 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiGen: Hierarchy-Aware Sequence Generation for Hierarchical Text Classification
Jan 24, 2024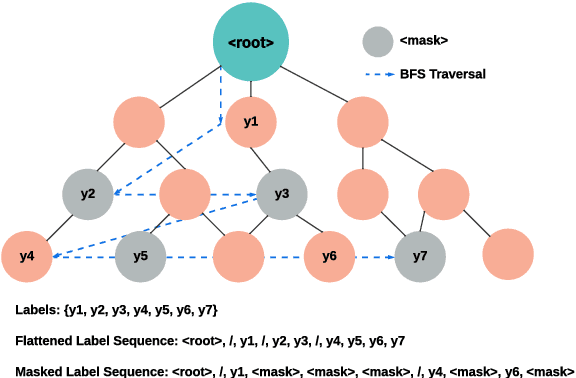

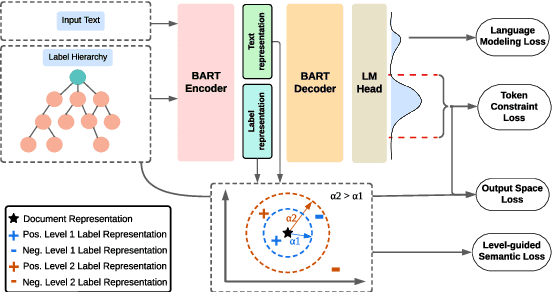
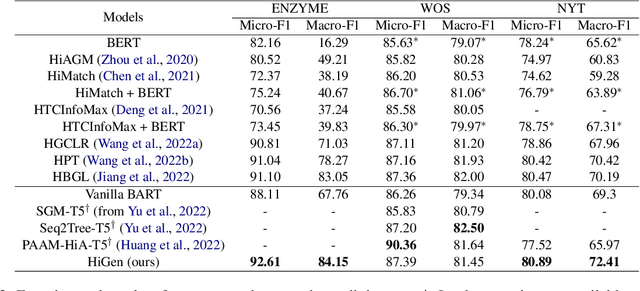
Hierarchical text classification (HTC) is a complex subtask under multi-label text classification, characterized by a hierarchical label taxonomy and data imbalance. The best-performing models aim to learn a static representation by combining document and hierarchical label information. However, the relevance of document sections can vary based on the hierarchy level, necessitating a dynamic document representation. To address this, we propose HiGen, a text-generation-based framework utilizing language models to encode dynamic text representations. We introduce a level-guided loss function to capture the relationship between text and label name semantics. Our approach incorporates a task-specific pretraining strategy, adapting the language model to in-domain knowledge and significantly enhancing performance for classes with limited examples. Furthermore, we present a new and valuable dataset called ENZYME, designed for HTC, which comprises articles from PubMed with the goal of predicting Enzyme Commission (EC) numbers. Through extensive experiments on the ENZYME dataset and the widely recognized WOS and NYT datasets, our methodology demonstrates superior performance, surpassing existing approaches while efficiently handling data and mitigating class imbalance. The data and code will be released publicly.
NGAME: Negative Mining-aware Mini-batching for Extreme Classification
Jul 10, 2022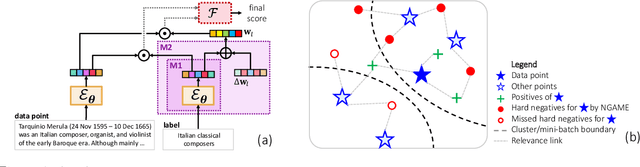
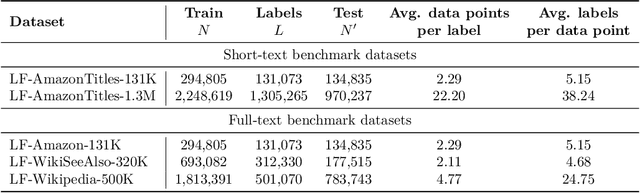
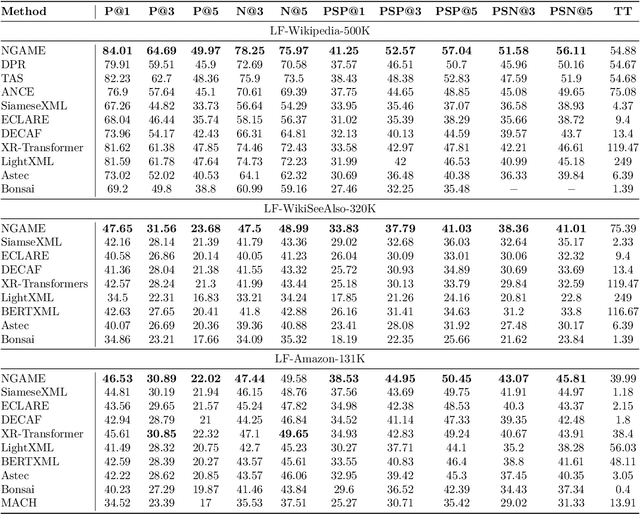
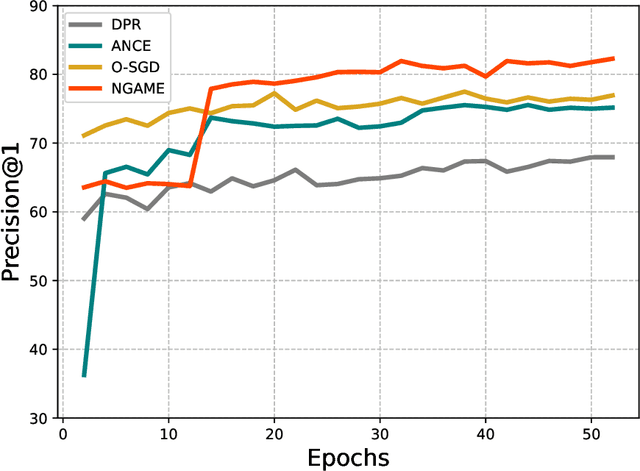
Extreme Classification (XC) seeks to tag data points with the most relevant subset of labels from an extremely large label set. Performing deep XC with dense, learnt representations for data points and labels has attracted much attention due to its superiority over earlier XC methods that used sparse, hand-crafted features. Negative mining techniques have emerged as a critical