 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptonomyViT: Multi-Task Prompt Learning Improves Video Transformers using Synthetic Scene Data
Dec 08, 2022



Action recognition models have achieved impressive results by incorporating scene-level annotations, such as objects, their relations, 3D structure, and more. However, obtaining annotations of scene structure for videos requires a significant amount of effort to gather and annotate, making these methods expensive to train. In contrast, synthetic datasets generated by graphics engines provide powerful alternatives for generating scene-level annotations across multiple tasks. In this work, we propose an approach to leverage synthetic scene data for improving video understanding. We present a multi-task prompt learning approach for video transformers, where a shared video transformer backbone is enhanced by a small set of specialized parameters for each task. Specifically, we add a set of ``task prompts'', each corresponding to a different task, and let each prompt predict task-related annotations. This design allows the model to capture information shared among synthetic scene tasks as well as information shared between synthetic scene tasks and a real video downstream task throughout the entire network. We refer to this approach as ``Promptonomy'', since the prompts model a task-related structure. We propose the PromptonomyViT model (PViT), a video transformer that incorporates various types of scene-level information from synthetic data using the ``Promptonomy'' approach. PViT shows strong performance improvements on multiple video understanding tasks and datasets.
Structured Video Tokens @ Ego4D PNR Temporal Localization Challenge 2022
Jun 15, 2022


This technical report describes the SViT approach for the Ego4D Point of No Return (PNR) Temporal Localization Challenge. We propose a learning framework StructureViT (SViT for short), which demonstrates how utilizing the structure of a small number of images only available during training can improve a video model. SViT relies on two key insights. First, as both images and videos contain structured information, we enrich a transformer model with a set of \emph{object tokens} that can be used across images and videos. Second, the scene representations of individual frames in video should "align" with those of still images. This is achieved via a "Frame-Clip Consistency" loss, which ensures the flow of structured information between images and videos. SViT obtains strong performance on the challenge test set with 0.656 absolute temporal localization error.
Bringing Image Scene Structure to Video via Frame-Clip Consistency of Object Tokens
Jun 15, 2022


Recent action recognition models have achieved impressive results by integrating objects, their locations and interactions. However, obtaining dense structured annotations for each frame is tedious and time-consuming, making these methods expensive to train and less scalable. At the same time, if a small set of annotated images is available, either within or outside the domain of interest, how could we leverage these for a video downstream task? We propose a learning framework StructureViT (SViT for short), which demonstrates how utilizing the structure of a small number of images only available during training can improve a video model. SViT relies on two key insights. First, as both images and videos contain structured information, we enrich a transformer model with a set of \emph{object tokens} that can be used across images and videos. Second, the scene representations of individual frames in video should "align" with those of still images. This is achieved via a \emph{Frame-Clip Consistency} loss, which ensures the flow of structured information between images and videos. We explore a particular instantiation of scene structure, namely a \emph{Hand-Object Graph}, consisting of hands and objects with their locations as nodes, and physical relations of contact/no-contact as edges. SViT shows strong performance improvements on multiple video understanding tasks and datasets. Furthermore, it won in the Ego4D CVPR'22 Object State Localization challenge. For code and pretrained models, visit the project page at \url{https://eladb3.github.io/SViT/}
Object-Region Video Transformers
Oct 13, 2021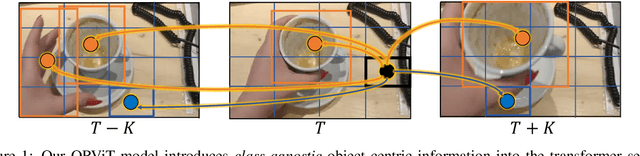


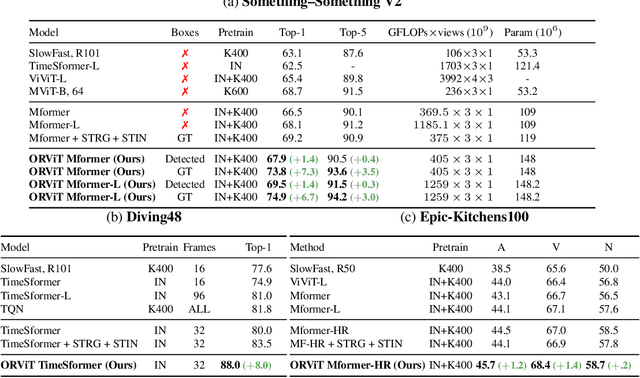
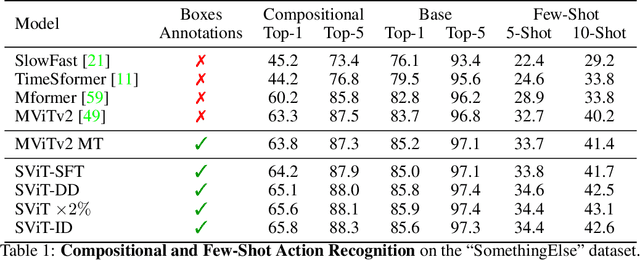
Evidence from cognitive psychology suggests that understanding spatio-temporal object interactions and dynamics can be essential for recognizing actions in complex videos. Therefore, action recognition models are expected to benefit from explicit modeling of objects, including their appearance, interaction, and dynamics. Recently, video transformers have shown great success in video understanding, exceeding CNN performance. Yet, existing video transformer models do not explicitly model objects. In this work, we present Object-Region Video Transformers (ORViT), an \emph{object-centric} approach that extends video transformer layers with a block that directly incorporates object representations. The key idea is to fuse object-centric spatio-temporal representations throughout multiple transformer layers. Our ORViT block consists of two object-level streams: appearance and dynamics. In the appearance stream, an ``Object-Region Attention'' element applies self-attention over the patches and \emph{object regions}. In this way, visual object regions interact with uniform patch tokens and enrich them with contextualized object information. We further model object dynamics via a separate ``Object-Dynamics Module'', which captures trajectory interactions, and show how to integrate the two streams. We evaluate our model on standard and compositional action recognition on Something-Something V2, standard action recognition on Epic-Kitchen100 and Diving48, and spatio-temporal action detection on AVA. We show strong improvement in performance across all tasks and datasets considered, demonstrating the value of a model that incorporates object representations into a transformer architecture. For code and pretrained models, visit the project page at https://roeiherz.github.io/ORViT/.