 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Self-to-Supervised Fine-Tuning for Generalization in Large Language Models
Feb 12, 2025Fine-tuning Large Language Models (LLMs) on specific datasets is a common practice to improve performance on target tasks. However, this performance gain often leads to overfitting, where the model becomes too specialized in either the task or the characteristics of the training data, resulting in a loss of generalization. This paper introduces Selective Self-to-Supervised Fine-Tuning (S3FT), a fine-tuning approach that achieves better performance than the standard supervised fine-tuning (SFT) while improving generalization. S3FT leverages the existence of multiple valid responses to a query. By utilizing the model's correct responses, S3FT reduces model specialization during the fine-tuning stage. S3FT first identifies the correct model responses from the training set by deploying an appropriate judge. Then, it fine-tunes the model using the correct model responses and the gold response (or its paraphrase) for the remaining samples. The effectiveness of S3FT is demonstrated through experiments on mathematical reasoning, Python programming and reading comprehension tasks. The results show that standard SFT can lead to an average performance drop of up to $4.4$ on multiple benchmarks, such as MMLU and TruthfulQA. In contrast, S3FT reduces this drop by half, i.e. $2.5$, indicating better generalization capabilities than SFT while performing significantly better on the fine-tuning tasks.
Systematic Knowledge Injection into Large Language Models via Diverse Augmentation for Domain-Specific RAG
Feb 12, 2025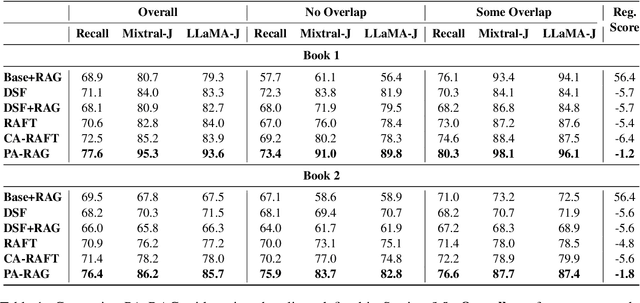

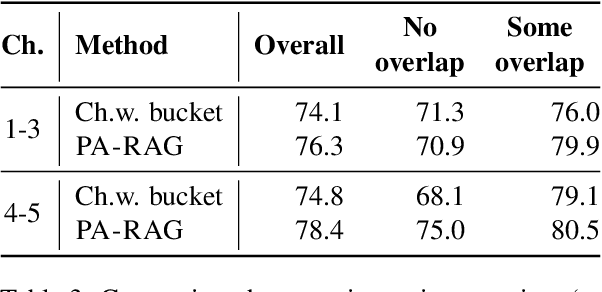
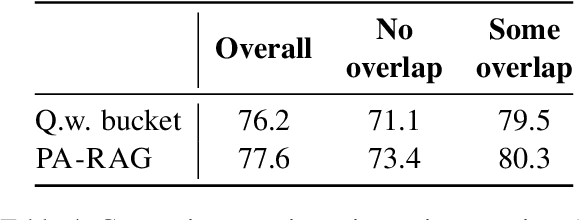
Retrieval-Augmented Generation (RAG) has emerged as a prominent method for incorporating domain knowledge into Large Language Models (LLMs). While RAG enhances response relevance by incorporating retrieved domain knowledge in the context, retrieval errors can still lead to hallucinations and incorrect answers. To recover from retriever failures, domain knowledge is injected by fine-tuning the model to generate the correct response, even in the case of retrieval errors. However, we observe that without systematic knowledge augmentation, fine-tuned LLMs may memorize new information but still fail to extract relevant domain knowledge, leading to poor performance. In this work, we present a novel framework that significantly enhances the fine-tuning process by augmenting the training data in two ways -- context augmentation and knowledge paraphrasing. In context augmentation, we create multiple training samples for a given QA pair by varying the relevance of the retrieved information, teaching the model when to ignore and when to rely on retrieved content. In knowledge paraphrasing, we fine-tune with multiple answers to the same question, enabling LLMs to better internalize specialized knowledge. To mitigate catastrophic forgetting due to fine-tuning, we add a domain-specific identifier to a question and also utilize a replay buffer containing general QA pairs. Experimental results demonstrate the efficacy of our method over existing techniques, achieving up to 10\% relative gain in token-level recall while preserving the LLM's generalization capabilities.