component of all deep XC methods that allow them to scale to millions of labels. However, despite recent advances, training deep XC models with large encoder architectures such as transformers remains challenging. This paper identifies that memory overheads of popular negative mining techniques often force mini-batch sizes to remain small and slow training down. In response, this paper introduces NGAME, a light-weight mini-batch creation technique that offers provably accurate in-batch negative samples. This allows training with larger mini-batches offering significantly faster convergence and higher accuracies than existing negative sampling techniques. NGAME was found to be up to 16% more accurate than state-of-the-art methods on a wide array of benchmark datasets for extreme classification, as well as 3% more accurate at retrieving search engine queries in response to a user webpage visit to show personalized ads. In live A/B tests on a popular search engine, NGAME yielded up to 23% gains in click-through-rates.
Neural Models for Output-Space Invariance in Combinatorial Problems
Feb 07, 2022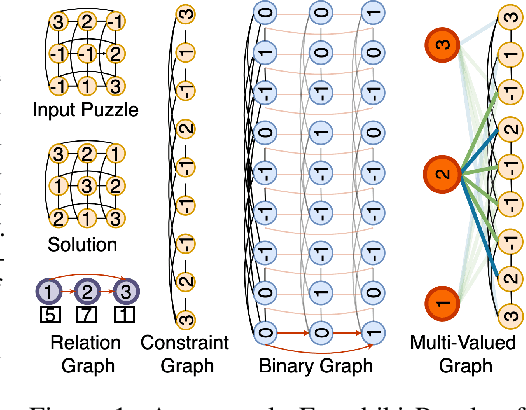
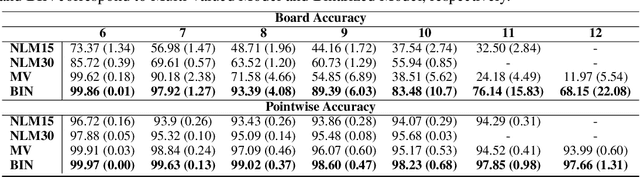
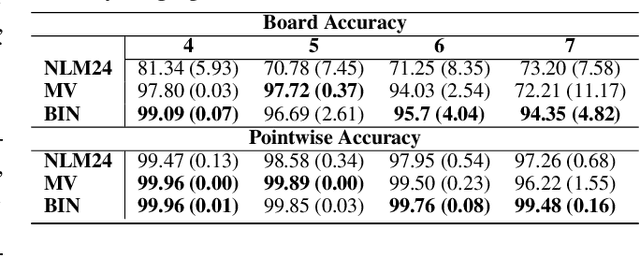
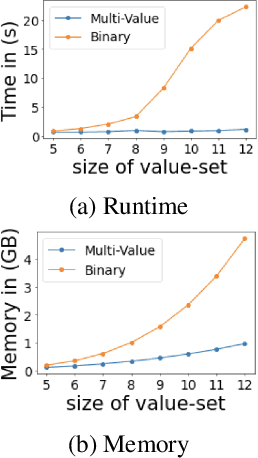
Recently many neural models have been proposed to solve combinatorial puzzles by implicitly learning underlying constraints using their solved instances, such as sudoku or graph coloring (GCP). One drawback of the proposed architectures, which are often based on Graph Neural Networks (GNN), is that they cannot generalize across the size of the output space from which variables are assigned a value, for example, set of colors in a GCP, or board-size in sudoku. We call the output space for the variables as 'value-set'. While many works have demonstrated generalization of GNNs across graph size, there has been no study on how to design a GNN for achieving value-set invariance for problems that come from the same domain. For example, learning to solve 16 x 16 sudoku after being trained on only 9 x 9 sudokus. In this work, we propose novel methods to extend GNN based architectures to achieve value-set invariance. Specifically, our model