 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent temporal abstractions in autoregressive models enable hierarchical reinforcement learning
Dec 24, 2025Large-scale autoregressive models pretrained on next-token prediction and finetuned with reinforcement learning (RL) have achieved unprecedented success on many problem domains. During RL, these models explore by generating new outputs, one token at a time. However, sampling actions token-by-token can result in highly inefficient learning, particularly when rewards are sparse. Here, we show that it is possible to overcome this problem by acting and exploring within the internal representations of an autoregressive model. Specifically, to discover temporally-abstract actions, we introduce a higher-order, non-causal sequence model whose outputs control the residual stream activations of a base autoregressive model. On grid world and MuJoCo-based tasks with hierarchical structure, we find that the higher-order model learns to compress long activation sequence chunks onto internal controllers. Critically, each controller executes a sequence of behaviorally meaningful actions that unfold over long timescales and are accompanied with a learned termination condition, such that composing multiple controllers over time leads to efficient exploration on novel tasks. We show that direct internal controller reinforcement, a process we term "internal RL", enables learning from sparse rewards in cases where standard RL finetuning fails. Our results demonstrate the benefits of latent action generation and reinforcement in autoregressive models, suggesting internal RL as a promising avenue for realizing hierarchical RL within foundation models.
Advancing Conversational Diagnostic AI with Multimodal Reasoning
May 06, 2025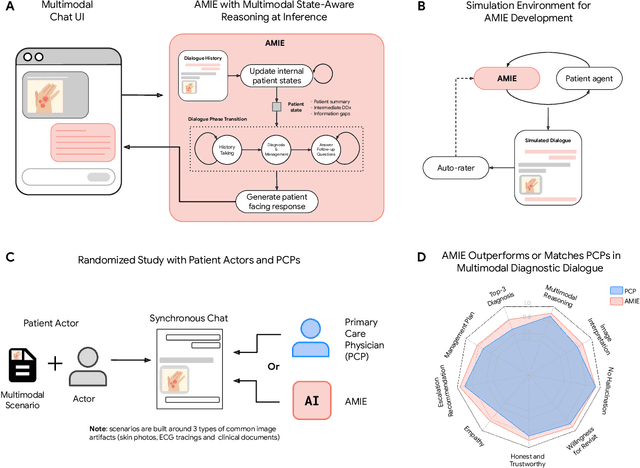
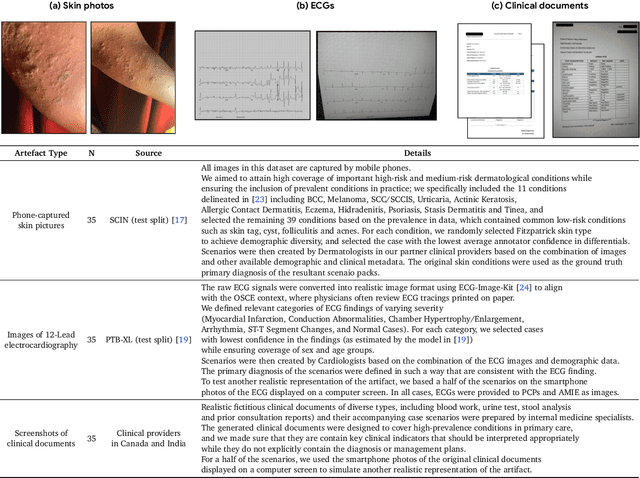
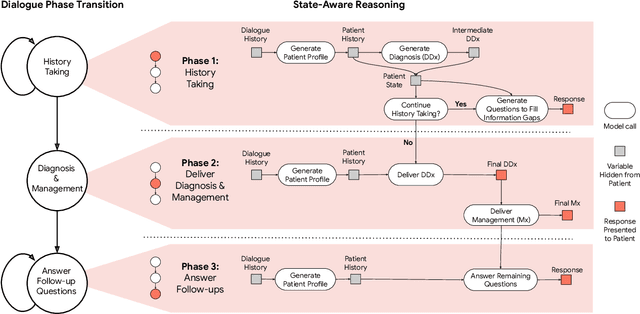
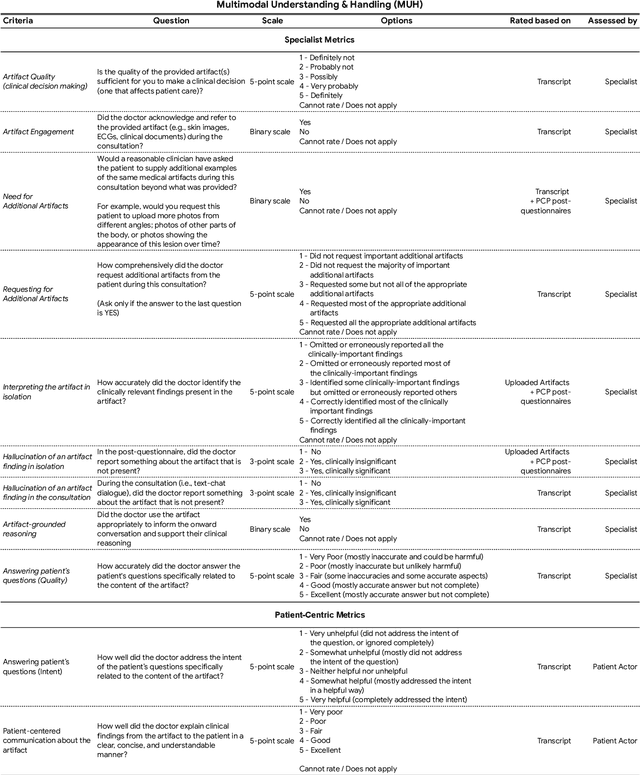
