 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Semi-Supervised Learning for Text Recognition
Paper and Code
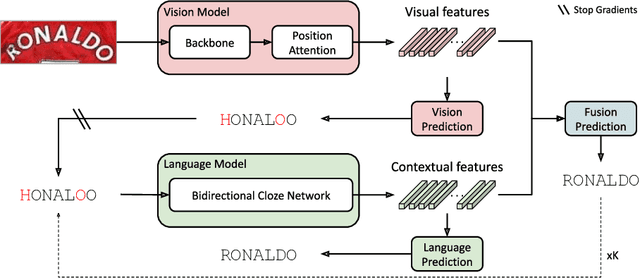
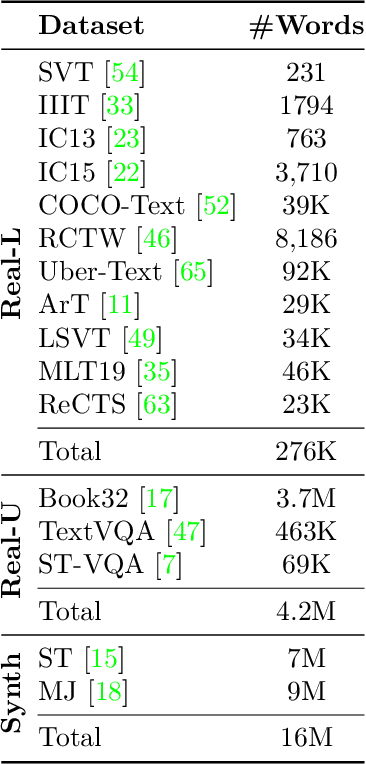
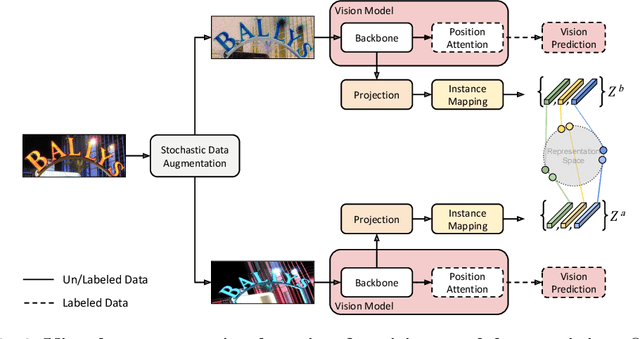
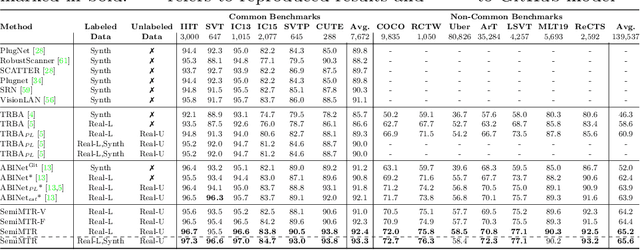
Until recently, the number of public real-world text images was insufficient for training scene text recognizers. Therefore, most modern training methods rely on synthetic data and operate in a fully supervised manner. Nevertheless, the amount of public real-world text images has increased significantly lately, including a great deal of unlabeled data. Leveraging these resources requires semi-supervised approaches; however, the few existing methods do not account for vision-language multimodality structure and therefore suboptimal for state-of-the-art multimodal architectures. To bridge this gap, we present semi-supervised learning for multimodal text recognizers (SemiMTR) that leverages unlabeled data at each modality training phase. Notably, our method refrains from extra training stages and maintains the current three-stage multimodal training procedure. Our algorithm starts by pretraining the vision model through a single-stage training that unifies self-supervised learning with supervised training. More specifically, we extend an existing visual representation learning algorithm and propose the first contrastive-based method for scene text recognition. After pretraining the language model on a text corpus, we fine-tune the entire network via a sequential, character-level, consistency regularization between weakly and strongly augmented views of text images. In a novel setup, consistency is enforced on each modality separately. Extensive experiments validate that our method outperforms the current training schemes and achieves state-of-the-art results on multiple scene text recognition benchmarks.