 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePathway: a fast and flexible unified stream data processing framework for analytical and Machine Learning applications
Jul 12, 2023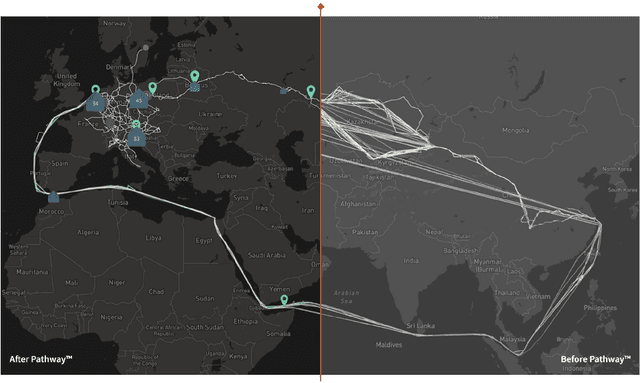

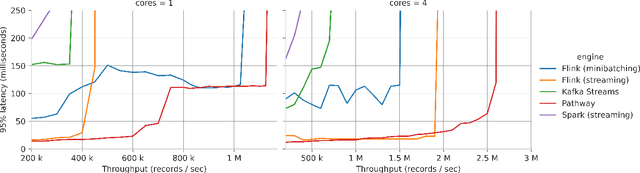
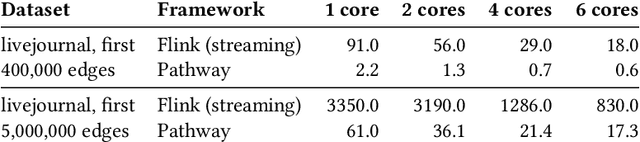
We present Pathway, a new unified data processing framework that can run workloads on both bounded and unbounded data streams. The framework was created with the original motivation of resolving challenges faced when analyzing and processing data from the physical economy, including streams of data generated by IoT and enterprise systems. These required rapid reaction while calling for the application of advanced computation paradigms (machinelearning-powered analytics, contextual analysis, and other elements of complex event processing). Pathway is equipped with a Table API tailored for Python and Python/SQL workflows, and is powered by a distributed incremental dataflow in Rust. We describe the system and present benchmarking results which demonstrate its capabilities in both batch and streaming contexts, where it is able to surpass state-of-the-art industry frameworks in both scenarios. We also discuss streaming use cases handled by Pathway which cannot be easily resolved with state-of-the-art industry frameworks, such as streaming iterative graph algorithms (PageRank, etc.).
Cluster-and-Conquer: When Randomness Meets Graph Locality
Oct 22, 2020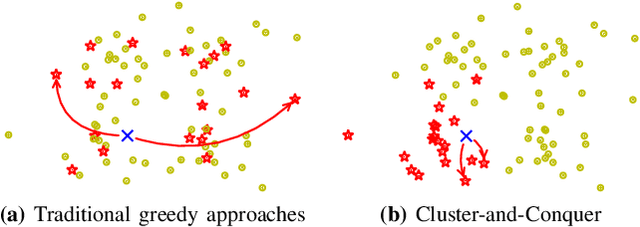
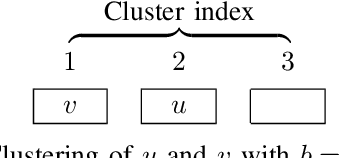
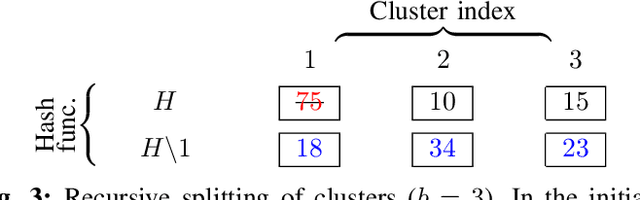

K-Nearest-Neighbors (KNN) graphs are central to many emblematic data mining and machine-learning applications. Some of the most efficient KNN graph algorithms are incremental and local: they start from a random graph, which they incrementally improve by traversing neighbors-of-neighbors links. Paradoxically, this random start is also one of the key weaknesses of these algorithms: nodes are initially connected to dissimilar neighbors, that lie far away according to the similarity metric. As a result, incremental algorithms must first laboriously explore spurious potential neighbors before they can identify similar nodes, and start converging. In this paper, we remove this drawback with Cluster-and-Conquer (C 2 for short). Cluster-and-Conquer boosts the starting configuration of greedy algorithms thanks to a novel lightweight clustering mechanism, dubbed FastRandomHash. FastRandomHash leverages random-ness and recursion to pre-cluster similar nodes at a very low cost. Our extensive evaluation on real datasets shows that Cluster-and-Conquer significantly outperforms existing approaches, including LSH, yielding speed-ups of up to x4.42 while incurring only a negligible loss in terms of KNN quality.