 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePNeRV: A Polynomial Neural Representation for Videos
Jun 27, 2024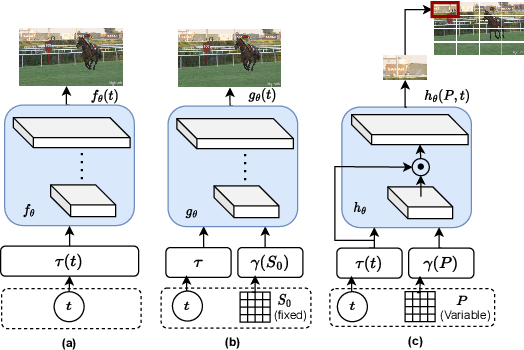

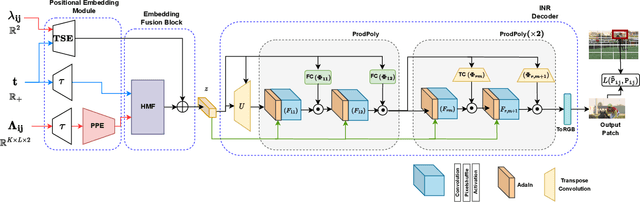

Extracting Implicit Neural Representations (INRs) on video data poses unique challenges due to the additional temporal dimension. In the context of videos, INRs have predominantly relied on a frame-only parameterization, which sacrifices the spatiotemporal continuity observed in pixel-level (spatial) representations. To mitigate this, we introduce Polynomial Neural Representation for Videos (PNeRV), a parameter-wise efficient, patch-wise INR for videos that preserves spatiotemporal continuity. PNeRV leverages the modeling capabilities of Polynomial Neural Networks to perform the modulation of a continuous spatial (patch) signal with a continuous time (frame) signal. We further propose a custom Hierarchical Patch-wise Spatial Sampling Scheme that ensures spatial continuity while retaining parameter efficiency. We also employ a carefully designed Positional Embedding methodology to further enhance PNeRV's performance. Our extensive experimentation demonstrates that PNeRV outperforms the baselines in conventional Implicit Neural Representation tasks like compression along with downstream applications that require spatiotemporal continuity in the underlying representation. PNeRV not only addresses the challenges posed by video data in the realm of INRs but also opens new avenues for advanced video processing and analysis.
Conditioning Covert Geo-Location (CGL) Detection on Semantic Class Information
Nov 27, 2022

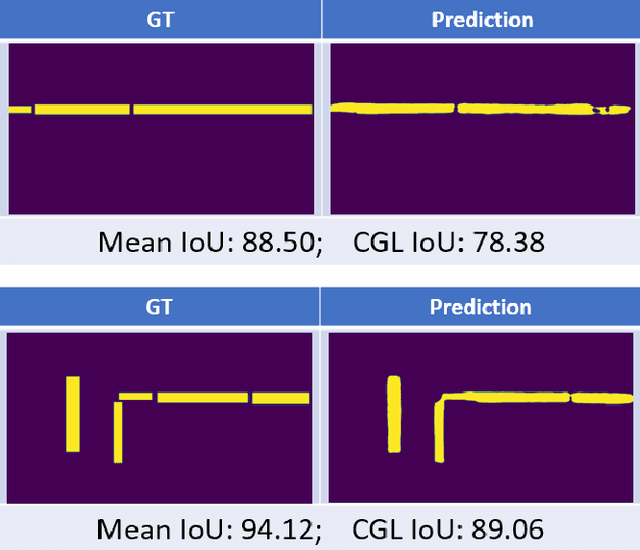
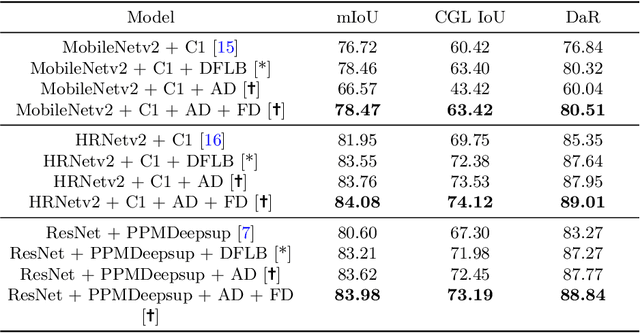
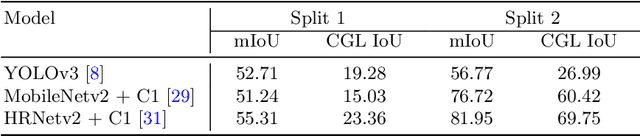
The primary goal of artificial intelligence is to mimic humans. Therefore, to advance toward this goal, the AI community attempts to imitate qualities/skills possessed by humans and imbibes them into machines with the help of datasets/tasks. Earlier, many tasks which require knowledge about the objects present in an image are satisfactorily solved by vision models. Recently, with the aim to incorporate knowledge about non-object image regions (hideouts, turns, and other obscured regions), a task for identification of potential hideouts termed Covert Geo-Location (CGL) detection was proposed by Saha et al. It involves identification of image regions which have the potential to either cause an imminent threat or appear as target zones