 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-Tester: Training Open-Source LLMs for Issue Reproduction in Real-World Repositories
Jan 20, 2026Software testing is crucial for ensuring the correctness and reliability of software systems. Automated generation of issue reproduction tests from natural language issue descriptions enhances developer productivity by simplifying root cause analysis, promotes test-driven development -- "test first, write code later", and can be used for improving the effectiveness of automated issue resolution systems like coding agents. Existing methods proposed for this task predominantly rely on closed-source LLMs, with limited exploration of open models. To address this, we propose SWE-Tester -- a novel pipeline for training open-source LLMs to generate issue reproduction tests. First, we curate a high-quality training dataset of 41K instances from 2.6K open-source GitHub repositories and use it to train LLMs of varying sizes and families. The fine-tuned models achieve absolute improvements of up to 10\% in success rate and 21\% in change coverage on SWT-Bench Verified. Further analysis shows consistent improvements with increased inference-time compute, more data, and larger models. These results highlight the effectiveness of our framework for advancing open-source LLMs in this domain.
Action Shapley: A Training Data Selection Metric for World Model in Reinforcement Learning
Jan 15, 2026Numerous offline and model-based reinforcement learning systems incorporate world models to emulate the inherent environments. A world model is particularly important in scenarios where direct interactions with the real environment is costly, dangerous, or impractical. The efficacy and interpretability of such world models are notably contingent upon the quality of the underlying training data. In this context, we introduce Action Shapley as an agnostic metric for the judicious and unbiased selection of training data. To facilitate the computation of Action Shapley, we present a randomized dynamic algorithm specifically designed to mitigate the exponential complexity inherent in traditional Shapley value computations. Through empirical validation across five data-constrained real-world case studies, the algorithm demonstrates a computational efficiency improvement exceeding 80\% in comparison to conventional exponential time computations. Furthermore, our Action Shapley-based training data selection policy consistently outperforms ad-hoc training data selection.
Go-UT-Bench: A Fine-Tuning Dataset for LLM-Based Unit Test Generation in Go
Nov 14, 2025Training data imbalance poses a major challenge for code LLMs. Most available data heavily over represents raw opensource code while underrepresenting broader software engineering tasks, especially in low resource languages like Golang. As a result, models excel at code autocompletion but struggle with real world developer workflows such as unit test generation. To address this gap, we introduce GO UT Bench, a benchmark dataset of 5264 pairs of code and unit tests, drawn from 10 permissively licensed Golang repositories spanning diverse domain. We evaluate its effectiveness as a fine tuning dataset across two LLM families i.e. mixture of experts and dense decoders. Our results show that finetuned models outperform their base counterparts on more than 75% of benchmark tasks.
A Multi-Agent Framework for Stateful Inference-Time Search
Oct 08, 2025