Large Language Models (LLMs) have demonstrated great potential for conducting diagnostic conversations but evaluation has been largely limited to language-only interactions, deviating from the real-world requirements of remote care delivery. Instant messaging platforms permit clinicians and patients to upload and discuss multimodal medical artifacts seamlessly in medical consultation, but the ability of LLMs to reason over such data while preserving other attributes of competent diagnostic conversation remains unknown. Here we advance the conversational diagnosis and management performance of the Articulate Medical Intelligence Explorer (AMIE) through a new capability to gather and interpret multimodal data, and reason about this precisely during consultations. Leveraging Gemini 2.0 Flash, our system implements a state-aware dialogue framework, where conversation flow is dynamically controlled by intermediate model outputs reflecting patient states and evolving diagnoses. Follow-up questions are strategically directed by uncertainty in such patient states, leading to a more structured multimodal history-taking process that emulates experienced clinicians. We compared AMIE to primary care physicians (PCPs) in a randomized, blinded, OSCE-style study of chat-based consultations with patient actors. We constructed 105 evaluation scenarios using artifacts like smartphone skin photos, ECGs, and PDFs of clinical documents across diverse conditions and demographics. Our rubric assessed multimodal capabilities and other clinically meaningful axes like history-taking, diagnostic accuracy, management reasoning, communication, and empathy. Specialist evaluation showed AMIE to be superior to PCPs on 7/9 multimodal and 29/32 non-multimodal axes (including diagnostic accuracy). The results show clear progress in multimodal conversational diagnostic AI, but real-world translation needs further research.