to be accessed for further investigation to identify any occluded objects. Only certain occluding items belonging to certain semantic classes can give rise to CGLs. This fact was overlooked by Saha et al. and no attempts were made to utilize semantic class information, which is crucial for CGL detection. In this paper, we propose a multitask-learning-based approach to achieve 2 goals - i) extraction of features having semantic class information; ii) robust training of the common encoder, exploiting large standard annotated datasets as training set for the auxiliary task (semantic segmentation). To explicitly incorporate class information in the features extracted by the encoder, we have further employed attention mechanism in a novel manner. We have also proposed a better evaluation metric for CGL detection that gives more weightage to recognition rather than precise localization. Experimental evaluations performed on the CGL dataset, demonstrate a significant increase in performance of about 3% to 14% mIoU and 3% to 16% DaR on split 1, and 1% mIoU and 1% to 2% DaR on split 2 over SOTA, serving as a testimony to the superiority of our approach.
V3GAN: Decomposing Background, Foreground and Motion for Video Generation
Mar 26, 2022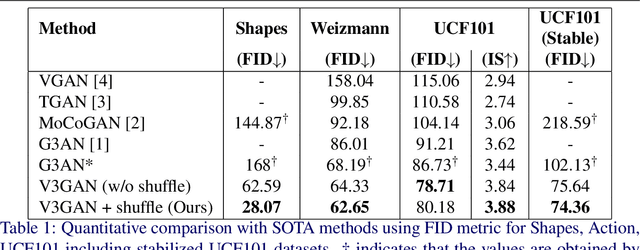
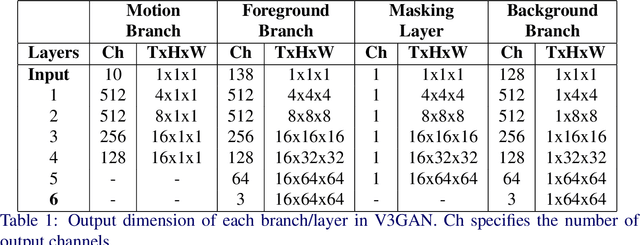

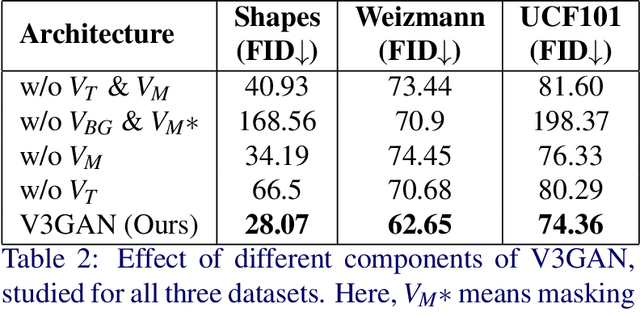
Video generation is a challenging task that requires modeling plausible spatial and temporal dynamics in a video. Inspired by how humans perceive a video by grouping a scene into moving and stationary components, we propose a method that decomposes the task of video generation into the synthesis of foreground, background and motion. Foreground and background together describe the appearance, whereas motion specifies how the foreground moves in a video over time. We propose V3GAN, a novel three-branch generative adversarial network where two branches model foreground and background information, while the third branch models the temporal information without any supervision. The foreground branch is augmented with our novel feature-level masking layer that aids in learning an accurate mask for foreground and background separation. To encourage motion consistency, we further propose a shuffling loss for the video discriminator. Extensive quantitative and qualitative analysis on synthetic as well as real-world benchmark datasets demonstrates that V3GAN outperforms the state-of-the-art methods by a significant margin.
