 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware Outlier Rejection for Robust Multi-View 3D Tracking of Similar Small Birds in An Outdoor Aviary
Dec 21, 2024



This paper presents a novel approach for robust 3D tracking of multiple birds in an outdoor aviary using a multi-camera system. Our method addresses the challenges of visually similar birds and their rapid movements by leveraging environmental landmarks for enhanced feature matching and 3D reconstruction. In our approach, outliers are rejected based on their nearest landmark. This enables precise 3D-modeling and simultaneous tracking of multiple birds. By utilizing environmental context, our approach significantly improves the differentiation between visually similar birds, a key obstacle in existing tracking systems. Experimental results demonstrate the effectiveness of our method, showing a $20\%$ elimination of outliers in the 3D reconstruction process, with a $97\%$ accuracy in matching. This remarkable accuracy in 3D modeling translates to robust and reliable tracking of multiple birds, even in challenging outdoor conditions. Our work not only advances the field of computer vision but also provides a valuable tool for studying bird behavior and movement patterns in natural settings. We also provide a large annotated dataset of 80 birds residing in four enclosures for 20 hours of footage which provides a rich testbed for researchers in computer vision, ornithologists, and ecologists. Code and the link to the dataset is available at https://github.com/airou-lab/3D_Multi_Bird_Tracking
Future Frame Prediction of a Video Sequence
Aug 31, 2020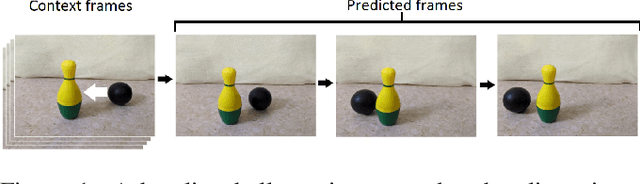
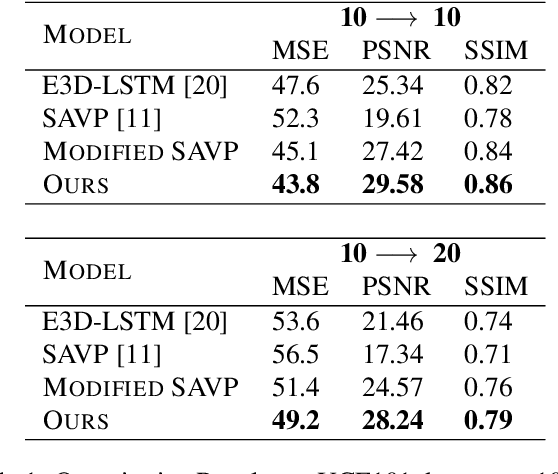
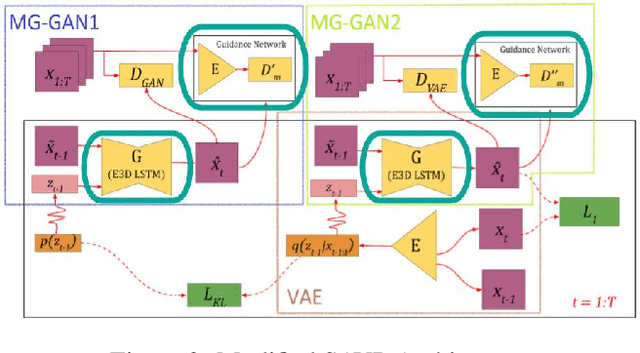
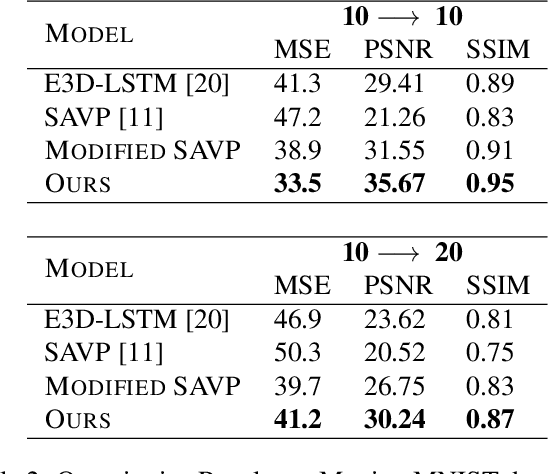
Predicting future frames of a video sequence has been a problem of high interest in the field of Computer Vision as it caters to a multitude of applications. The ability to predict, anticipate and reason about future events is the essence of intelligence and one of the main goals of decision-making systems such as human-machine interaction, robot navigation and autonomous driving. However, the challenge lies in the ambiguous nature of the problem as there may be multiple future sequences possible for the same input video shot. A naively designed model averages multiple possible futures into a single blurry prediction. Recently, two distinct approaches have attempted to address this problem as: (a) use of latent variable models that represent underlying stochasticity and (b) adversarially trained models that aim to produce sharper images. A latent variable model often struggles to produce realistic results, while an adversarially trained model underutilizes latent variables and thus fails to produce diverse predictions. These methods have revealed complementary strengths and weaknesses. Combining the two approaches produces predictions that appear more realistic and better cover the range of plausible futures. This forms the basis and objective of study in this project work. In this paper, we proposed a novel multi-scale architecture combining both approaches. We validate our proposed model through a series of experiments and empirical evaluations on Moving MNIST, UCF101, and Penn Action datasets. Our method outperforms the results obtained using the baseline methods.