 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRavan: Multi-Head Low-Rank Adaptation for Federated Fine-Tuning
Jun 05, 2025Large language models (LLMs) have not yet effectively leveraged the vast amounts of edge-device data, and federated learning (FL) offers a promising paradigm to collaboratively fine-tune LLMs without transferring private edge data to the cloud. To operate within the computation and communication constraints of edge devices, recent literature on federated fine-tuning of LLMs proposes the use of low-rank adaptation (LoRA) and similar parameter-efficient methods. However, LoRA-based methods suffer from accuracy degradation in FL settings, primarily because of data and computational heterogeneity across clients. We propose \textsc{Ravan}, an adaptive multi-head LoRA method that balances parameter efficiency and model expressivity by reparameterizing the weight updates as the sum of multiple LoRA heads $s_i\textbf{B}_i\textbf{H}_i\textbf{A}_i$ in which only the core matrices $\textbf{H}_i$ and their lightweight scaling factors $s_i$ are trained. These trainable scaling factors let the optimization focus on the most useful heads, recovering a higher-rank approximation of the full update without increasing the number of communicated parameters since clients upload $s_i\textbf{H}_i$ directly. Experiments on vision and language benchmarks show that \textsc{Ravan} improves test accuracy by 2-8\% over prior parameter-efficient baselines, making it a robust and scalable solution for federated fine-tuning of LLMs.
Federated LoRA with Sparse Communication
Jun 07, 2024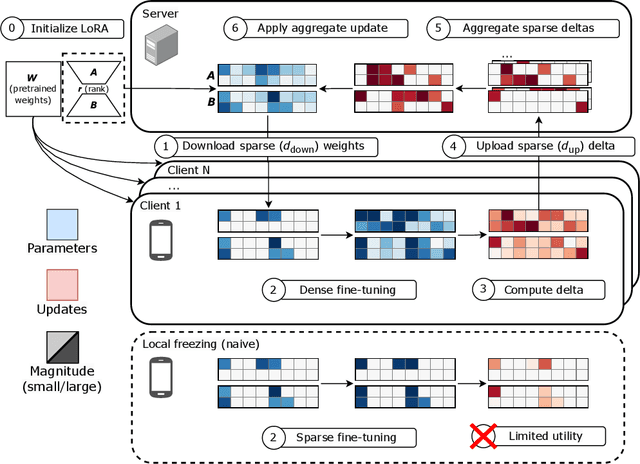

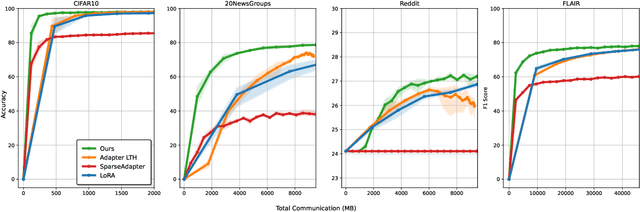
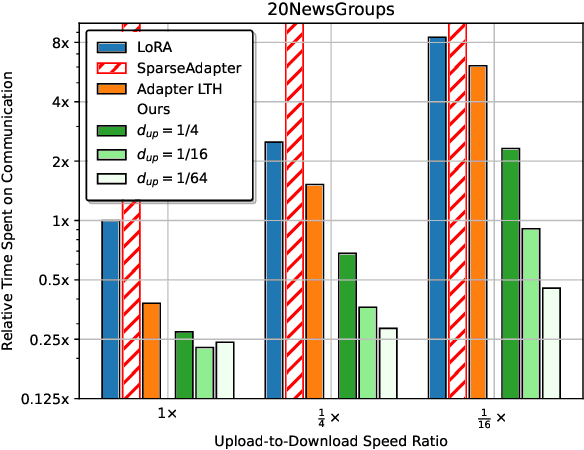
Low-rank adaptation (LoRA) is a natural method for finetuning in communication-constrained machine learning settings such as cross-device federated learning. Prior work that has studied LoRA in the context of federated learning has focused on improving LoRA's robustness to heterogeneity and privacy. In this work, we instead consider techniques for further improving communication-efficiency in federated LoRA. Unfortunately, we show that centralized ML methods that improve the efficiency of LoRA through unstructured pruning do not transfer well to federated settings. We instead study a simple approach, \textbf{FLASC}, that applies sparsity to LoRA during communication while allowing clients to locally fine-tune the entire LoRA module. Across four common federated learning tasks, we demonstrate that this method matches the performance of dense LoRA with up to $10\times$ less communication. Additionally, despite being designed primarily to target communication, we find that this approach has benefits in terms of heterogeneity and privacy relative to existing approaches tailored to these specific concerns. Overall, our work highlights the importance of considering system-specific constraints when developing communication-efficient finetuning approaches, and serves as a simple and competitive baseline for future work in federated finetuning.