Catch Me if You Can: A Novel Task for Detection of Covert Geo-Locations
Feb 05, 2022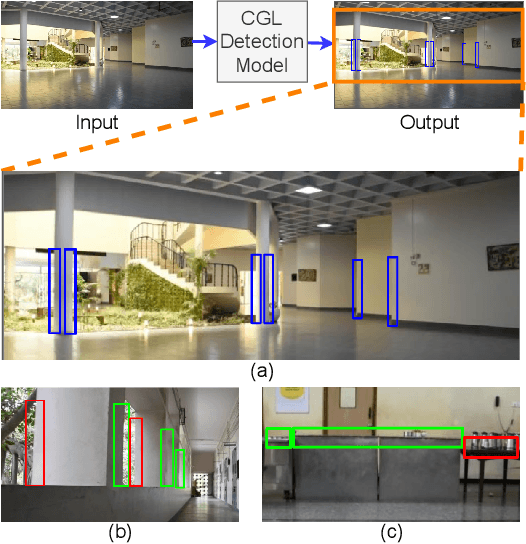


Most visual scene understanding tasks in the field of computer vision involve identification of the objects present in the scene. Image regions like hideouts, turns, & other obscured regions of the scene also contain crucial information, for specific surveillance tasks. Task proposed in this paper involves the design of an intelligent visual aid for identification of such locations in an image, which has either the potential to create an imminent threat from an adversary or appear as the target zones needing further investigation. Covert places (CGL) for hiding behind an occluding object are concealed 3D locations, not detectable from the viewpoint (camera). Hence this involves delineating specific image regions around the projections of outer boundary of the occluding objects, as places to be accessed around the potential hideouts. CGL detection finds applications in military counter-insurgency operations, surveillance with path planning for an exploratory robot. Given an RGB image, the goal is to identify all CGLs in the 2D scene. Identification of such regions would require knowledge about the 3D boundaries of obscuring items (pillars, furniture), their spatial location with respect to the neighboring regions of the scene. We propose this as a novel task, termed Covert Geo-Location (CGL) Detection. Classification of any region of an image as a CGL (as boundary sub-segments of an occluding object that conceals the hideout) requires examining the 3D relation between boundaries of occluding objects and their neighborhoods & surroundings. Our method