Artificial Intelligence Index Report 2025
Apr 08, 2025Welcome to the eighth edition of the AI Index report. The 2025 Index is our most comprehensive to date and arrives at an important moment, as AI's influence across society, the economy, and global governance continues to intensify. New in this year's report are in-depth analyses of the evolving landscape of AI hardware, novel estimates of inference costs, and new analyses of AI publication and patenting trends. We also introduce fresh data on corporate adoption of responsible AI practices, along with expanded coverage of AI's growing role in science and medicine. Since its founding in 2017 as an offshoot of the One Hundred Year Study of Artificial Intelligence, the AI Index has been committed to equipping policymakers, journalists, executives, researchers, and the public with accurate, rigorously validated, and globally sourced data. Our mission has always been to help these stakeholders make better-informed decisions about the development and deployment of AI. In a world where AI is discussed everywhere - from boardrooms to kitchen tables - this mission has never been more essential. The AI Index continues to lead in tracking and interpreting the most critical trends shaping the field - from the shifting geopolitical landscape and the rapid evolution of underlying technologies, to AI's expanding role in business, policymaking, and public life. Longitudinal tracking remains at the heart of our mission. In a domain advancing at breakneck speed, the Index provides essential context - helping us understand where AI stands today, how it got here, and where it may be headed next. Recognized globally as one of the most authoritative resources on artificial intelligence, the AI Index has been cited in major media outlets such as The New York Times, Bloomberg, and The Guardian; referenced in hundreds of academic papers; and used by policymakers and government agencies around the world.
Towards Conversational AI for Disease Management
Mar 08, 2025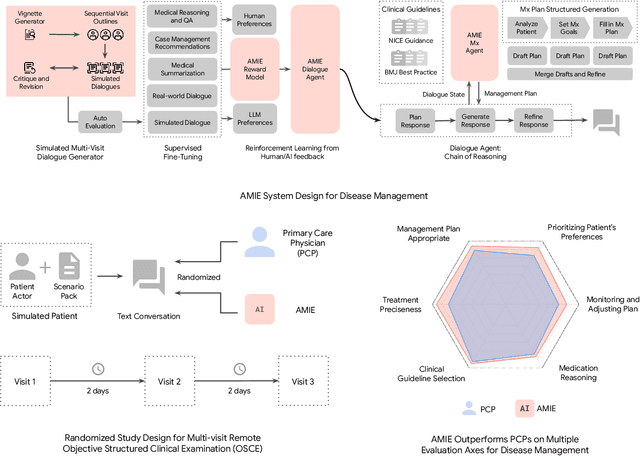

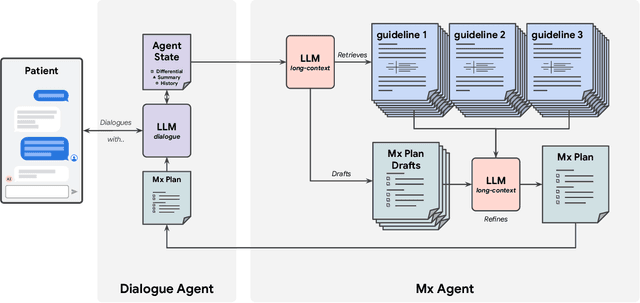
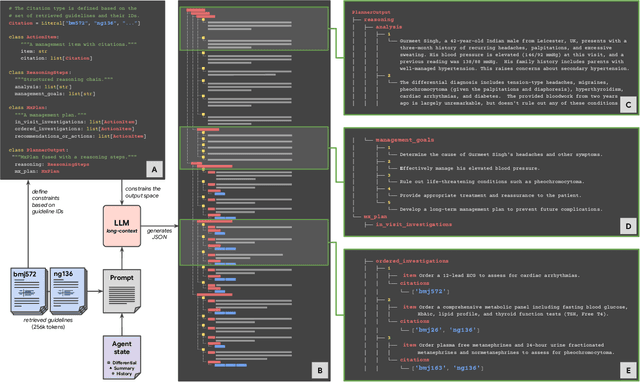
While large language models (LLMs) have shown promise in diagnostic dialogue, their capabilities for effective management reasoning - including disease progression, therapeutic response, and safe medication prescription - remain under-explored. We advance the previously demonstrated diagnostic capabilities of the Articulate Medical Intelligence Explorer (AMIE) through a new LLM-based agentic system optimised for clinical management and dialogue, incorporating reasoning over the evolution of disease and multiple patient visit encounters, response to therapy, and professional competence in medication prescription. To ground its reasoning in authoritative clinical knowledge, AMIE leverages Gemini's long-context capabilities, combining in-context retrieval with structured reasoning to align its output with relevant and up-to-date clinical practice guidelines and drug formularies. In a randomized, blinded virtual Objective Structured Clinical Examination (OSCE) study, AMIE was compared to 21 primary care physicians (PCPs) across 100 multi-visit case scenarios designed to reflect UK NICE Guidance and BMJ Best Practice guidelines. AMIE was non-inferior to PCPs in management reasoning as assessed by specialist physicians and scored better in both preciseness of treatments and investigations, and in its alignment with and grounding of management plans in clinical guidelines. To benchmark medication reasoning, we developed RxQA, a multiple-choice question benchmark derived from two national drug formularies (US, UK) and validated by board-certified pharmacists. While AMIE and PCPs both benefited from the ability to access external drug information, AMIE outperformed PCPs on higher difficulty questions. While further research would be needed before real-world translation, AMIE's strong performance across evaluations marks a significant step towards conversational AI as a tool in disease management.
