 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Is All You Need For Mixture-of-Depths Routing
Dec 30, 2024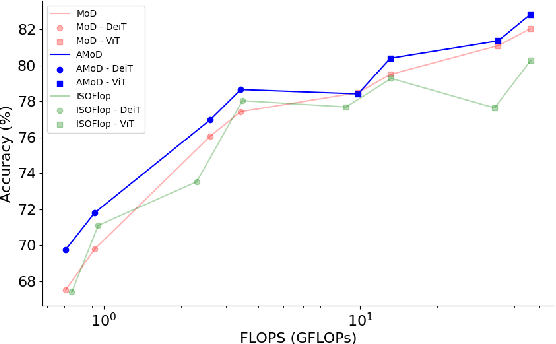
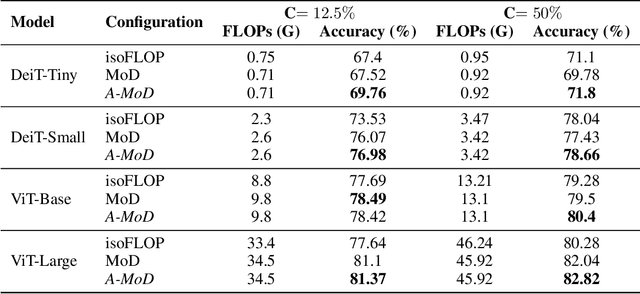
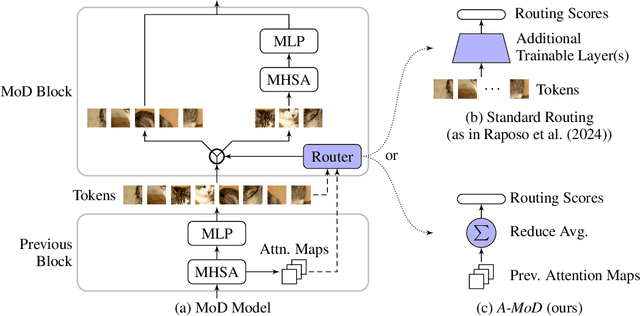
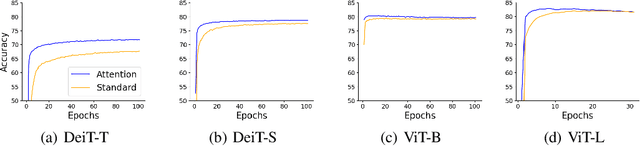
Advancements in deep learning are driven by training models with increasingly larger numbers of parameters, which in turn heightens the computational demands. To address this issue, Mixture-of-Depths (MoD) models have been proposed to dynamically assign computations only to the most relevant parts of the inputs, thereby enabling the deployment of large-parameter models with high efficiency during inference and training. These MoD models utilize a routing mechanism to determine which tokens should be processed by a layer, or skipped. However, conventional MoD models employ additional network layers specifically for the routing which are difficult to train, and add complexity and deployment overhead to the model. In this paper, we introduce a novel attention-based routing mechanism A-MoD that leverages the existing attention map of the preceding layer for routing decisions within the current layer. Compared to standard routing, A-MoD allows for more efficient training as it introduces no additional trainable parameters and can be easily adapted from pretrained transformer models. Furthermore, it can increase the performance of the MoD model. For instance, we observe up to 2% higher accuracy on ImageNet compared to standard routing and isoFLOP ViT baselines. Furthermore, A-MoD improves the MoD training convergence, leading to up to 2x faster transfer learning.
Object-Focused Data Selection for Dense Prediction Tasks
Dec 13, 2024



Dense prediction tasks such as object detection and segmentation require high-quality labels at pixel level, which are costly to obtain. Recent advances in foundation models have enabled the generation of autolabels, which we find to be competitive but not yet sufficient to fully replace human annotations, especially for more complex datasets. Thus, we consider the challenge of selecting a representative subset of images for labeling from a large pool of unlabeled images under a constrained annotation budget. This task is further complicated by imbalanced class distributions, as rare classes are often underrepresented in selected subsets. We propose object-focused data selection (OFDS) which leverages object-level representations to ensure that the selected image subsets semantically cover the target classes, including rare ones. We validate OFDS on PASCAL VOC and Cityscapes for object detection and semantic segmentation tasks. Our experiments demonstrate that prior methods which employ image-level representations fail to consistently outperform random selection. In contrast, OFDS consistently achieves state-of-the-art performance with substantial improvements over all baselines in scenarios with imbalanced class distributions. Moreover, we demonstrate that pre-training with autolabels on the full datasets before fine-tuning on human-labeled subsets selected by OFDS further enhances the final performance.
Zero-Shot Distillation for Image Encoders: How to Make Effective Use of Synthetic Data
Apr 25, 2024



Multi-modal foundation models such as CLIP have showcased impressive zero-shot capabilities. However, their applicability in resource-constrained environments is limited due to their large number of parameters and high inference time. While existing approaches have scaled down the entire CLIP architecture, we focus on training smaller variants of the image encoder, which suffices for efficient zero-shot classification. The use of synthetic data has shown promise in distilling representations from larger teachers, resulting in strong few-shot and linear probe performance. However, we find that this approach surprisingly fails in true zero-shot settings when using contrastive losses. We identify the exploitation of spurious features as being responsible for poor generalization between synthetic and real data. However, by using the image feature-based L2 distillation loss, we mitigate these problems and train students that achieve zero-shot performance which on four domain-specific datasets is on-par with a ViT-B/32 teacher model trained on DataCompXL, while featuring up to 92% fewer parameters.