successfully extracts relevant depth features from a single RGB image and quantitatively yields significant improvement over existing object detection and segmentation models adapted and trained for CGL detection. We also introduce a novel hand-annotated CGL detection dataset containing 1.5K real-world images for experimentation.
Future Frame Prediction of a Video Sequence
Aug 31, 2020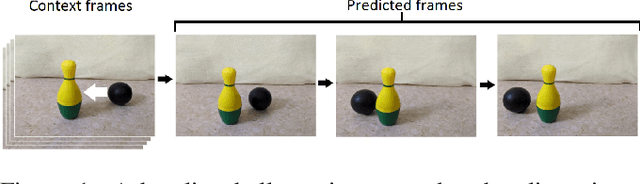
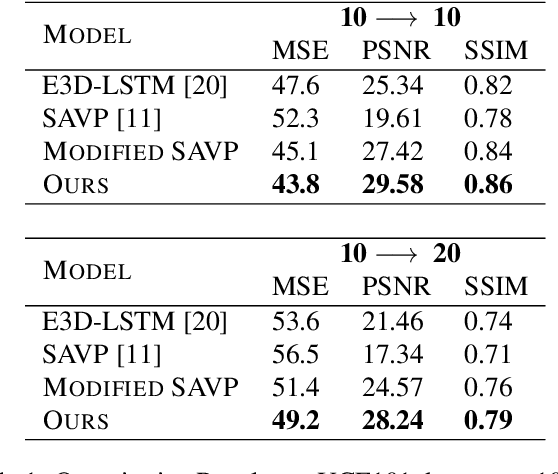
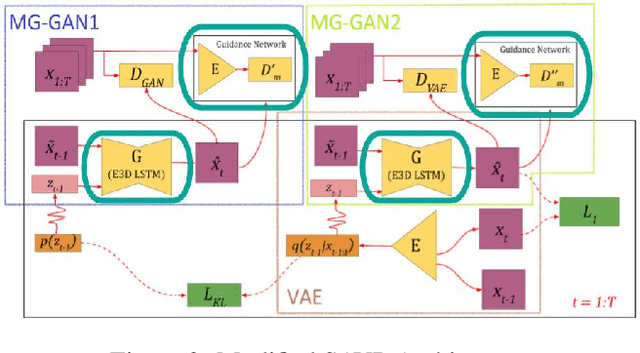
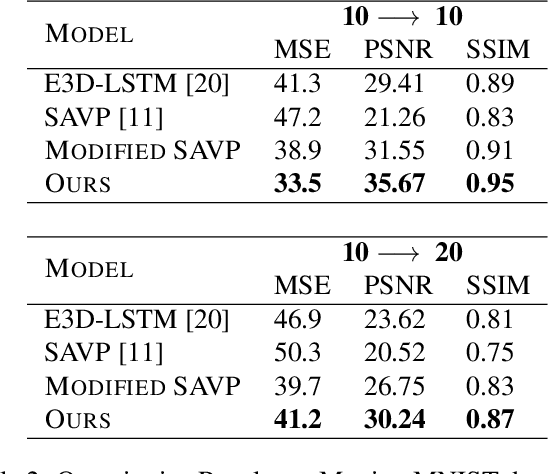
Predicting future frames of a video sequence has been a problem of high interest in the field of Computer Vision as it caters to a multitude of applications. The ability to predict, anticipate and reason about future events is the essence of intelligence and one of the main goals of decision-making systems such as human-machine interaction, robot navigation and autonomous driving. However, the challenge lies in the ambiguous nature of the problem as there may be multiple future sequences possible for the same input video shot. A naively designed model averages multiple possible futures into a single blurry prediction. Recently, two distinct approaches have attempted to address this problem as: (a) use of latent variable models that represent underlying stochasticity and (b) adversarially trained models that aim to produce sharper images. A latent variable model often struggles to produce realistic results, while an adversarially trained model underutilizes latent variables and thus fails to produce diverse predictions. These methods have revealed complementary strengths and weaknesses. Combining the two approaches produces predictions