Recent work explores agentic inference-time techniques to perform structured, multi-step reasoning. However, stateless inference often struggles on multi-step tasks due to the absence of persistent state. Moreover, task-specific fine-tuning or instruction-tuning often achieve surface-level code generation but remain brittle on tasks requiring deeper reasoning and long-horizon dependencies. To address these limitations, we propose stateful multi-agent evolutionary search, a training-free framework that departs from prior stateless approaches by combining (i) persistent inference-time state, (ii) adversarial mutation, and (iii) evolutionary preservation. We demonstrate its effectiveness in automated unit test generation through the generation of edge cases. We generate robust edge cases using an evolutionary search process, where specialized agents sequentially propose, mutate, and score candidates. A controller maintains persistent state across generations, while evolutionary preservation ensures diversity and exploration across all possible cases. This yields a generalist agent capable of discovering robust, high-coverage edge cases across unseen codebases. Experiments show our stateful multi-agent inference framework achieves substantial gains in coverage over stateless single-step baselines, evaluated on prevalent unit-testing benchmarks such as HumanEval and TestGenEvalMini and using three diverse LLM families - Llama, Gemma, and GPT. These results indicate that combining persistent inference-time state with evolutionary search materially improves unit-test generation.
Predictive Scaling Laws for Efficient GRPO Training of Large Reasoning Models
Jul 24, 2025Fine-tuning large language models (LLMs) for reasoning tasks using reinforcement learning methods like Group Relative Policy Optimization (GRPO) is computationally expensive. To address this, we propose a predictive framework that models training dynamics and helps optimize resource usage. Through experiments on Llama and Qwen models (3B 8B), we derive an empirical scaling law based on model size, initial performance, and training progress. This law predicts reward trajectories and identifies three consistent training phases: slow start, rapid improvement, and plateau. We find that training beyond certain number of an epoch offers little gain, suggesting earlier stopping can significantly reduce compute without sacrificing performance. Our approach generalizes across model types, providing a practical guide for efficient GRPO-based fine-tuning.
CPP-UT-Bench: Can LLMs Write Complex Unit Tests in C++?
Dec 03, 2024
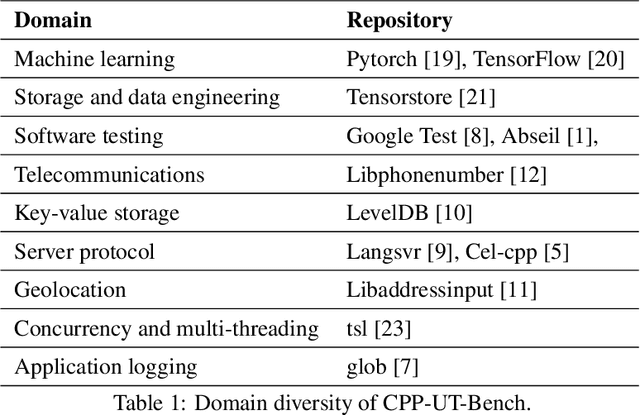
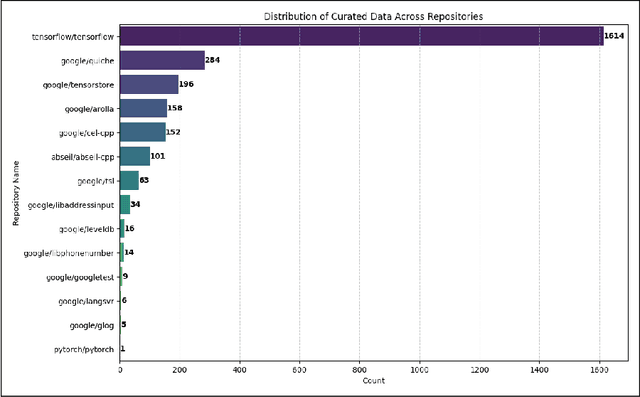
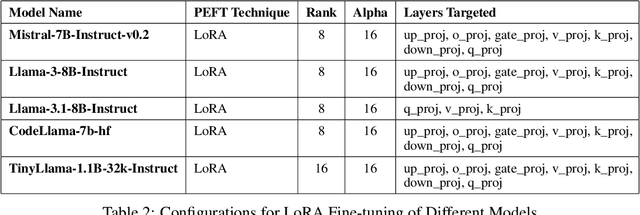
We introduce CPP-UT-Bench, a benchmark dataset to measure C++ unit test generation capability of a large language model (LLM). CPP-UT-Bench aims to reflect a broad and diverse set of C++ codebases found in the real world. The dataset includes 2,653 {code, unit test} pairs drawn from 14 different opensource C++ codebases spanned across nine diverse domains including machine learning, software testing, parsing, standard input-output, data engineering, logging, complete expression evaluation, key value storage, and server protocols. We demonstrated the effectiveness of CPP-UT-Bench as a benchmark dataset through extensive experiments in in-context learning, parameter-efficient fine-tuning (PEFT), and full-parameter fine-tuning. We also discussed the challenges of the dataset compilation and insights we learned from in-context learning and fine-tuning experiments. Besides the CPP-UT-Bench dataset and data compilation code, we are also offering the fine-tuned model weights for further research. For nine out of ten experiments, our fine-tuned LLMs outperformed the corresponding base models by an average of more than 70%.
Efficient Alignment of Large Language Models via Data Sampling
Nov 15, 2024LLM alignment ensures that large language models behave safely and effectively by aligning their outputs with human values, goals, and intentions. Aligning LLMs employ huge amounts of data, computation, and time. Moreover, curating data with human feedback is expensive and takes time. Recent research depicts the benefit of data engineering in the fine-tuning and pre-training paradigms to bring down such costs. However, alignment differs from the afore-mentioned paradigms and it is unclear if data efficient alignment is feasible. In this work, we first aim to understand how the performance of LLM alignment scales with data. We find out that LLM alignment performance follows an exponential plateau pattern which tapers off post a rapid initial increase. Based on this, we identify data subsampling as a viable method to reduce resources required for alignment. Further, we propose an information theory-based methodology for efficient alignment by identifying a small high quality subset thereby reducing the computation and time required by alignment. We evaluate the proposed methodology over multiple datasets and compare the results. We find that the model aligned using our proposed methodology outperforms other sampling methods and performs comparable to the model aligned with the full dataset while using less than 10% data, leading to greater than 90% savings in costs, resources, and faster LLM alignment.
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
Data-Driven Evaluation of Training Action Space for Reinforcement Learning
Apr 08, 2022

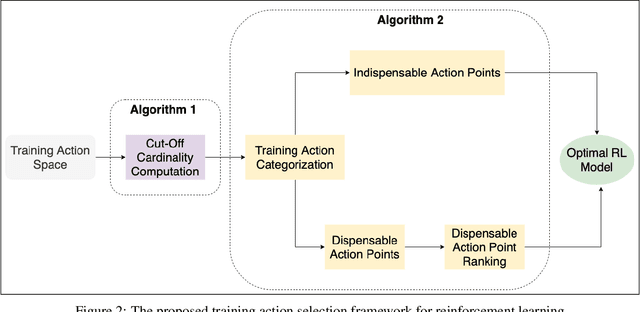

Training action space selection for reinforcement learning (RL) is conflict-prone due to complex state-action relationships. To address this challenge, this paper proposes a Shapley-inspired methodology for training action space categorization and ranking. To reduce exponential-time shapley computations, the methodology includes a Monte Carlo simulation to avoid unnecessary explorations. The effectiveness of the methodology is illustrated using a cloud infrastructure resource tuning case study. It reduces the search space by 80\% and categorizes the training action sets into dispensable and indispensable groups. Additionally, it ranks different training actions to facilitate high-performance yet cost-efficient RL model design. The proposed data-driven methodology is extensible to different domains, use cases, and reinforcement learning algorithms.