 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Cost of Model-Serving Frameworks: An Experimental Evaluation
Nov 15, 2024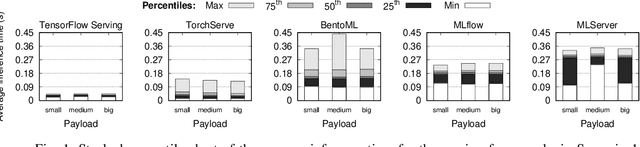
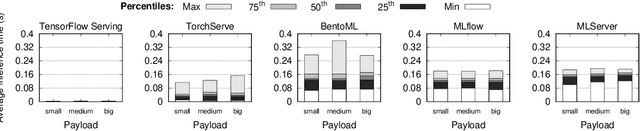
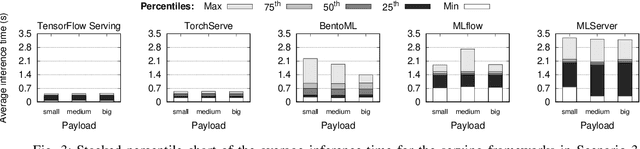
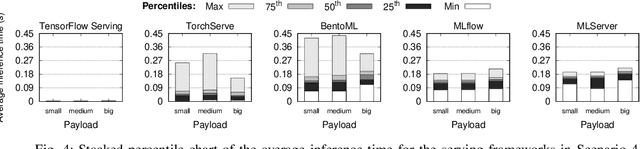
In machine learning (ML), the inference phase is the process of applying pre-trained models to new, unseen data with the objective of making predictions. During the inference phase, end-users interact with ML services to gain insights, recommendations, or actions based on the input data. For this reason, serving strategies are nowadays crucial for deploying and managing models in production environments effectively. These strategies ensure that models are available, scalable, reliable, and performant for real-world applications, such as time series forecasting, image classification, natural language processing, and so on. In this paper, we evaluate the performances of five widely-used model serving frameworks (TensorFlow Serving, TorchServe, MLServer, MLflow, and BentoML) under four different scenarios (malware detection, cryptocoin prices forecasting, image classification, and sentiment analysis). We demonstrate that TensorFlow Serving is able to outperform all the other frameworks in serving deep learning (DL) models. Moreover, we show that DL-specific frameworks (TensorFlow Serving and TorchServe) display significantly lower latencies than the three general-purpose ML frameworks (BentoML, MLFlow, and MLServer).
Pelta: Shielding Transformers to Mitigate Evasion Attacks in Federated Learning
Aug 08, 2023The main premise of federated learning is that machine learning model updates are computed locally, in particular to preserve user data privacy, as those never leave the perimeter of their device. This mechanism supposes the general model, once aggregated, to be broadcast to collaborating and non malicious nodes. However, without proper defenses, compromised clients can easily probe the model inside their local memory in search of adversarial examples. For instance, considering image-based applications, adversarial examples consist of imperceptibly perturbed images (to the human eye) misclassified by the local model, which can be later presented to a victim node's counterpart model to replicate the attack. To mitigate such malicious probing, we introduce Pelta, a novel shielding mechanism leveraging trusted hardware. By harnessing the capabilities of Trusted Execution Environments (TEEs), Pelta masks part of the back-propagation chain rule, otherwise typically exploited by attackers for the design of malicious samples. We evaluate Pelta on a state of the art ensemble model and demonstrate its effectiveness against the Self Attention Gradient adversarial Attack.
Spores: Stateless Predictive Onion Routing for E-Squads
Jul 02, 2020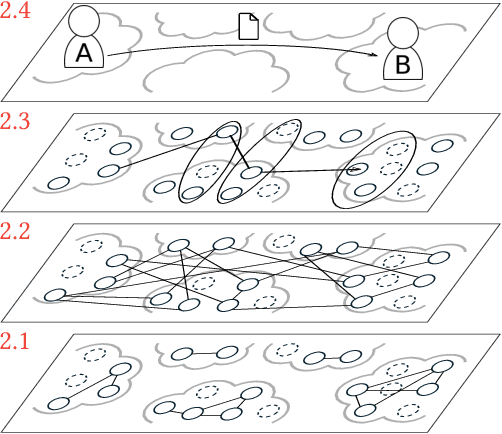
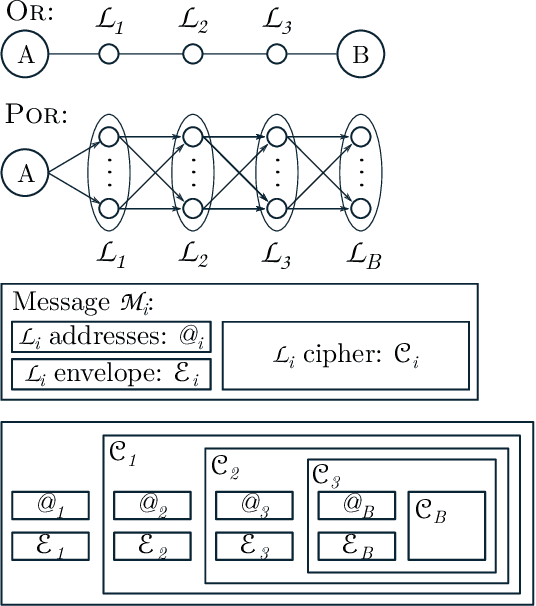
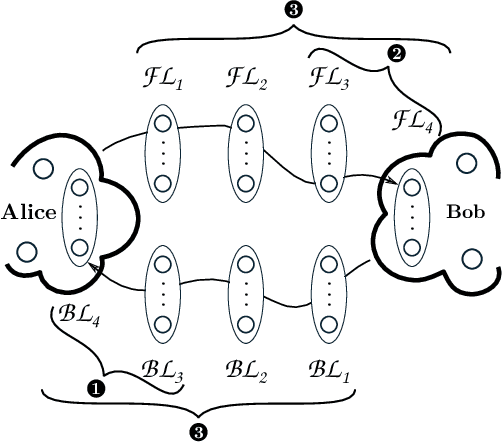
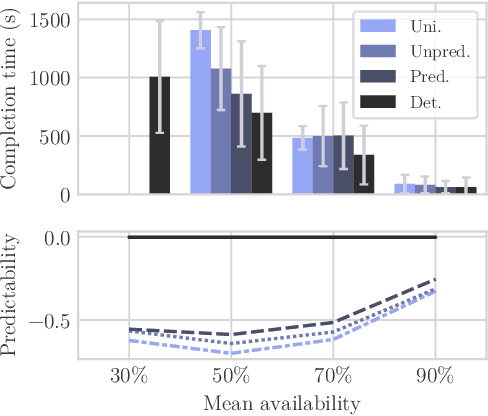
Mass surveillance of the population by state agencies and corporate parties is now a well-known fact. Journalists and whistle-blowers still lack means to circumvent global spying for the sake of their investigations. With Spores, we propose a way for journalists and their sources to plan a posteriori file exchanges when they physically meet. We leverage on the multiplication of personal devices per capita to provide a lightweight, robust and fully anonymous decentralised file transfer protocol between users. Spores hinges on our novel concept of e-squads: one's personal devices, rendered intelligent by gossip communication protocols, can provide private and dependable services to their user. People's e-squads are federated into a novel onion routing network, able to withstand the inherent unreliability of personal appliances while providing reliable routing. Spores' performances are competitive, and its privacy properties of the communication outperform state of the art onion routing strategies.