 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMocap Anywhere: Towards Pairwise-Distance based Motion Capture in the Wild (for the Wild)
Jan 27, 2026We introduce a novel motion capture system that reconstructs full-body 3D motion using only sparse pairwise distance (PWD) measurements from body-mounted(UWB) sensors. Using time-of-flight ranging between wireless nodes, our method eliminates the need for external cameras, enabling robust operation in uncontrolled and outdoor environments. Unlike traditional optical or inertial systems, our approach is shape-invariant and resilient to environmental constraints such as lighting and magnetic interference. At the core of our system is Wild-Poser (WiP for short), a compact, real-time Transformer-based architecture that directly predicts 3D joint positions from noisy or corrupted PWD measurements, which can later be used for joint rotation reconstruction via learned methods. WiP generalizes across subjects of varying morphologies, including non-human species, without requiring individual body measurements or shape fitting. Operating in real time, WiP achieves low joint position error and demonstrates accurate 3D motion reconstruction for both human and animal subjects in-the-wild. Our empirical analysis highlights its potential for scalable, low-cost, and general purpose motion capture in real-world settings.
VisFocus: Prompt-Guided Vision Encoders for OCR-Free Dense Document Understanding
Jul 17, 2024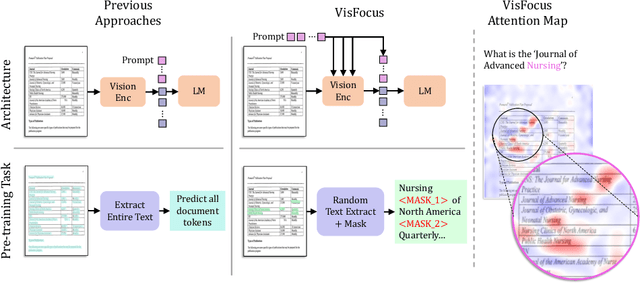
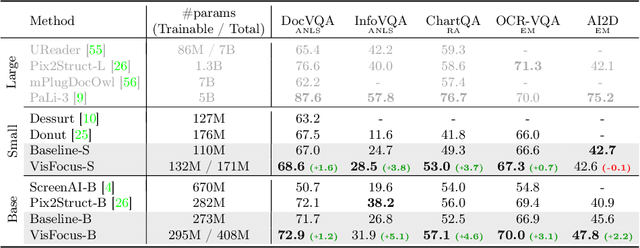
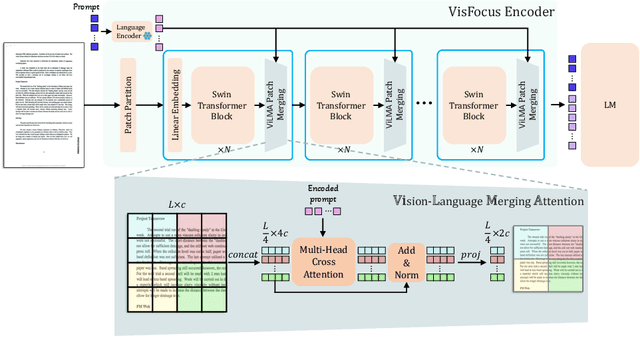

In recent years, notable advancements have been made in the domain of visual document understanding, with the prevailing architecture comprising a cascade of vision and language models. The text component can either be extracted explicitly with the use of external OCR models in OCR-based approaches, or alternatively, the vision model can be endowed with reading capabilities in OCR-free approaches. Typically, the queries to the model are input exclusively to the language component, necessitating the visual features to encompass the entire document. In this paper, we present VisFocus, an OCR-free method designed to better exploit the vision encoder's capacity by coupling it directly with the language prompt. To do so, we replace the down-sampling layers with layers that receive the input prompt and allow highlighting relevant parts of the document, while disregarding others. We pair the architecture enhancements with a novel pre-training task, using language masking on a snippet of the document text fed to the visual encoder in place of the prompt, to empower the model with focusing capabilities. Consequently, VisFocus learns to allocate its attention to text patches pertinent to the provided prompt. Our experiments demonstrate that this prompt-guided visual encoding approach significantly improves performance, achieving state-of-the-art results on various benchmarks.
PromptonomyViT: Multi-Task Prompt Learning Improves Video Transformers using Synthetic Scene Data
Dec 08, 2022



Action recognition models have achieved impressive results by incorporating scene-level annotations, such as objects, their relations, 3D structure, and more. However, obtaining annotations of scene structure for videos requires a significant amount of effort to gather and annotate, making these methods expensive to train. In contrast, synthetic datasets generated by graphics engines provide powerful alternatives for generating scene-level annotations across multiple tasks. In this work, we propose an approach to leverage synthetic scene data for improving video understanding. We present a multi-task prompt learning approach for video transformers, where a shared video transformer backbone is enhanced by a small set of specialized parameters for each task. Specifically, we add a set of ``task prompts'', each corresponding to a different task, and let each prompt predict task-related annotations. This design allows the model to capture information shared among synthetic scene tasks as well as information shared between synthetic scene tasks and a real video downstream task throughout the entire network. We refer to this approach as ``Promptonomy'', since the prompts model a task-related structure. We propose the PromptonomyViT model (PViT), a video transformer that incorporates various types of scene-level information from synthetic data using the ``Promptonomy'' approach. PViT shows strong performance improvements on multiple video understanding tasks and datasets.