that appear more realistic and better cover the range of plausible futures. This forms the basis and objective of study in this project work. In this paper, we proposed a novel multi-scale architecture combining both approaches. We validate our proposed model through a series of experiments and empirical evaluations on Moving MNIST, UCF101, and Penn Action datasets. Our method outperforms the results obtained using the baseline methods.
SD-GAN: Structural and Denoising GAN reveals facial parts under occlusion
Feb 19, 2020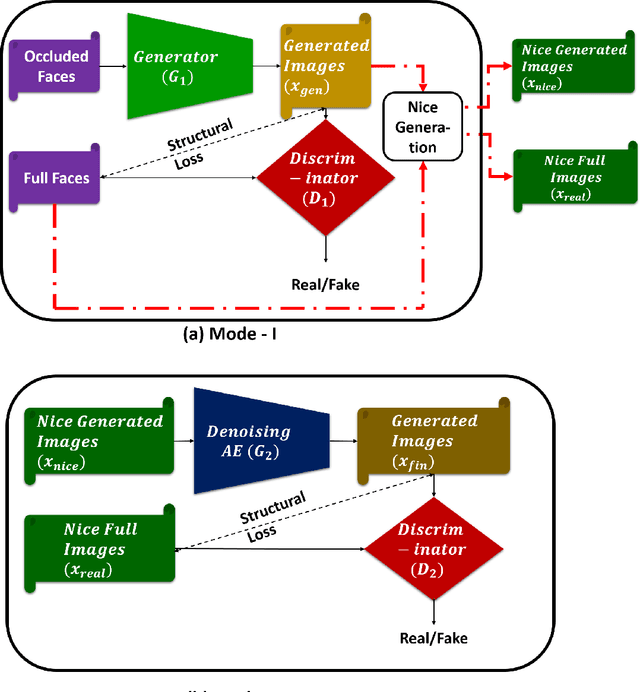
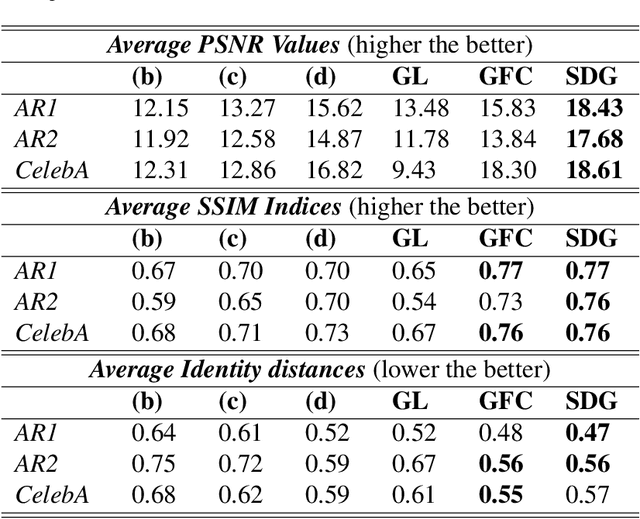
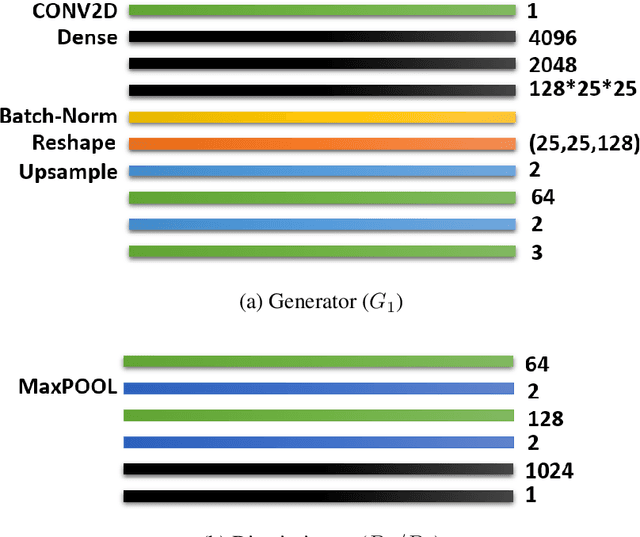
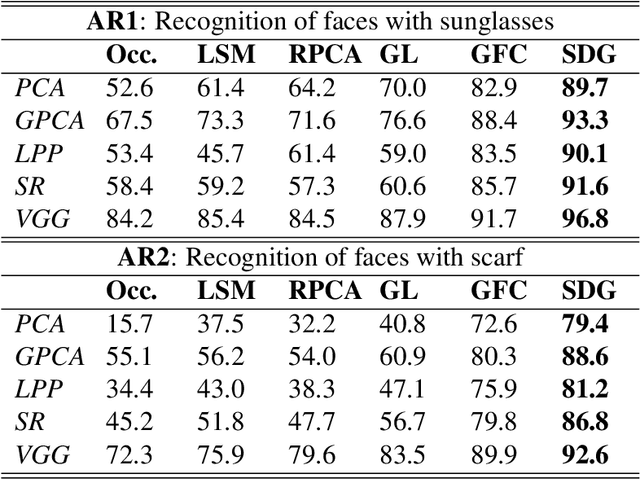
Certain facial parts are salient (unique) in appearance, which substantially contribute to the holistic recognition of a subject. Occlusion of these salient parts deteriorates the performance of face recognition algorithms. In this paper, we propose a generative model to reconstruct the missing parts of the face which are under occlusion. The proposed generative model (SD-GAN) reconstructs a face preserving the illumination variation and identity of the face. A novel adversarial training algorithm has been designed for a bimodal mutually exclusive Generative Adversarial Network (GAN) model, for faster convergence. A novel adversarial "structural" loss function is also proposed, comprising of two components: a holistic and a local loss, characterized by SSIM and patch-wise MSE. Ablation studies on real and synthetically occluded face datasets reveal that our proposed technique outperforms the competing methods by a considerable margin, even for boosting the performance of Face Recognition.
