 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePay Attention to Small Weights
Jun 26, 2025Finetuning large pretrained neural networks is known to be resource-intensive, both in terms of memory and computational cost. To mitigate this, a common approach is to restrict training to a subset of the model parameters. By analyzing the relationship between gradients and weights during finetuning, we observe a notable pattern: large gradients are often associated with small-magnitude weights. This correlation is more pronounced in finetuning settings than in training from scratch. Motivated by this observation, we propose NANOADAM, which dynamically updates only the small-magnitude weights during finetuning and offers several practical advantages: first, this criterion is gradient-free -- the parameter subset can be determined without gradient computation; second, it preserves large-magnitude weights, which are likely to encode critical features learned during pretraining, thereby reducing the risk of catastrophic forgetting; thirdly, it permits the use of larger learning rates and consistently leads to better generalization performance in experiments. We demonstrate this for both NLP and vision tasks.
Sign-In to the Lottery: Reparameterizing Sparse Training From Scratch
Apr 17, 2025The performance gap between training sparse neural networks from scratch (PaI) and dense-to-sparse training presents a major roadblock for efficient deep learning. According to the Lottery Ticket Hypothesis, PaI hinges on finding a problem specific parameter initialization. As we show, to this end, determining correct parameter signs is sufficient. Yet, they remain elusive to PaI. To address this issue, we propose Sign-In, which employs a dynamic reparameterization that provably induces sign flips. Such sign flips are complementary to the ones that dense-to-sparse training can accomplish, rendering Sign-In as an orthogonal method. While our experiments and theory suggest performance improvements of PaI, they also carve out the main open challenge to close the gap between PaI and dense-to-sparse training.
Mirror, Mirror of the Flow: How Does Regularization Shape Implicit Bias?
Apr 17, 2025


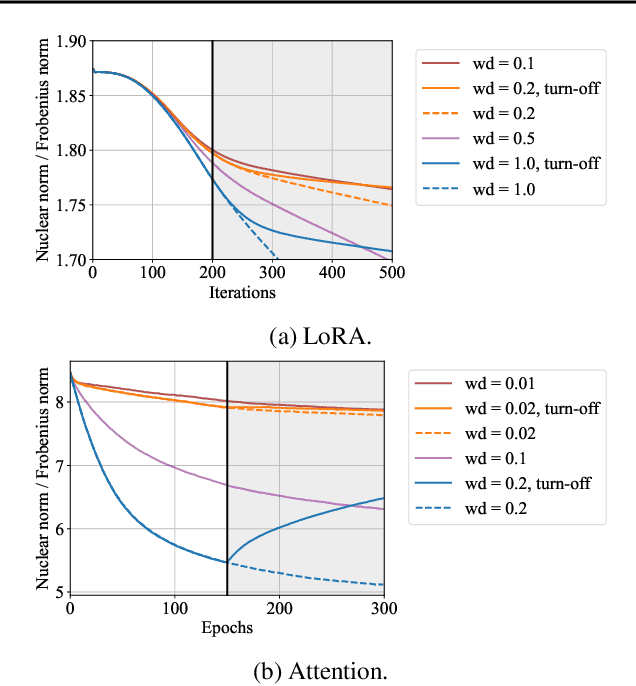
Implicit bias plays an important role in explaining how overparameterized models generalize well. Explicit regularization like weight decay is often employed in addition to prevent overfitting. While both concepts have been studied separately, in practice, they often act in tandem. Understanding their interplay is key to controlling the shape and strength of implicit bias, as it can be modified by explicit regularization. To this end, we incorporate explicit regularization into the mirror flow framework and analyze its lasting effects on the geometry of the training dynamics, covering three distinct effects: positional bias, type of bias, and range shrinking. Our analytical approach encompasses a broad class of problems, including sparse coding, matrix sensing, single-layer attention, and LoRA, for which we demonstrate the utility of our insights. To exploit the lasting effect of regularization and highlight the potential benefit of dynamic weight decay schedules, we propose to switch off weight decay during training, which can improve generalization, as we demonstrate in experiments.
Mask in the Mirror: Implicit Sparsification
Aug 19, 2024



Sparsifying deep neural networks to reduce their inference cost is an NP-hard problem and difficult to optimize due to its mixed discrete and continuous nature. Yet, as we prove, continuous sparsification has already an implicit bias towards sparsity that would not require common projections of relaxed mask variables. While implicit rather than explicit regularization induces benefits, it usually does not provide enough flexibility in practice, as only a specific target sparsity is obtainable. To exploit its potential for continuous sparsification, we propose a way to control the strength of the implicit bias. Based on the mirror flow framework, we derive resulting convergence and optimality guarantees in the context of underdetermined linear regression and demonstrate the utility of our insights in more general neural network sparsification experiments, achieving significant performance gains, particularly in the high-sparsity regime. Our theoretical contribution might be of independent interest, as we highlight a way to enter the rich regime and show that implicit bias is controllable by a time-dependent Bregman potential.