 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Cost of Model-Serving Frameworks: An Experimental Evaluation
Nov 15, 2024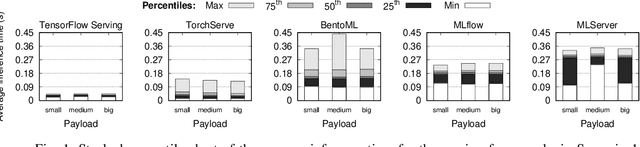
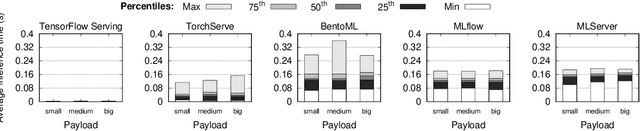
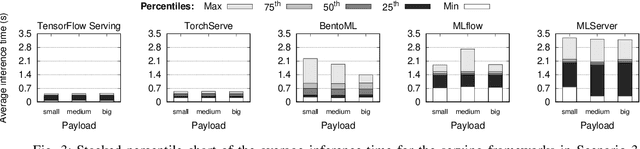
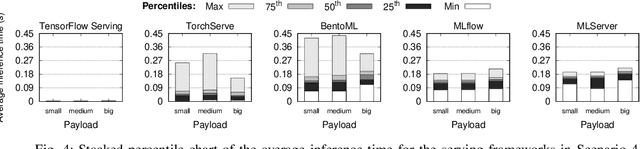
In machine learning (ML), the inference phase is the process of applying pre-trained models to new, unseen data with the objective of making predictions. During the inference phase, end-users interact with ML services to gain insights, recommendations, or actions based on the input data. For this reason, serving strategies are nowadays crucial for deploying and managing models in production environments effectively. These strategies ensure that models are available, scalable, reliable, and performant for real-world applications, such as time series forecasting, image classification, natural language processing, and so on. In this paper, we evaluate the performances of five widely-used model serving frameworks (TensorFlow Serving, TorchServe, MLServer, MLflow, and BentoML) under four different scenarios (malware detection, cryptocoin prices forecasting, image classification, and sentiment analysis). We demonstrate that TensorFlow Serving is able to outperform all the other frameworks in serving deep learning (DL) models. Moreover, we show that DL-specific frameworks (TensorFlow Serving and TorchServe) display significantly lower latencies than the three general-purpose ML frameworks (BentoML, MLFlow, and MLServer).
Practical Forecasting of Cryptocoins Timeseries using Correlation Patterns
Sep 05, 2024
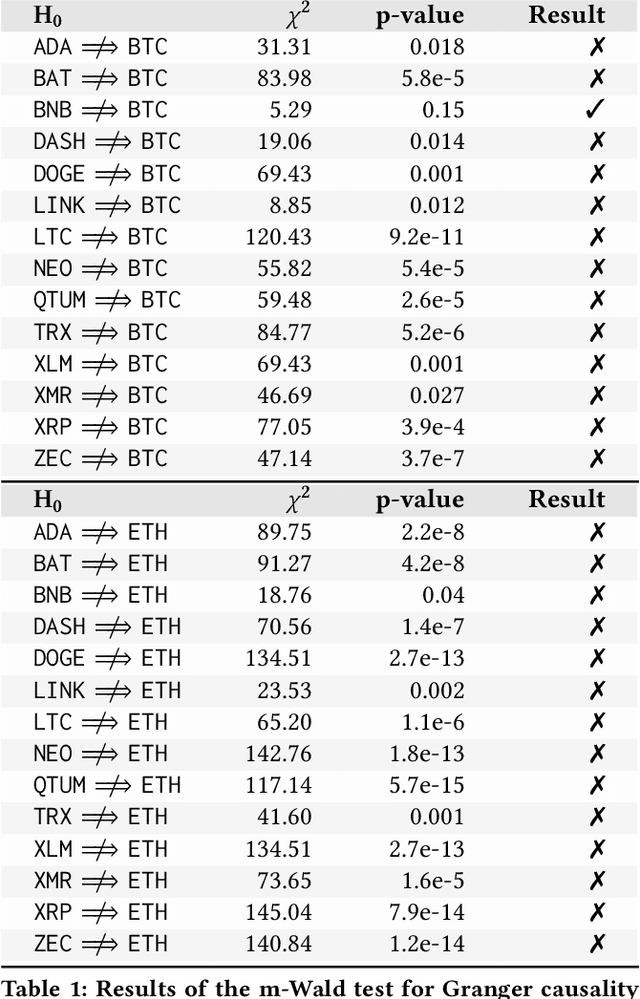
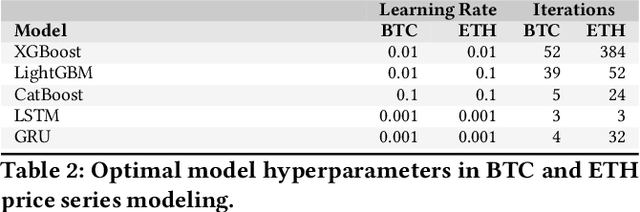

Cryptocoins (i.e., Bitcoin, Ether, Litecoin) are tradable digital assets. Ownerships of cryptocoins are registered on distributed ledgers (i.e., blockchains). Secure encryption techniques guarantee the security of the transactions (transfers of coins among owners), registered into the ledger. Cryptocoins are exchanged for specific trading prices. The extreme volatility of such trading prices across all different sets of crypto-assets remains undisputed. However, the relations between the trading prices across different cryptocoins remains largely unexplored. Major coin exchanges indicate trend correlation to advise for sells or buys. However, price correlations remain largely unexplored. We shed some light on the trend correlations across a large variety of cryptocoins, by investigating their coin/price correlation trends over the past two years. We study the causality between the trends, and exploit the derived