 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStacMR: Scene-Text Aware Cross-Modal Retrieval
Dec 08, 2020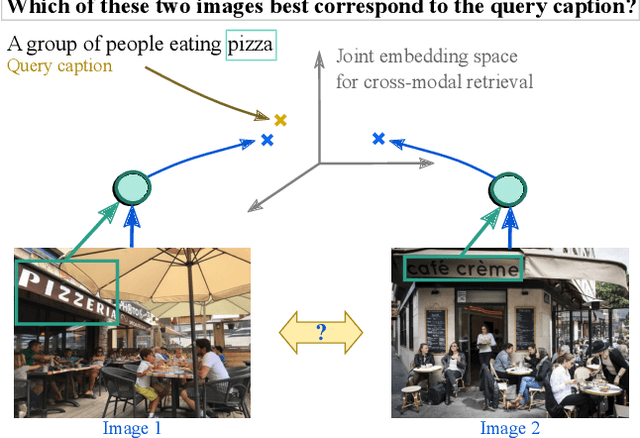
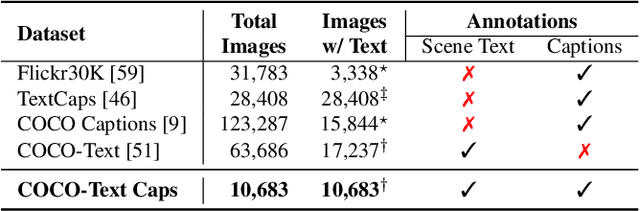
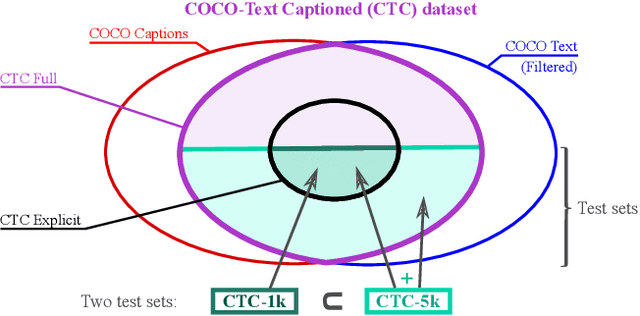
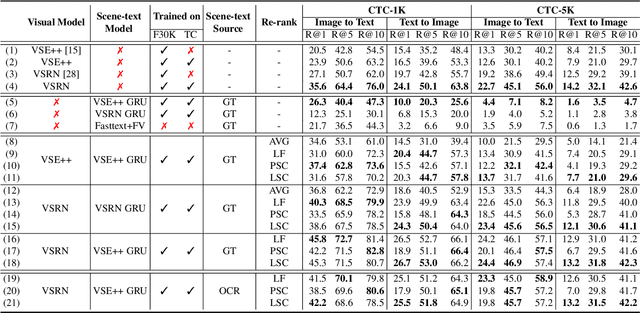
Recent models for cross-modal retrieval have benefited from an increasingly rich understanding of visual scenes, afforded by scene graphs and object interactions to mention a few. This has resulted in an improved matching between the visual representation of an image and the textual representation of its caption. Yet, current visual representations overlook a key aspect: the text appearing in images, which may contain crucial information for retrieval. In this paper, we first propose a new dataset that allows exploration of cross-modal retrieval where images contain scene-text instances. Then, armed with this dataset, we describe several approaches which leverage scene text, including a better scene-text aware cross-modal retrieval method which uses specialized representations for text from the captions and text from the visual scene, and reconcile them in a common embedding space. Extensive experiments confirm that cross-modal retrieval approaches benefit from scene text and highlight interesting research questions worth exploring further. Dataset and code are available at http://europe.naverlabs.com/stacmr
Multimodal grid features and cell pointers for Scene Text Visual Question Answering
Jun 25, 2020
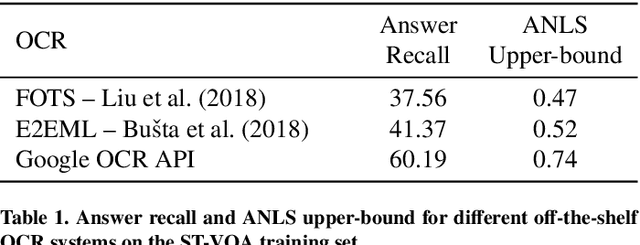
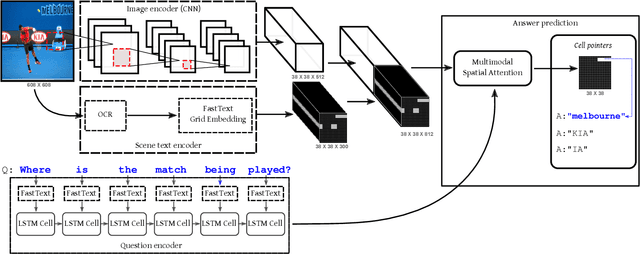
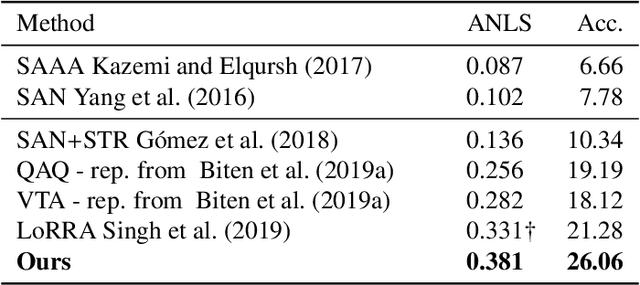
This paper presents a new model for the task of scene text visual question answering, in which questions about a given image can only be answered by reading and understanding scene text that is present in it. The proposed model is based on an attention mechanism that attends to multi-modal features conditioned to the question, allowing it to reason jointly about the textual and visual modalities in the scene. The output weights of this attention module over the grid of multi-modal spatial features are interpreted as the probability that a certain spatial location of the image contains the answer text the to the given question. Our experiments demonstrate competitive performance in two standard datasets. Furthermore, this paper provides a novel analysis of the ST-VQA dataset based on a human performance study.
Single Shot Scene Text Retrieval
Aug 27, 2018

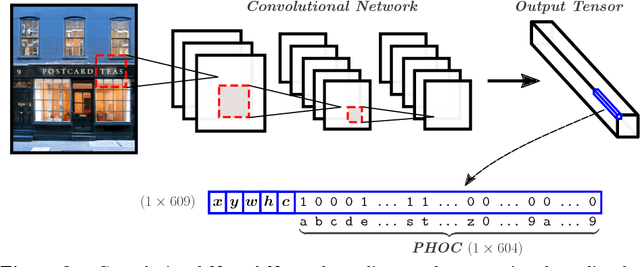
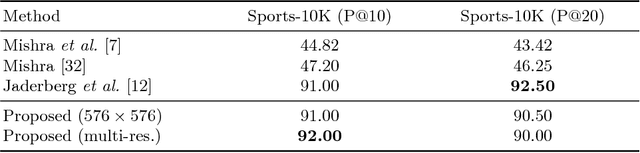
Textual information found in scene images provides high level semantic information about the image and its context and it can be leveraged for better scene understanding. In this paper we address the problem of scene text retrieval: given a text query, the system must return all images containing the queried text. The novelty of the proposed model consists in the usage of a single shot CNN architecture that predicts at the same time bounding boxes and a compact text representation of the words in them. In this way, the text based image retrieval task can be casted as a simple nearest neighbor search of the query text representation over the outputs of the CNN over the entire image database. Our experiments demonstrate that the proposed architecture outperforms previous state-of-the-art while it offers a significant increase in processing speed.