 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Cost of Model-Serving Frameworks: An Experimental Evaluation
Nov 15, 2024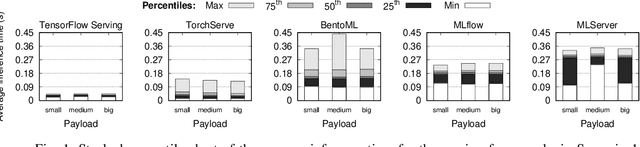
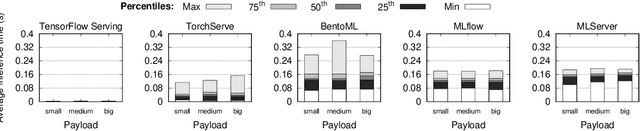
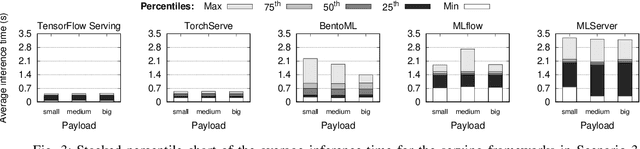
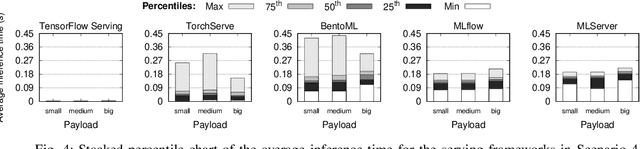
In machine learning (ML), the inference phase is the process of applying pre-trained models to new, unseen data with the objective of making predictions. During the inference phase, end-users interact with ML services to gain insights, recommendations, or actions based on the input data. For this reason, serving strategies are nowadays crucial for deploying and managing models in production environments effectively. These strategies ensure that models are available, scalable, reliable, and performant for real-world applications, such as time series forecasting, image classification, natural language processing, and so on. In this paper, we evaluate the performances of five widely-used model serving frameworks (TensorFlow Serving, TorchServe, MLServer, MLflow, and BentoML) under four different scenarios (malware detection, cryptocoin prices forecasting, image classification, and sentiment analysis). We demonstrate that TensorFlow Serving is able to outperform all the other frameworks in serving deep learning (DL) models. Moreover, we show that DL-specific frameworks (TensorFlow Serving and TorchServe) display significantly lower latencies than the three general-purpose ML frameworks (BentoML, MLFlow, and MLServer).