Artificial Intelligence Index Report 2024
May 29, 2024The 2024 Index is our most comprehensive to date and arrives at an important moment when AI's influence on society has never been more pronounced. This year, we have broadened our scope to more extensively cover essential trends such as technical advancements in AI, public perceptions of the technology, and the geopolitical dynamics surrounding its development. Featuring more original data than ever before, this edition introduces new estimates on AI training costs, detailed analyses of the responsible AI landscape, and an entirely new chapter dedicated to AI's impact on science and medicine. The AI Index report tracks, collates, distills, and visualizes data related to artificial intelligence (AI). Our mission is to provide unbiased, rigorously vetted, broadly sourced data in order for policymakers, researchers, executives, journalists, and the general public to develop a more thorough and nuanced understanding of the complex field of AI. The AI Index is recognized globally as one of the most credible and authoritative sources for data and insights on artificial intelligence. Previous editions have been cited in major newspapers, including the The New York Times, Bloomberg, and The Guardian, have amassed hundreds of academic citations, and been referenced by high-level policymakers in the United States, the United Kingdom, and the European Union, among other places. This year's edition surpasses all previous ones in size, scale, and scope, reflecting the growing significance that AI is coming to hold in all of our lives.
Capabilities of Gemini Models in Medicine
May 01, 2024



Excellence in a wide variety of medical applications poses considerable challenges for AI, requiring advanced reasoning, access to up-to-date medical knowledge and understanding of complex multimodal data. Gemini models, with strong general capabilities in multimodal and long-context reasoning, offer exciting possibilities in medicine. Building on these core strengths of Gemini, we introduce Med-Gemini, a family of highly capable multimodal models that are specialized in medicine with the ability to seamlessly use web search, and that can be efficiently tailored to novel modalities using custom encoders. We evaluate Med-Gemini on 14 medical benchmarks, establishing new state-of-the-art (SoTA) performance on 10 of them, and surpass the GPT-4 model family on every benchmark where a direct comparison is viable, often by a wide margin. On the popular MedQA (USMLE) benchmark, our best-performing Med-Gemini model achieves SoTA performance of 91.1% accuracy, using a novel uncertainty-guided search strategy. On 7 multimodal benchmarks including NEJM Image Challenges and MMMU (health & medicine), Med-Gemini improves over GPT-4V by an average relative margin of 44.5%. We demonstrate the effectiveness of Med-Gemini's long-context capabilities through SoTA performance on a needle-in-a-haystack retrieval task from long de-identified health records and medical video question answering, surpassing prior bespoke methods using only in-context learning. Finally, Med-Gemini's performance suggests real-world utility by surpassing human experts on tasks such as medical text summarization, alongside demonstrations of promising potential for multimodal medical dialogue, medical research and education. Taken together, our results offer compelling evidence for Med-Gemini's potential, although further rigorous evaluation will be crucial before real-world deployment in this safety-critical domain.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Artificial Intelligence Index Report 2023
Oct 05, 2023Welcome to the sixth edition of the AI Index Report. This year, the report introduces more original data than any previous edition, including a new chapter on AI public opinion, a more thorough technical performance chapter, original analysis about large language and multimodal models, detailed trends in global AI legislation records, a study of the environmental impact of AI systems, and more. The AI Index Report tracks, collates, distills, and visualizes data related to artificial intelligence. Our mission is to provide unbiased, rigorously vetted, broadly sourced data in order for policymakers, researchers, executives, journalists, and the general public to develop a more thorough and nuanced understanding of the complex field of AI. The report aims to be the world's most credible and authoritative source for data and insights about AI.
