 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue-based Search in Execution Space for Mapping Instructions to Programs
Paper and Code


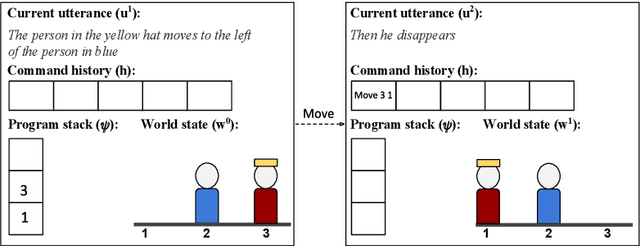

Training models to map natural language instructions to programs given target world supervision only requires searching for good programs at training time. Search is commonly done using beam search in the space of partial programs or program trees, but as the length of the instructions grows finding a good program becomes difficult. In this work, we propose a search algorithm that uses the target world state, known at training time, to train a critic network that predicts the expected reward of every search state. We then score search states on the beam by interpolating their expected reward with the likelihood of programs represented by the search state. Moreover, we search not in the space of programs but in a more compressed state of program executions, augmented with recent entities and actions. On the SCONE dataset, we show that our algorithm dramatically improves performance on all three domains compared to standard beam search and other baselines.