correlations to understand the accuracy of state-of-the-art forecasting techniques for time series modeling (e.g., GBMs, LSTM and GRU) of correlated cryptocoins. Our evaluation shows (i) strong correlation patterns between the most traded coins (e.g., Bitcoin and Ether) and other types of cryptocurrencies, and (ii) state-of-the-art time series forecasting algorithms can be used to forecast cryptocoins price trends. We released datasets and code to reproduce our analysis to the research community.
Mitigating Adversarial Attacks in Federated Learning with Trusted Execution Environments
Sep 13, 2023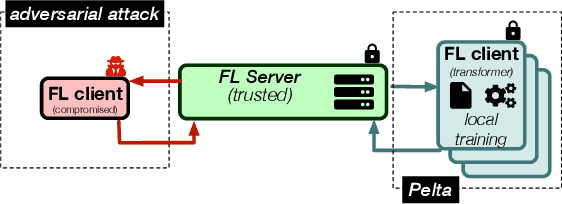
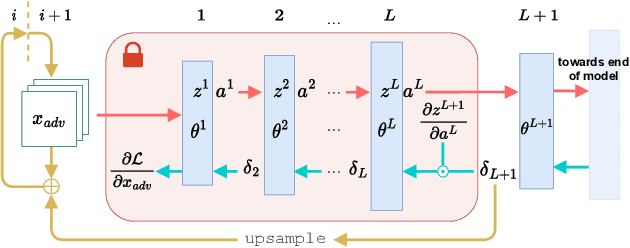
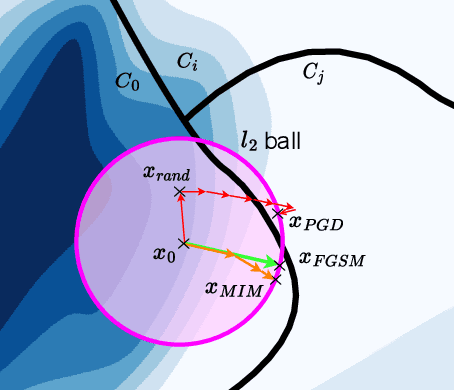

The main premise of federated learning (FL) is that machine learning model updates are computed locally to preserve user data privacy. This approach avoids by design user data to ever leave the perimeter of their device. Once the updates aggregated, the model is broadcast to all nodes in the federation. However, without proper defenses, compromised nodes can probe the model inside their local memory in search for adversarial examples, which can lead to dangerous real-world scenarios. For instance, in image-based applications, adversarial examples consist of images slightly perturbed to the human eye getting misclassified by the local model. These adversarial images are then later presented to a victim node's counterpart model to replay the attack. Typical examples harness dissemination strategies such as altered traffic signs (patch attacks) no longer recognized by autonomous vehicles or seemingly unaltered samples that poison the local dataset of the FL scheme to undermine its robustness. Pelta is a novel shielding mechanism leveraging Trusted Execution Environments (TEEs) that reduce the ability of attackers to craft adversarial samples. Pelta masks inside the TEE the first part of the back-propagation chain rule, typically exploited by attackers to craft the malicious samples. We evaluate Pelta on state-of-the-art accurate models using three well-established datasets: CIFAR-10, CIFAR-100 and ImageNet. We show the effectiveness of Pelta in mitigating six white-box state-of-the-art adversarial attacks, such as Projected Gradient Descent, Momentum Iterative Method, Auto Projected Gradient Descent, the Carlini & Wagner attack. In particular, Pelta constitutes the first attempt at defending an ensemble model against the Self-Attention Gradient attack to the best of our knowledge. Our code is available to the research community at https://github.com/queyrusi/Pelta.