Selective Self-Rehearsal: A Fine-Tuning Approach to Improve Generalization in Large Language Models
Sep 07, 2024
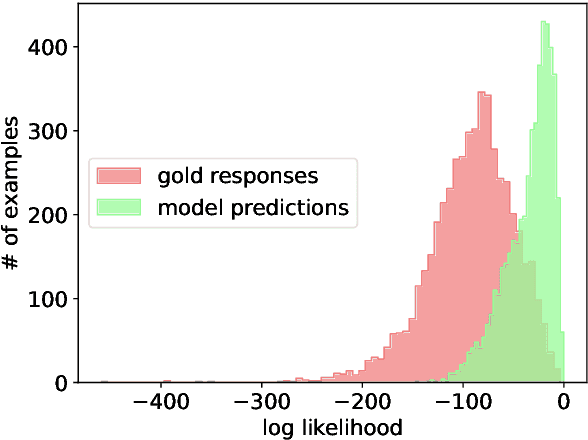
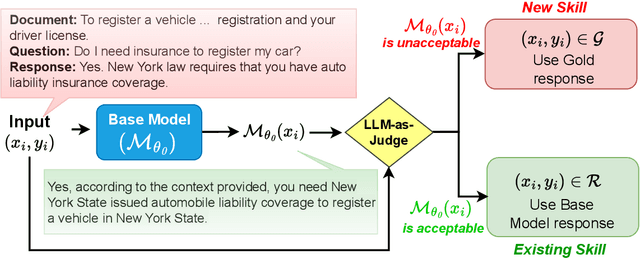
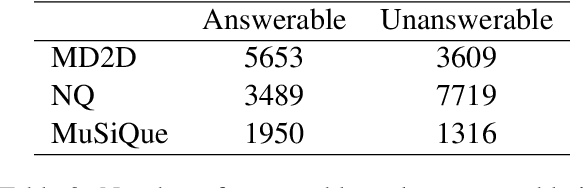
Fine-tuning Large Language Models (LLMs) on specific datasets is a common practice to improve performance on target tasks. However, this performance gain often leads to overfitting, where the model becomes too specialized in either the task or the characteristics of the training data, resulting in a loss of generalization. This paper introduces Selective Self-Rehearsal (SSR), a fine-tuning approach that achieves performance comparable to the standard supervised fine-tuning (SFT) while improving generalization. SSR leverages the fact that there can be multiple valid responses to a query. By utilizing the model's correct responses, SSR reduces model specialization during the fine-tuning stage. SSR first identifies the correct model responses from the training set by deploying an appropriate LLM as a judge. Then, it fine-tunes the model using the correct model responses and the gold response for the remaining samples. The effectiveness of SSR is demonstrated through experiments on the task of identifying unanswerable queries across various datasets. The results show that standard SFT can lead to an average performance drop of up to $16.7\%$ on multiple benchmarks, such as MMLU and TruthfulQA. In contrast, SSR results in close to $2\%$ drop on average, indicating better generalization capabilities compared to standard SFT.
