 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Models that Can See and Read
Paper and Code
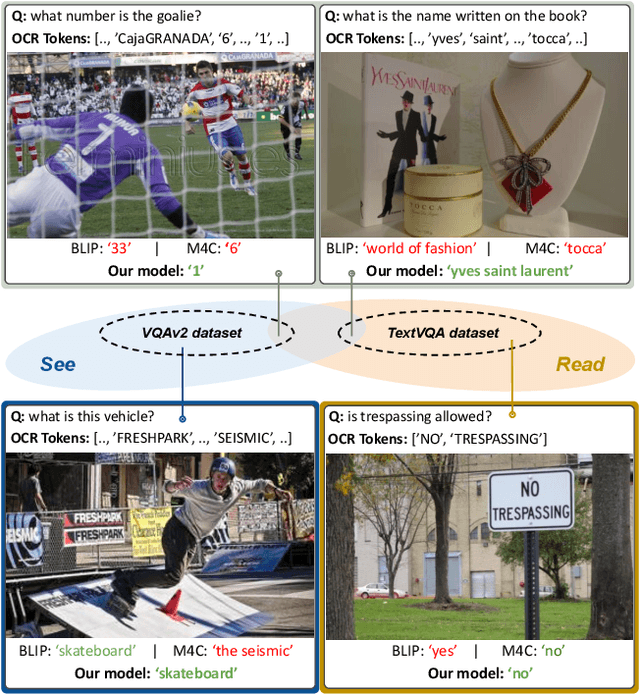
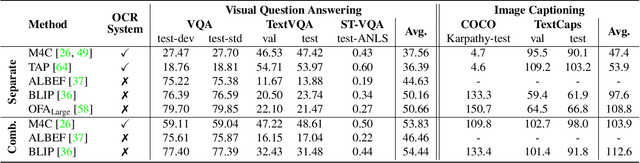
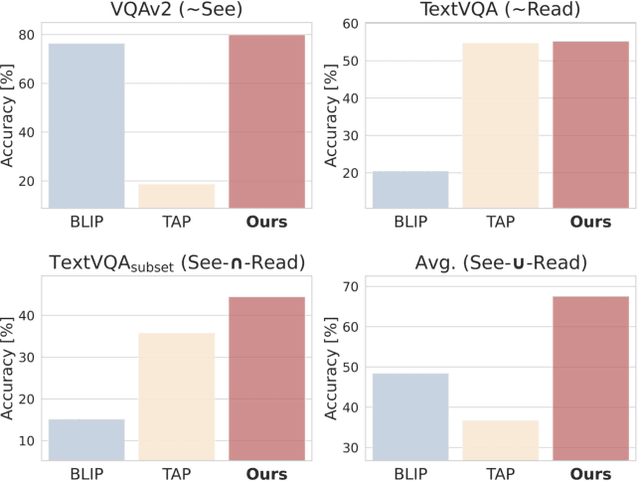

Visual Question Answering (VQA) and Image Captioning (CAP), which are among the most popular vision-language tasks, have analogous scene-text versions that require reasoning from the text in the image. Despite the obvious resemblance between them, the two are treated independently, yielding task-specific methods that can either see or read, but not both. In this work, we conduct an in-depth analysis of this phenomenon and propose UniTNT, a Unified Text-Non-Text approach, which grants existing multimodal architectures scene-text understanding capabilities. Specifically, we treat scene-text information as an additional modality, fusing it with any pretrained encoder-decoder-based architecture via designated modules. Thorough experiments reveal that UniTNT leads to the first single model that successfully handles both task types. Moreover, we show that scene-text understanding capabilities can boost vision-language models' performance on VQA and CAP by up to 3.49% and 0.7 CIDEr, respectively.