builds on recently proposed Recurrent Relational Networks. Our first approach exploits the graph-size invariance of GNNs by converting a multi-class node classification problem into a binary node classification problem. Our second approach works directly with multiple classes by adding multiple nodes corresponding to the values in the value-set, and then connecting variable nodes to value nodes depending on the problem initialization. Our experimental evaluation on three different combinatorial problems demonstrates that both our models perform well on our novel problem, compared to a generic neural reasoner. Between two of our models, we observe an inherent trade-off: while the binarized model gives better performance when trained on smaller value-sets, multi-valued model is much more memory efficient, resulting in improved performance when trained on larger value-sets, where binarized model fails to train.
Exploring Semi-Supervised Learning for Predicting Listener Backchannels
Jan 06, 2021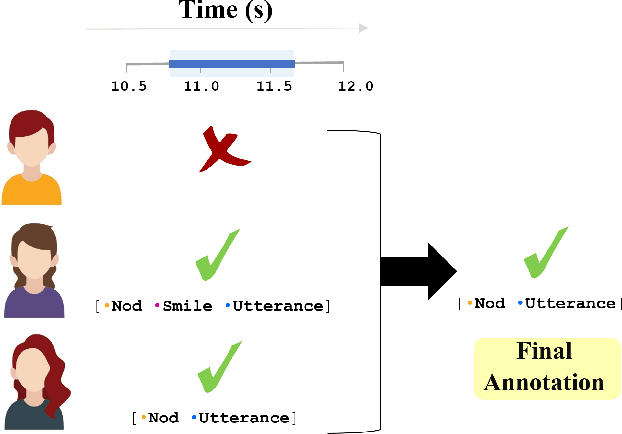
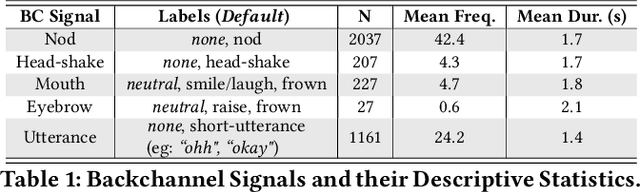
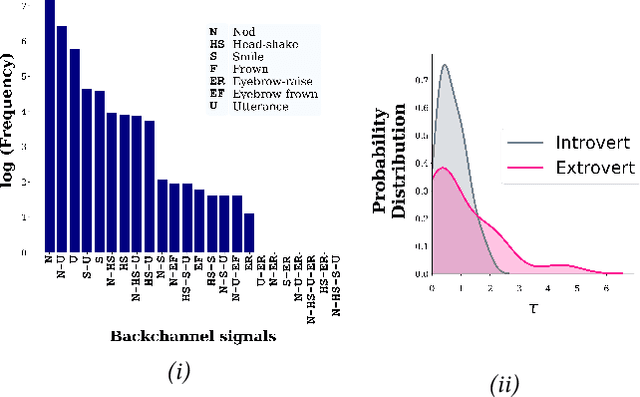

Developing human-like conversational agents is a prime area in HCI research and subsumes many tasks. Predicting listener backchannels is one such actively-researched task. While many studies have used different approaches for backchannel prediction, they all have depended on manual annotations for a large dataset. This is a bottleneck impacting the scalability of development. To this end, we propose using semi-supervised techniques to automate the process of identifying backchannels, thereby easing the annotation process. To analyze our identification module's feasibility, we compared the backchannel prediction models trained on (a) manually-annotated and (b) semi-supervised labels. Quantitative analysis revealed that the proposed semi-supervised approach could attain 95% of the former's performance. Our user-study findings revealed that almost 60% of the participants found the backchannel responses predicted by the proposed model more natural. Finally, we also analyzed the impact of personality on the type of backchannel signals and validated our findings in the user-study.