VEDLIoT -- Next generation accelerated AIoT systems and applications
May 09, 2023The VEDLIoT project aims to develop energy-efficient Deep Learning methodologies for distributed Artificial Intelligence of Things (AIoT) applications. During our project, we propose a holistic approach that focuses on optimizing algorithms while addressing safety and security challenges inherent to AIoT systems. The foundation of this approach lies in a modular and scalable cognitive IoT hardware platform, which leverages microserver technology to enable users to configure the hardware to meet the requirements of a diverse array of applications. Heterogeneous computing is used to boost performance and energy efficiency. In addition, the full spectrum of hardware accelerators is integrated, providing specialized ASICs as well as FPGAs for reconfigurable computing. The project's contributions span across trusted computing, remote attestation, and secure execution environments, with the ultimate goal of facilitating the design and deployment of robust and efficient AIoT systems. The overall architecture is validated on use-cases ranging from Smart Home to Automotive and Industrial IoT appliances. Ten additional use cases are integrated via an open call, broadening the range of application areas.
* This publication incorporates results from the VEDLIoT project, which received funding from the European Union's Horizon 2020 research and innovation programme under grant agreement No 957197. CF'23: 20th ACM International Conference on Computing Frontiers, May 2023, Bologna, Italy
Plinius: Secure and Persistent Machine Learning Model Training
Apr 08, 2021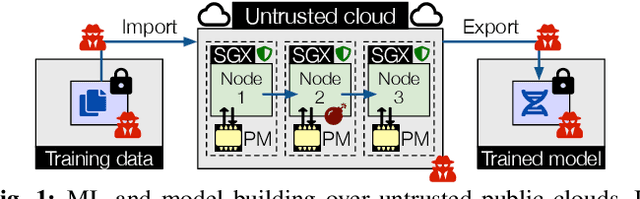

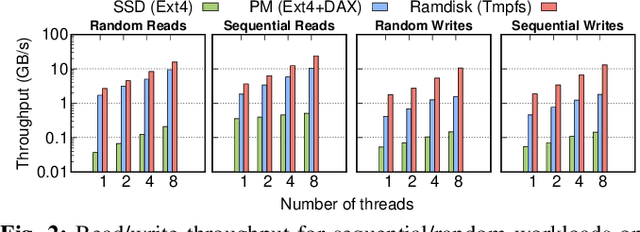
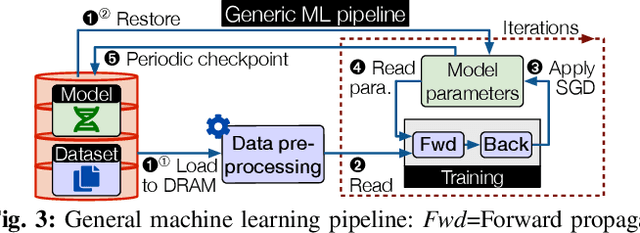
With the increasing popularity of cloud based machine learning (ML) techniques there comes a need for privacy and integrity guarantees for ML data. In addition, the significant scalability challenges faced by DRAM coupled with the high access-times of secondary storage represent a huge performance bottleneck for ML systems. While solutions exist to tackle the security aspect, performance remains an issue. Persistent memory (PM) is resilient to power loss (unlike DRAM), provides fast and fine-granular access to memory (unlike disk storage) and has latency and bandwidth close to DRAM (in the order of ns and GB/s, respectively). We present PLINIUS, a ML framework using Intel SGX enclaves for secure training of ML models and PM for fault tolerance guarantees. P LINIUS uses a novel mirroring mechanism to create and maintain (i) encrypted mirror copies of ML models on PM, and (ii) encrypted training data in byte-addressable PM, for near-instantaneous data recovery after a system failure. Compared to disk-based checkpointing systems,PLINIUS is 3.2x and 3.7x faster respectively for saving and restoring models on real PM hardware, achieving robust and secure ML model training in SGX enclaves.