The AI Index 2022 Annual Report
May 02, 2022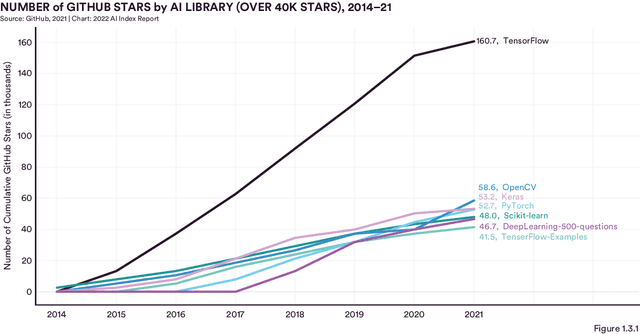
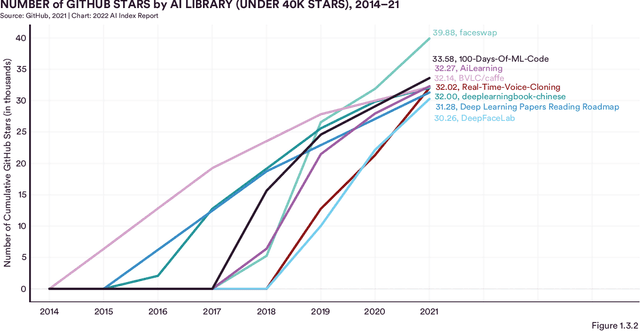
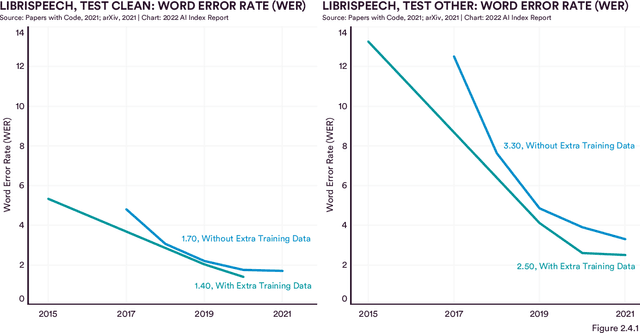
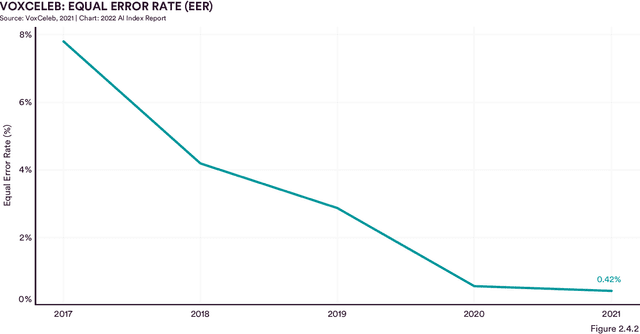
Welcome to the fifth edition of the AI Index Report! The latest edition includes data from a broad set of academic, private, and nonprofit organizations as well as more self-collected data and original analysis than any previous editions, including an expanded technical performance chapter, a new survey of robotics researchers around the world, data on global AI legislation records in 25 countries, and a new chapter with an in-depth analysis of technical AI ethics metrics. The AI Index Report tracks, collates, distills, and visualizes data related to artificial intelligence. Its mission is to provide unbiased, rigorously vetted, and globally sourced data for policymakers, researchers, executives, journalists, and the general public to develop a more thorough and nuanced understanding of the complex field of AI. The report aims to be the world's most credible and authoritative source for data and insights about AI.