 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePubSwap: Public-Data Off-Policy Coordination for Federated RLVR
Apr 14, 2026Reasoning post-training with reinforcement learning from verifiable rewards (RLVR) is typically studied in centralized settings, yet many realistic applications involve decentralized private data distributed across organizations. Federated training is a natural solution, but scaling RLVR in this regime is challenging: full-model synchronization is expensive, and performing many local steps can cause severe client drift under heterogeneous data. We propose a federated RLVR framework that combines LoRA-based local adaptation with public-data-based off-policy steps to improve both communication efficiency and cross-client coordination. In particular, a small shared public dataset is used to periodically exchange and reuse response-level training signals across organizations, providing a lightweight anchor toward a more globally aligned objective without exposing private data. Our method selectively replaces locally incorrect responses with globally correct ones during public-data steps, thereby keeping training closer to the local policy while still benefiting from cross-client coordination. Across mathematical and medical reasoning benchmarks and models, our method consistently improves over standard baselines. Our results highlight a simple and effective recipe for federated reasoning post-training: combining low-rank communication with limited public-data coordination.
Federate the Router: Learning Language Model Routers with Sparse and Decentralized Evaluations
Jan 29, 2026Large language models (LLMs) are increasingly accessed as remotely hosted services by edge and enterprise clients that cannot run frontier models locally. Since models vary widely in capability and price, routing queries to models that balance quality and inference cost is essential. Existing router approaches assume access to centralized query-model evaluation data. However, these data are often fragmented across clients, such as end users and organizations, and are privacy-sensitive, which makes centralizing data infeasible. Additionally, per-client router training is ineffective since local evaluation data is limited and covers only a restricted query distribution and a biased subset of model evaluations. We introduce the first federated framework for LLM routing, enabling clients to learn a shared routing policy from local offline query-model evaluation data. Our framework supports both parametric multilayer perceptron router and nonparametric K-means router under heterogeneous client query distributions and non-uniform model coverage. Across two benchmarks, federated collaboration improves the accuracy-cost frontier over client-local routers, both via increased effective model coverage and better query generalization. Our theoretical results also validate that federated training reduces routing suboptimality.
Ravan: Multi-Head Low-Rank Adaptation for Federated Fine-Tuning
Jun 05, 2025Large language models (LLMs) have not yet effectively leveraged the vast amounts of edge-device data, and federated learning (FL) offers a promising paradigm to collaboratively fine-tune LLMs without transferring private edge data to the cloud. To operate within the computation and communication constraints of edge devices, recent literature on federated fine-tuning of LLMs proposes the use of low-rank adaptation (LoRA) and similar parameter-efficient methods. However, LoRA-based methods suffer from accuracy degradation in FL settings, primarily because of data and computational heterogeneity across clients. We propose \textsc{Ravan}, an adaptive multi-head LoRA method that balances parameter efficiency and model expressivity by reparameterizing the weight updates as the sum of multiple LoRA heads $s_i\textbf{B}_i\textbf{H}_i\textbf{A}_i$ in which only the core matrices $\textbf{H}_i$ and their lightweight scaling factors $s_i$ are trained. These trainable scaling factors let the optimization focus on the most useful heads, recovering a higher-rank approximation of the full update without increasing the number of communicated parameters since clients upload $s_i\textbf{H}_i$ directly. Experiments on vision and language benchmarks show that \textsc{Ravan} improves test accuracy by 2-8\% over prior parameter-efficient baselines, making it a robust and scalable solution for federated fine-tuning of LLMs.
Federated Communication-Efficient Multi-Objective Optimization
Oct 21, 2024



We study a federated version of multi-objective optimization (MOO), where a single model is trained to optimize multiple objective functions. MOO has been extensively studied in the centralized setting but is less explored in federated or distributed settings. We propose FedCMOO, a novel communication-efficient federated multi-objective optimization (FMOO) algorithm that improves the error convergence performance of the model compared to existing approaches. Unlike prior works, the communication cost of FedCMOO does not scale with the number of objectives, as each client sends a single aggregated gradient, obtained using randomized SVD (singular value decomposition), to the central server. We provide a convergence analysis of the proposed method for smooth non-convex objective functions under milder assumptions than in prior work. In addition, we introduce a variant of FedCMOO that allows users to specify a preference over the objectives in terms of a desired ratio of the final objective values. Through extensive experiments, we demonstrate the superiority of our proposed method over baseline approaches.
FedAST: Federated Asynchronous Simultaneous Training
Jun 01, 2024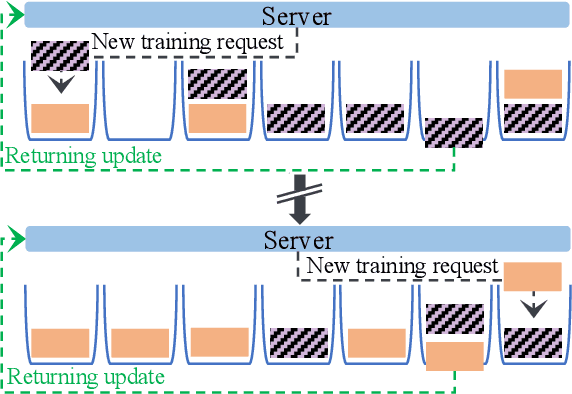



Federated Learning (FL) enables edge devices or clients to collaboratively train machine learning (ML) models without sharing their private data. Much of the existing work in FL focuses on efficiently learning a model for a single task. In this paper, we study simultaneous training of multiple FL models using a common set of clients. The few existing simultaneous training methods employ synchronous aggregation of client updates, which can cause significant delays because large models and/or slow clients can bottleneck the aggregation. On the other hand, a naive asynchronous aggregation is adversely affected by stale client updates. We propose FedAST, a buffered asynchronous federated simultaneous training algorithm that overcomes bottlenecks from slow models and adaptively allocates client resources across heterogeneous tasks. We provide theoretical convergence guarantees for FedAST for smooth non-convex objective functions. Extensive experiments over multiple real-world datasets demonstrate that our proposed method outperforms existing simultaneous FL approaches, achieving up to 46.0% reduction in time to train multiple tasks to completion.
