 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Semi-Supervised Learning for Predicting Listener Backchannels
Jan 06, 2021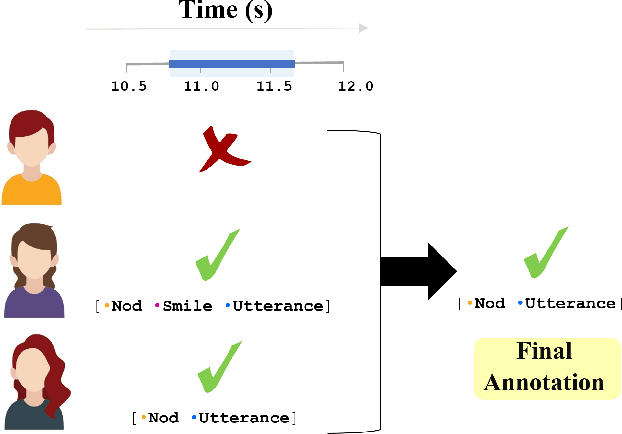
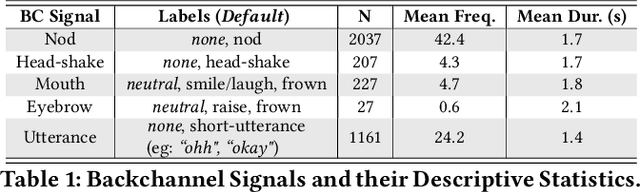
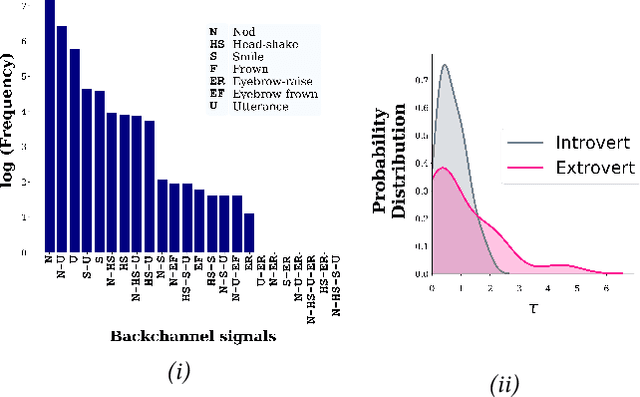

Developing human-like conversational agents is a prime area in HCI research and subsumes many tasks. Predicting listener backchannels is one such actively-researched task. While many studies have used different approaches for backchannel prediction, they all have depended on manual annotations for a large dataset. This is a bottleneck impacting the scalability of development. To this end, we propose using semi-supervised techniques to automate the process of identifying backchannels, thereby easing the annotation process. To analyze our identification module's feasibility, we compared the backchannel prediction models trained on (a) manually-annotated and (b) semi-supervised labels. Quantitative analysis revealed that the proposed semi-supervised approach could attain 95% of the former's performance. Our user-study findings revealed that almost 60% of the participants found the backchannel responses predicted by the proposed model more natural. Finally, we also analyzed the impact of personality on the type of backchannel signals and validated our findings in the user-study.
Vyaktitv: A Multimodal Peer-to-Peer Hindi Conversations based Dataset for Personality Assessment
Aug 31, 2020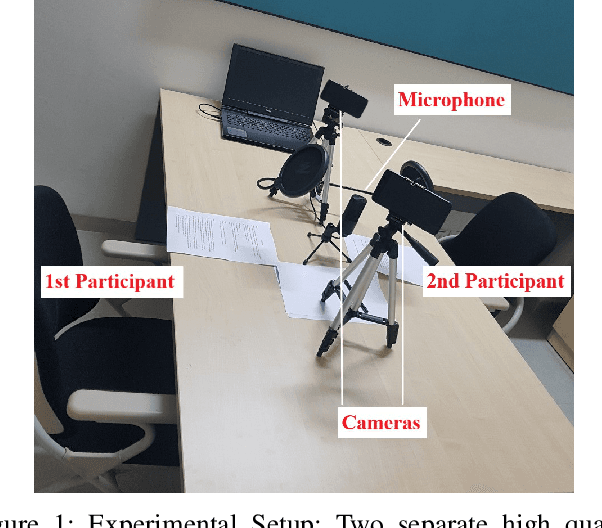
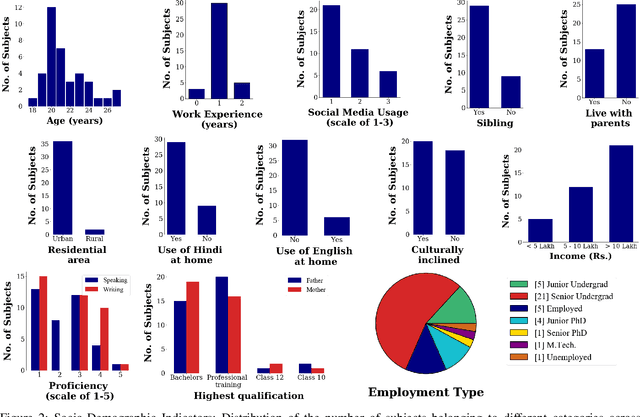
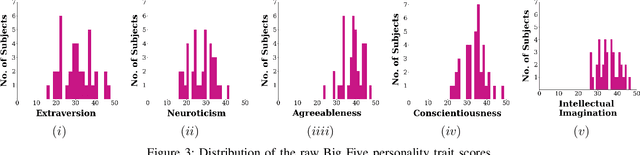
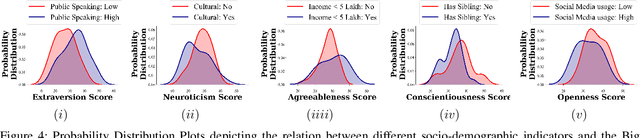
Automatically detecting personality traits can aid several applications, such as mental health recognition and human resource management. Most datasets introduced for personality detection so far have analyzed these traits for each individual in isolation. However, personality is intimately linked to our social behavior. Furthermore, surprisingly little research has focused on personality analysis using low resource languages. To this end, we present a novel peer-to-peer Hindi conversation dataset- Vyaktitv. It consists