 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Erdös and Rényi Win the Lottery
Oct 05, 2022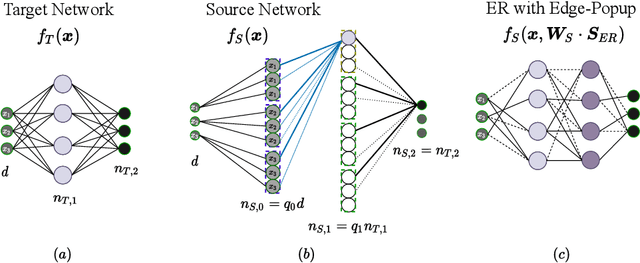

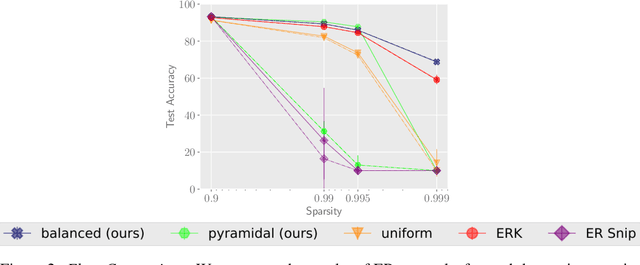

Random masks define surprisingly effective sparse neural network models, as has been shown empirically. The resulting Erd\"os-R\'enyi (ER) random graphs can often compete with dense architectures and state-of-the-art lottery ticket pruning algorithms struggle to outperform them, even though the random baselines do not rely on computationally expensive pruning-training iterations but can be drawn initially without significant computational overhead. We offer a theoretical explanation of how such ER masks can approximate arbitrary target networks if they are wider by a logarithmic factor in the inverse sparsity $1 / \log(1/\text{sparsity})$. While we are the first to show theoretically and experimentally that random ER source networks contain strong lottery tickets, we also prove the existence of weak lottery tickets that require a lower degree of overparametrization than strong lottery tickets. These unusual results are based on the observation that ER masks are well trainable in practice, which we verify in experiments with varied choices of random masks. Some of these data-free choices outperform previously proposed random approaches on standard image classification benchmark datasets.