 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJamba-1.5: Hybrid Transformer-Mamba Models at Scale
Aug 22, 2024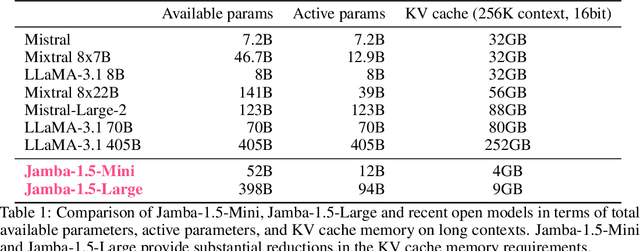
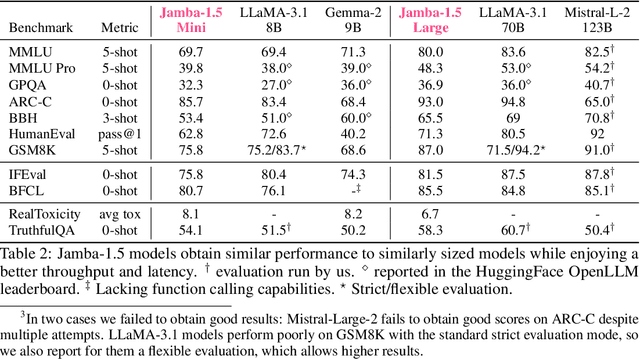
We present Jamba-1.5, new instruction-tuned large language models based on our Jamba architecture. Jamba is a hybrid Transformer-Mamba mixture of experts architecture, providing high throughput and low memory usage across context lengths, while retaining the same or better quality as Transformer models. We release two model sizes: Jamba-1.5-Large, with 94B active parameters, and Jamba-1.5-Mini, with 12B active parameters. Both models are fine-tuned for a variety of conversational and instruction-following capabilties, and have an effective context length of 256K tokens, the largest amongst open-weight models. To support cost-effective inference, we introduce ExpertsInt8, a novel quantization technique that allows fitting Jamba-1.5-Large on a machine with 8 80GB GPUs when processing 256K-token contexts without loss of quality. When evaluated on a battery of academic and chatbot benchmarks, Jamba-1.5 models achieve excellent results while providing high throughput and outperforming other open-weight models on long-context benchmarks. The model weights for both sizes are publicly available under the Jamba Open Model License and we release ExpertsInt8 as open source.
Jamba: A Hybrid Transformer-Mamba Language Model
Mar 28, 2024



We present Jamba, a new base large language model based on a novel hybrid Transformer-Mamba mixture-of-experts (MoE) architecture. Specifically, Jamba interleaves blocks of Transformer and Mamba layers, enjoying the benefits of both model families. MoE is added in some of these layers to increase model capacity while keeping active parameter usage manageable. This flexible architecture allows resource- and objective-specific configurations. In the particular configuration we have implemented, we end up with a powerful model that fits in a single 80GB GPU. Built at large scale, Jamba provides high throughput and small memory footprint compared to vanilla Transformers, and at the same time state-of-the-art performance on standard language model benchmarks and long-context evaluations. Remarkably, the model presents strong results for up to 256K tokens context length. We study various architectural decisions, such as how to combine Transformer and Mamba layers, and how to mix experts, and show that some of them are crucial in large scale modeling. We also describe several interesting properties of these architectures which the training and evaluation of Jamba have revealed, and plan to release checkpoints from various ablation runs, to encourage further exploration of this novel architecture. We make the weights of our implementation of Jamba publicly available under a permissive license.