 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet Invariant Rationale Discovery Inspire Graph Contrastive Learning
Jun 16, 2022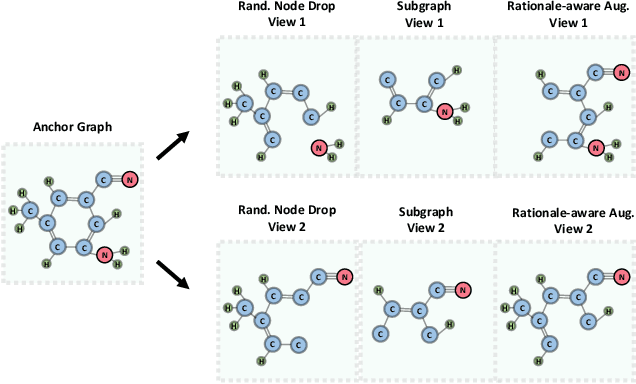
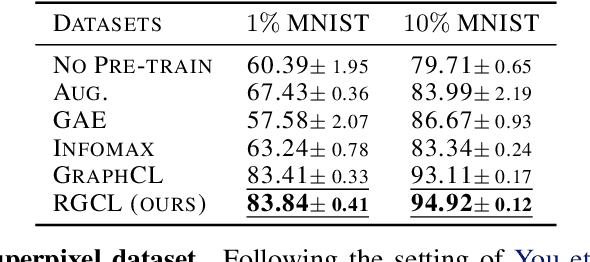
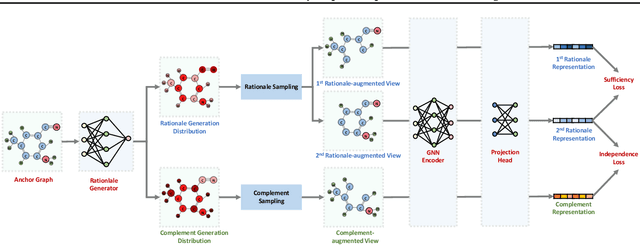

Leading graph contrastive learning (GCL) methods perform graph augmentations in two fashions: (1) randomly corrupting the anchor graph, which could cause the loss of semantic information, or (2) using domain knowledge to maintain salient features, which undermines the generalization to other domains. Taking an invariance look at GCL, we argue that a high-performing augmentation should preserve the salient semantics of anchor graphs regarding instance-discrimination. To this end, we relate GCL with invariant rationale discovery, and propose a new framework, Rationale-aware Graph Contrastive Learning (RGCL). Specifically, without supervision signals, RGCL uses a rationale generator to reveal salient features about graph instance-discrimination as the rationale, and then creates rationale-aware views for contrastive learning. This rationale-aware pre-training scheme endows the backbone model with the powerful representation ability, further facilitating the fine-tuning on downstream tasks. On MNIST-Superpixel and MUTAG datasets, visual inspections on the discovered rationales showcase that the rationale generator successfully captures the salient features (i.e. distinguishing semantic nodes in graphs). On biochemical molecule and social network benchmark datasets, the state-of-the-art performance of RGCL demonstrates the effectiveness of rationale-aware views for contrastive learning. Our codes are available at https://github.com/lsh0520/RGCL.
