 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Adversarial Attacks in Federated Learning with Trusted Execution Environments
Sep 13, 2023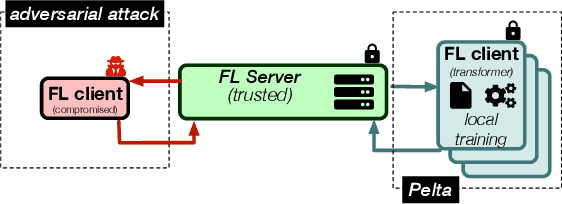
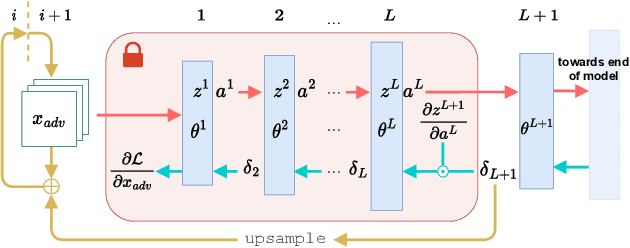
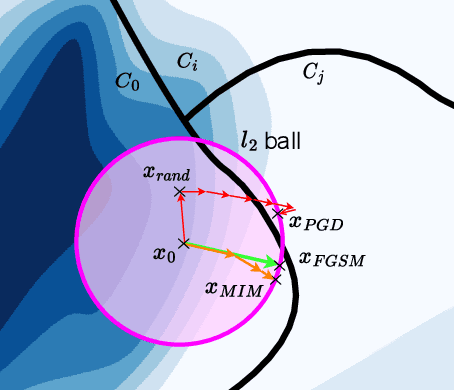

The main premise of federated learning (FL) is that machine learning model updates are computed locally to preserve user data privacy. This approach avoids by design user data to ever leave the perimeter of their device. Once the updates aggregated, the model is broadcast to all nodes in the federation. However, without proper defenses, compromised nodes can probe the model inside their local memory in search for adversarial examples, which can lead to dangerous real-world scenarios. For instance, in image-based applications, adversarial examples consist of images slightly perturbed to the human eye getting misclassified by the local model. These adversarial images are then later presented to a victim node's counterpart model to replay the attack. Typical examples harness dissemination strategies such as altered traffic signs (patch attacks) no longer recognized by autonomous vehicles or seemingly unaltered samples that poison the local dataset of the FL scheme to undermine its robustness. Pelta is a novel shielding mechanism leveraging Trusted Execution Environments (TEEs) that reduce the ability of attackers to craft adversarial samples. Pelta masks inside the TEE the first part of the back-propagation chain rule, typically exploited by attackers to craft the malicious samples. We evaluate Pelta on state-of-the-art accurate models using three well-established datasets: CIFAR-10, CIFAR-100 and ImageNet. We show the effectiveness of Pelta in mitigating six white-box state-of-the-art adversarial attacks, such as Projected Gradient Descent, Momentum Iterative Method, Auto Projected Gradient Descent, the Carlini & Wagner attack. In particular, Pelta constitutes the first attempt at defending an ensemble model against the Self-Attention Gradient attack to the best of our knowledge. Our code is available to the research community at https://github.com/queyrusi/Pelta.
Pelta: Shielding Transformers to Mitigate Evasion Attacks in Federated Learning
Aug 08, 2023The main premise of federated learning is that machine learning model updates are computed locally, in particular to preserve user data privacy, as those never leave the perimeter of their device. This mechanism supposes the general model, once aggregated, to be broadcast to collaborating and non malicious nodes. However, without proper defenses, compromised clients can easily probe the model inside their local memory in search of adversarial examples. For instance, considering image-based applications, adversarial examples consist of imperceptibly perturbed images (to the human eye) misclassified by the local model, which can be later presented to a victim node's counterpart model to replicate the attack. To mitigate such malicious probing, we introduce Pelta, a novel shielding mechanism leveraging trusted hardware. By harnessing the capabilities of Trusted Execution Environments (TEEs), Pelta masks part of the back-propagation chain rule, otherwise typically exploited by attackers for the design of malicious samples. We evaluate Pelta on a state of the art ensemble model and demonstrate its effectiveness against the Self Attention Gradient adversarial Attack.