of high-quality audio and video recordings of the participants, with Hinglish textual transcriptions for each conversation. The dataset also contains a rich set of socio-demographic features, like income, cultural orientation, amongst several others, for all the participants. We release the dataset for public use, as well as perform preliminary statistical analysis along the different dimensions. Finally, we also discuss various other applications and tasks for which the dataset can be employed.
Towards Social & Engaging Peer Learning: Predicting Backchanneling and Disengagement in Children
Jul 22, 2020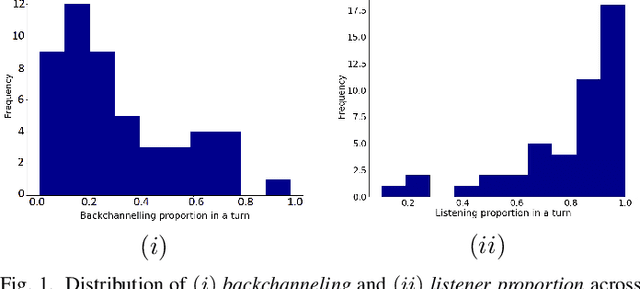
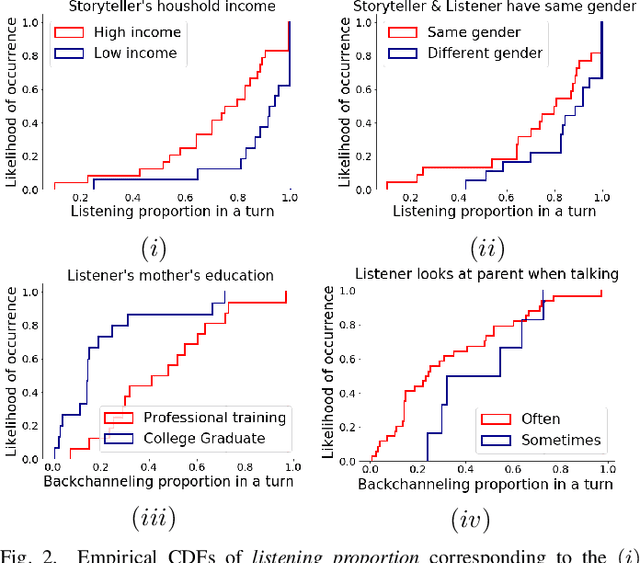

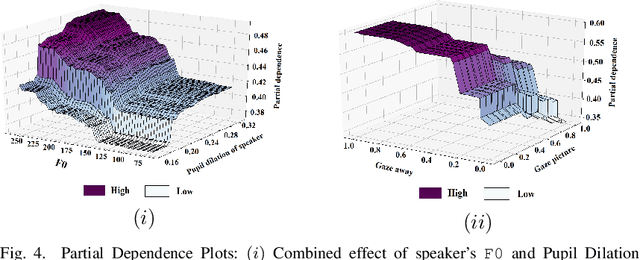
Social robots and interactive computer applications have the potential to foster early language development in young children by acting as peer learning companions. However, studies have found that children only trust robots which behave in a natural and interpersonal manner. To help robots come across as engaging and attentive peer learning companions, we develop models to predict whether the listener will lose attention (Listener Disengagement Prediction, LDP) and the extent to which a robot should generate backchanneling responses (Backchanneling Extent Prediction, BEP) in the next few seconds. We pose LDP and BEP as time series classification problems and conduct several experiments to assess the impact of different time series characteristics and feature sets on the predictive performance of our model. Using statistics & machine learning, we also examine which socio-demographic factors influence the amount of time children spend backchanneling and listening to their peers. To lend interpretability to our models, we also analyzed critical features responsible for their predictive performance. Our experiments revealed the utility of multimodal features such as pupil dilation, blink rate, head movements, facial action units which have never been used before. We also found that the dynamics of time series features are rich predictors of listener disengagement and backchanneling.