Reinforced Causal Explainer for Graph Neural Networks
Apr 27, 2022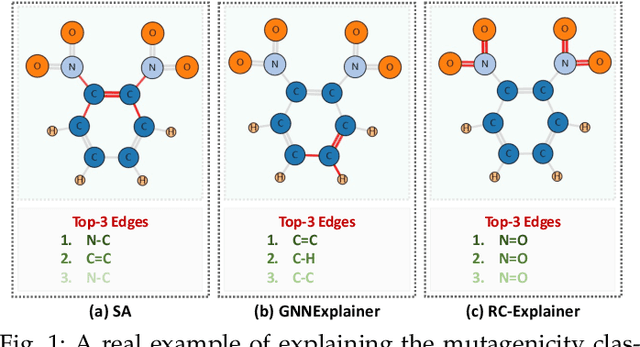
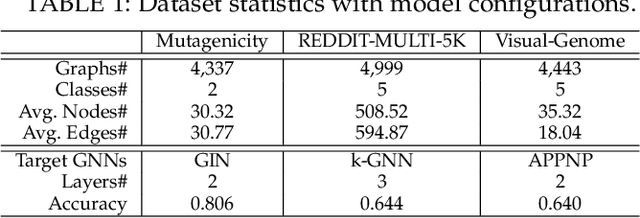


Explainability is crucial for probing graph neural networks (GNNs), answering questions like "Why the GNN model makes a certain prediction?". Feature attribution is a prevalent technique of highlighting the explanatory subgraph in the input graph, which plausibly leads the GNN model to make its prediction. Various attribution methods exploit gradient-like or attention scores as the attributions of edges, then select the salient edges with top attribution scores as the explanation. However, most of these works make an untenable assumption - the selected edges are linearly independent - thus leaving the dependencies among edges largely unexplored, especially their coalition effect. We demonstrate unambiguous drawbacks of this assumption - making the explanatory subgraph unfaithful and verbose. To address this challenge, we propose a reinforcement learning agent, Reinforced Causal Explainer (RC-Explainer). It frames the explanation task as a sequential decision process - an explanatory subgraph is successively constructed by adding a salient edge to connect the previously selected subgraph. Technically, its policy network predicts the action of edge addition, and gets a reward that quantifies the action's causal effect on the prediction. Such reward accounts for the dependency of the newly-added edge and the previously-added edges, thus reflecting whether they collaborate together and form a coalition to pursue better explanations. As such, RC-Explainer is able to generate faithful and concise explanations, and has a better generalization power to unseen graphs. When explaining different GNNs on three graph classification datasets, RC-Explainer achieves better or comparable performance to SOTA approaches w.r.t. predictive accuracy and contrastivity, and safely passes sanity checks and visual inspections. Codes are available at https://github.com/xiangwang1223/reinforced_causal_explainer.
Knowledge-Aware Meta-learning for Low-Resource Text Classification
Sep 10, 2021
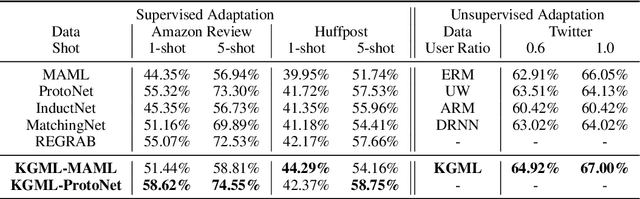
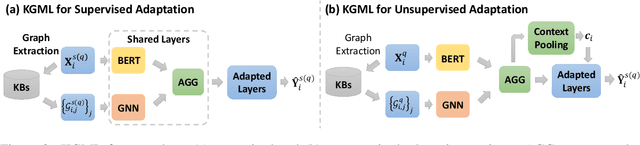
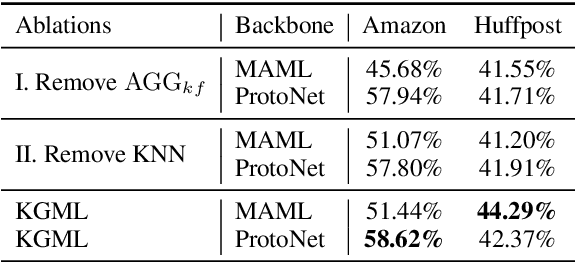
Meta-learning has achieved great success in leveraging the historical learned knowledge to facilitate the learning process of the new task. However, merely learning the knowledge from the historical tasks, adopted by current meta-learning algorithms, may not generalize well to testing tasks when they are not well-supported by training tasks. This paper studies a low-resource text classification problem and bridges the gap between meta-training and meta-testing tasks by leveraging the external knowledge bases. Specifically, we propose KGML to introduce additional representation for each sentence learned from the extracted sentence-specific knowledge graph. The extensive experiments on three datasets demonstrate the effectiveness of KGML under both supervised adaptation and unsupervised adaptation settings.