 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirectProbe: Studying Representations without Classifiers
Paper and Code


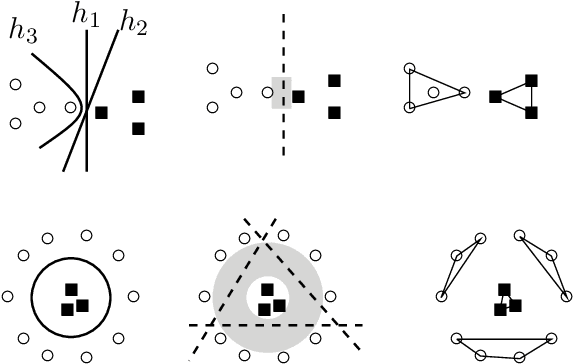

Understanding how linguistic structures are encoded in contextualized embedding could help explain their impressive performance across NLP@. Existing approaches for probing them usually call for training classifiers and use the accuracy, mutual information, or complexity as a proxy for the representation's goodness. In this work, we argue that doing so can be unreliable because different representations may need different classifiers. We develop a heuristic, DirectProbe, that directly studies the geometry of a representation by building upon the notion of a version space for a task. Experiments with several linguistic tasks and contextualized embeddings show that, even without training classifiers, DirectProbe can shine light into how an embedding space represents labels, and also anticipate classifier performance for the representation.