DEQ-MPI: A Deep Equilibrium Reconstruction with Learned Consistency for Magnetic Particle Imaging
Dec 26, 2022Magnetic particle imaging (MPI) offers unparalleled contrast and resolution for tracing magnetic nanoparticles. A common imaging procedure calibrates a system matrix (SM) that is used to reconstruct data from subsequent scans. The ill-posed reconstruction problem can be solved by simultaneously enforcing data consistency based on the SM and regularizing the solution based on an image prior. Traditional hand-crafted priors cannot capture the complex attributes of MPI images, whereas recent MPI methods based on learned priors can suffer from extensive inference times or limited generalization performance. Here, we introduce a novel physics-driven method for MPI reconstruction based on a deep equilibrium model with learned data consistency (DEQ-MPI). DEQ-MPI reconstructs images by augmenting neural networks into an iterative optimization, as inspired by unrolling methods in deep learning. Yet, conventional unrolling methods are computationally restricted to few iterations resulting in non-convergent solutions, and they use hand-crafted consistency measures that can yield suboptimal capture of the data distribution. DEQ-MPI instead trains an implicit mapping to maximize the quality of a convergent solution, and it incorporates a learned consistency measure to better account for the data distribution. Demonstrations on simulated and experimental data indicate that DEQ-MPI achieves superior image quality and competitive inference time to state-of-the-art MPI reconstruction methods.
TranSMS: Transformers for Super-Resolution Calibration in Magnetic Particle Imaging
Nov 03, 2021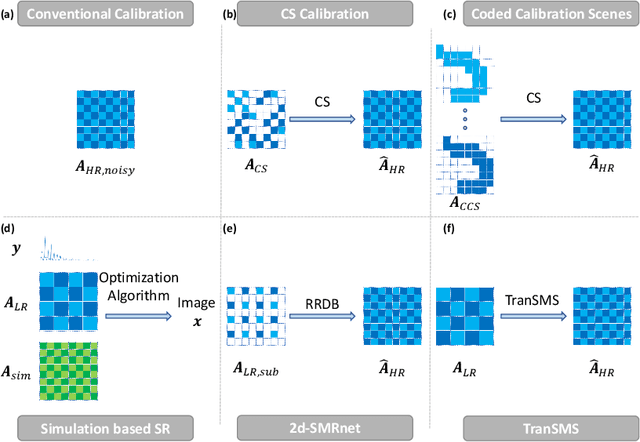
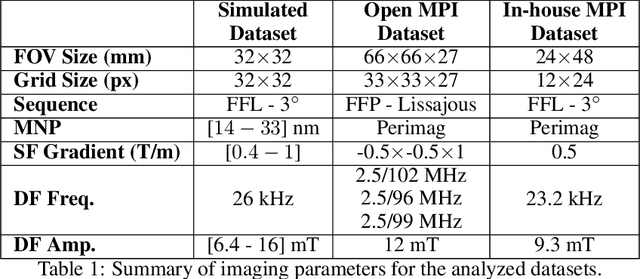
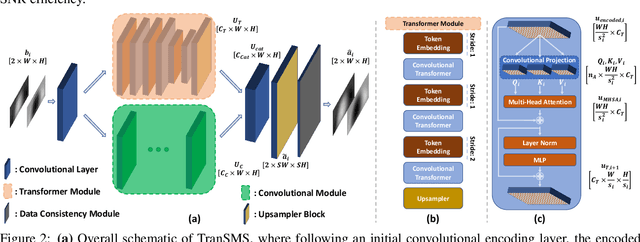
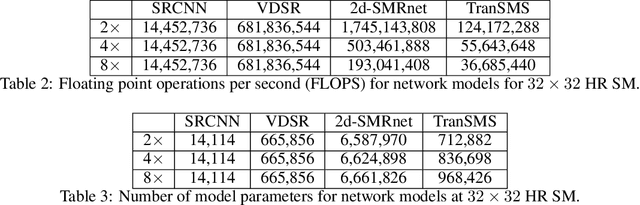
Magnetic particle imaging (MPI) is a recent modality that offers exceptional contrast for magnetic nanoparticles (MNP) at high spatio-temporal resolution. A common procedure in MPI starts with a calibration scan to measure the system matrix (SM), which is then used to setup an inverse problem to reconstruct images of the particle distribution during subsequent scans. This calibration enables the reconstruction to sensitively account for various system imperfections. Yet time-consuming SM measurements have to be repeated under notable drifts or changes in system properties. Here, we introduce a novel deep learning approach for accelerated MPI calibration based on transformers for SM super-resolution (TranSMS). Low-resolution SM measurements are performed using large MNP samples for improved signal-to-noise ratio efficiency, and the high-resolution SM is super-resolved via a model-based deep network. TranSMS leverages a vision transformer module to capture contextual relationships in low-resolution input images, a dense convolutional module for localizing high-resolution image features, and a data-consistency module to ensure consistency to measurements. Demonstrations on simulated and experimental data indicate that TranSMS achieves significantly improved SM recovery and image reconstruction in MPI, while enabling acceleration up to 64-fold during two-dimensional calibration.