Moving Object Segmentation in Jittery Videos by Stabilizing Trajectories Modeled in Kendall's Shape Space
Aug 14, 2018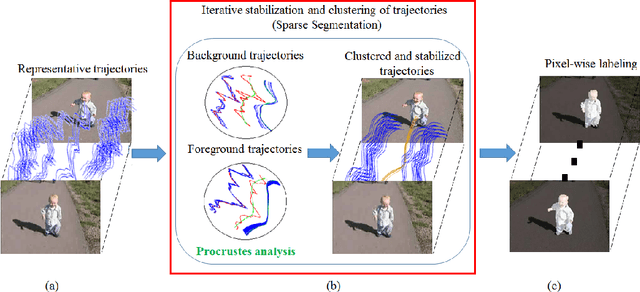
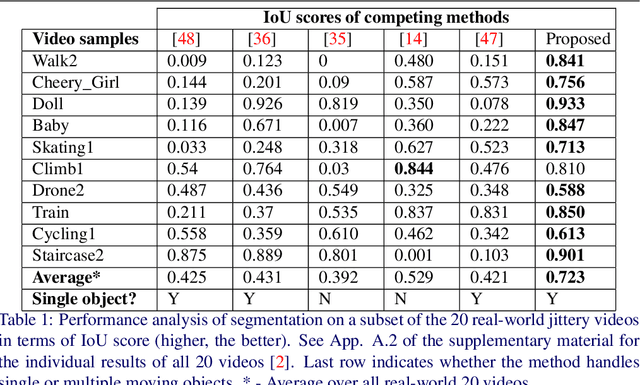
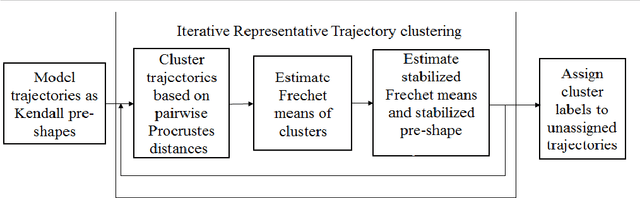
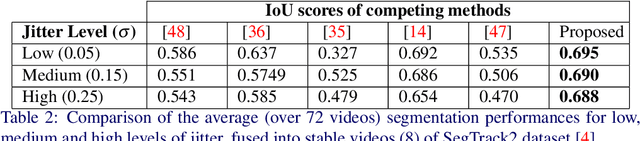
Moving Object Segmentation is a challenging task for jittery/wobbly videos. For jittery videos, the non-smooth camera motion makes discrimination between foreground objects and background layers hard to solve. While most recent works for moving video object segmentation fail in this scenario, our method generates an accurate segmentation of a single moving object. The proposed method performs a sparse segmentation, where frame-wise labels are assigned only to trajectory coordinates, followed by the pixel-wise labeling of frames. The sparse segmentation involving stabilization and clustering of trajectories in a 3-stage iterative process. At the 1st stage, the trajectories are clustered using pairwise Procrustes distance as a cue for creating an affinity matrix. The 2nd stage performs a block-wise Procrustes analysis of the trajectories and estimates Frechet means (in Kendall's shape space) of the clusters. The Frechet means represent the average trajectories of the motion clusters. An optimization function has been formulated to stabilize the Frechet means, yielding stabilized trajectories at the 3rd stage. The accuracy of the motion clusters are iteratively refined, producing distinct groups of stabilized trajectories. Next, the labels obtained from the sparse segmentation are propagated for pixel-wise labeling of the frames, using a GraphCut based energy formulation. Use of Procrustes analysis and energy minimization in Kendall's shape space for moving object segmentation in jittery videos, is the novelty of this work. Second contribution comes from experiments performed on a dataset formed of 20 real-world natural jittery videos, with manually annotated ground truth. Experiments are done with controlled levels of artificial jitter on videos of SegTrack2 dataset. Qualitative and quantitative results indicate the superiority of the proposed method.
Domain Adaptation with Soft-margin multiple feature-kernel learning beats Deep Learning for surveillance face recognition
Oct 27, 2016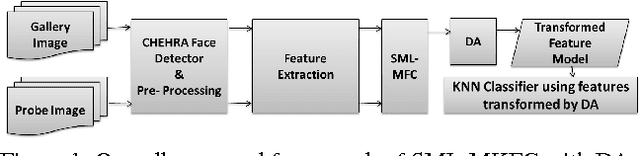
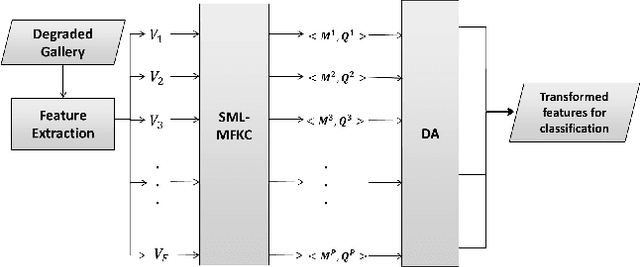
Face recognition (FR) is the most preferred mode for biometric-based surveillance, due to its passive nature of detecting subjects, amongst all different types of biometric traits. FR under surveillance scenario does not give satisfactory performance due to low contrast, noise and poor illumination conditions on probes, as compared to the training samples. A state-of-the-art technology, Deep Learning, even fails to perform well in these scenarios. We propose a novel soft-margin based learning method for multiple feature-kernel combinations, followed by feature transformed using Domain Adaptation, which outperforms many recent state-of-the-art techniques, when tested using three real-world surveillance face datasets.
