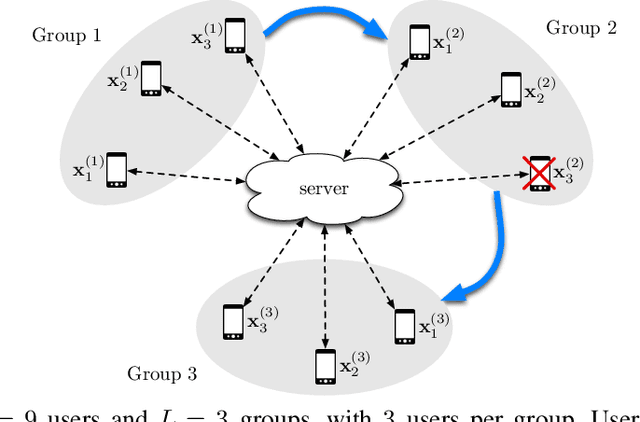
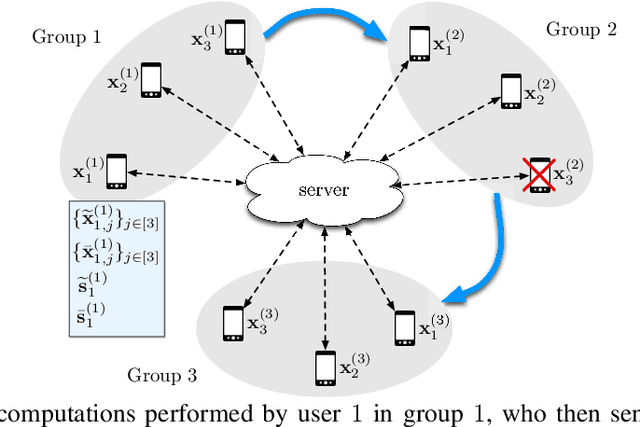
Federated learning is gaining significant interests as it enables model training over a large volume of data that is distributedly stored over many users, while protecting the privacy of the individual users. However, a major bottleneck in scaling federated learning to a large number of users is the overhead of secure model aggregation across many users. In fact, the overhead of state-of-the-art protocols for secure model aggregation grows quadratically with the number of users. We propose a new scheme, named Turbo-Aggregate, that in a network with $N$ users achieves a secure aggregation overhead of $O(N\log{N})$, as opposed to $O(N^2)$, while tolerating up to a user dropout rate of $50\%$. Turbo-Aggregate employs a multi-group circular strategy for efficient model aggregation, and leverages additive secret sharing and novel coding techniques for injecting aggregation redundancy in order to handle user dropouts while guaranteeing user privacy. We experimentally demonstrate that Turbo-Aggregate achieves a total running time that grows almost linear in the number of users, and provides up to $14\times$ speedup over the state-of-the-art schemes with upto $N=200$ users. We also experimentally evaluate the impact of several key network parameters (e.g., user dropout rate, bandwidth, and model size) on the performance of Turbo-Aggregate.