PNeRV: A Polynomial Neural Representation for Videos
Jun 27, 2024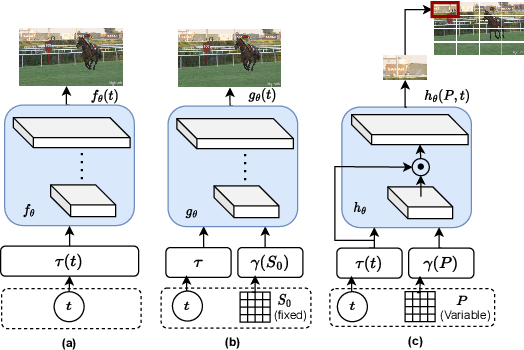

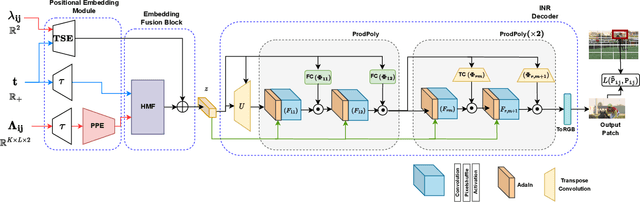

Extracting Implicit Neural Representations (INRs) on video data poses unique challenges due to the additional temporal dimension. In the context of videos, INRs have predominantly relied on a frame-only parameterization, which sacrifices the spatiotemporal continuity observed in pixel-level (spatial) representations. To mitigate this, we introduce Polynomial Neural Representation for Videos (PNeRV), a parameter-wise efficient, patch-wise INR for videos that preserves spatiotemporal continuity. PNeRV leverages the modeling capabilities of Polynomial Neural Networks to perform the modulation of a continuous spatial (patch) signal with a continuous time (frame) signal. We further propose a custom Hierarchical Patch-wise Spatial Sampling Scheme that ensures spatial continuity while retaining parameter efficiency. We also employ a carefully designed Positional Embedding methodology to further enhance PNeRV's performance. Our extensive experimentation demonstrates that PNeRV outperforms the baselines in conventional Implicit Neural Representation tasks like compression along with downstream applications that require spatiotemporal continuity in the underlying representation. PNeRV not only addresses the challenges posed by video data in the realm of INRs but also opens new avenues for advanced video processing and analysis.
V3GAN: Decomposing Background, Foreground and Motion for Video Generation
Mar 26, 2022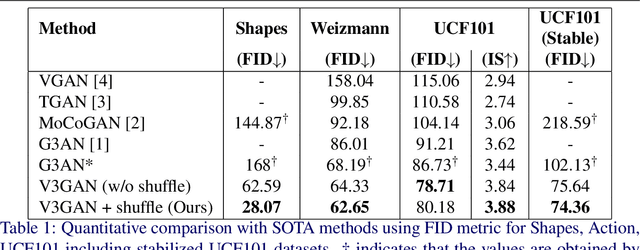
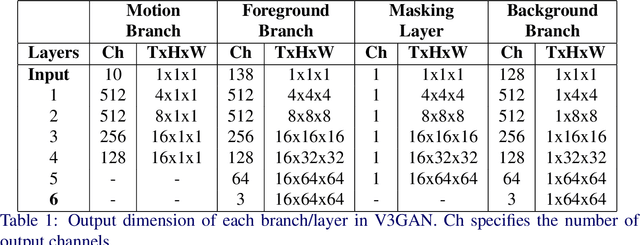

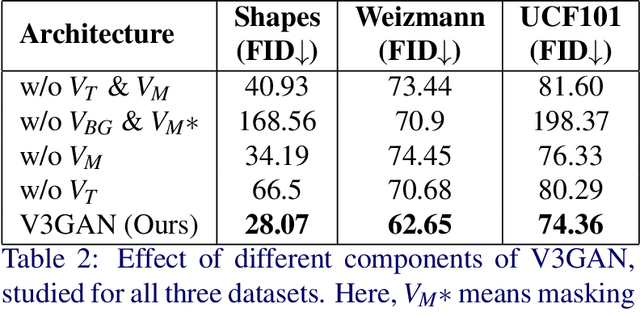
Video generation is a challenging task that requires modeling plausible spatial and temporal dynamics in a video. Inspired by how humans perceive a video by grouping a scene into moving and stationary components, we propose a method that decomposes the task of video generation into the synthesis of foreground, background and motion. Foreground and background together describe the appearance, whereas motion specifies how the foreground moves in a video over time. We propose V3GAN, a novel three-branch generative adversarial network where two branches model foreground and background information, while the third branch models the temporal information without any supervision. The foreground branch is augmented with our novel feature-level masking layer that aids in learning an accurate mask for foreground and background separation. To encourage motion consistency, we further propose a shuffling loss for the video discriminator. Extensive quantitative and qualitative analysis on synthetic as well as real-world benchmark datasets demonstrates that V3GAN outperforms the state-of-the-art methods by a significant margin.