Kernel Selection using Multiple Kernel Learning and Domain Adaptation in Reproducing Kernel Hilbert Space, for Face Recognition under Surveillance Scenario
Oct 03, 2016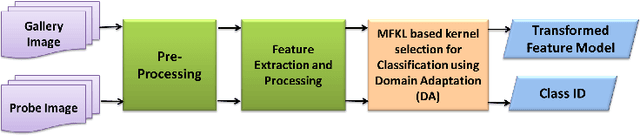


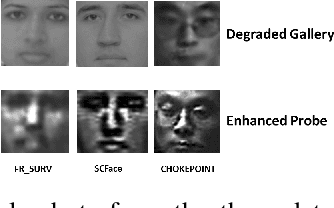
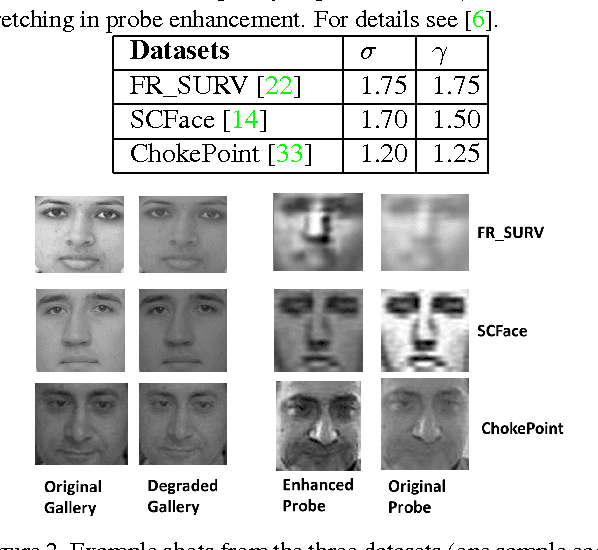
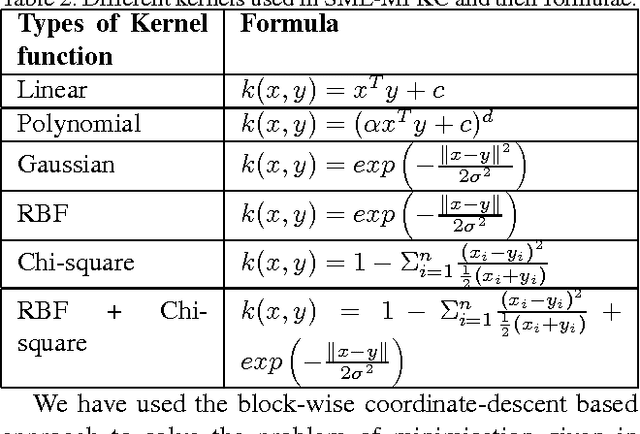
Face Recognition (FR) has been the interest to several researchers over the past few decades due to its passive nature of biometric authentication. Despite high accuracy achieved by face recognition algorithms under controlled conditions, achieving the same performance for face images obtained in surveillance scenarios, is a major hurdle. Some attempts have been made to super-resolve the low-resolution face images and improve the contrast, without considerable degree of success. The proposed technique in this paper tries to cope with the very low resolution and low contrast face images obtained from surveillance cameras, for FR under surveillance conditions. For Support Vector Machine classification, the selection of appropriate kernel has been a widely discussed issue in the research community. In this paper, we propose a novel kernel selection technique termed as MFKL (Multi-Feature Kernel Learning) to obtain the best feature-kernel pairing. Our proposed technique employs a effective kernel selection by Multiple Kernel Learning (MKL) method, to choose the optimal kernel to be used along with unsupervised domain adaptation method in the Reproducing Kernel Hilbert Space (RKHS), for a solution to the problem. Rigorous experimentation has been performed on three real-world surveillance face datasets : FR\_SURV, SCface and ChokePoint. Results have been shown using Rank-1 Recognition Accuracy, ROC and CMC measures. Our proposed method outperforms all other recent state-of-the-art techniques by a considerable margin.