 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Shot Scene Text Retrieval
Paper and Code


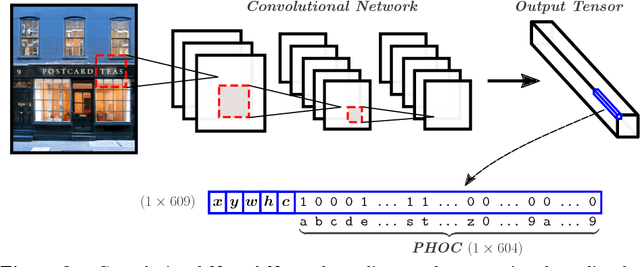
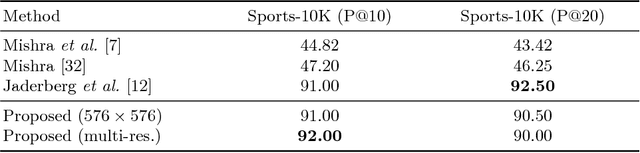
Textual information found in scene images provides high level semantic information about the image and its context and it can be leveraged for better scene understanding. In this paper we address the problem of scene text retrieval: given a text query, the system must return all images containing the queried text. The novelty of the proposed model consists in the usage of a single shot CNN architecture that predicts at the same time bounding boxes and a compact text representation of the words in them. In this way, the text based image retrieval task can be casted as a simple nearest neighbor search of the query text representation over the outputs of the CNN over the entire image database. Our experiments demonstrate that the proposed architecture outperforms previous state-of-the-art while it offers a significant increase in processing speed.