 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditioning Covert Geo-Location (CGL) Detection on Semantic Class Information
Paper and Code
Nov 27, 2022

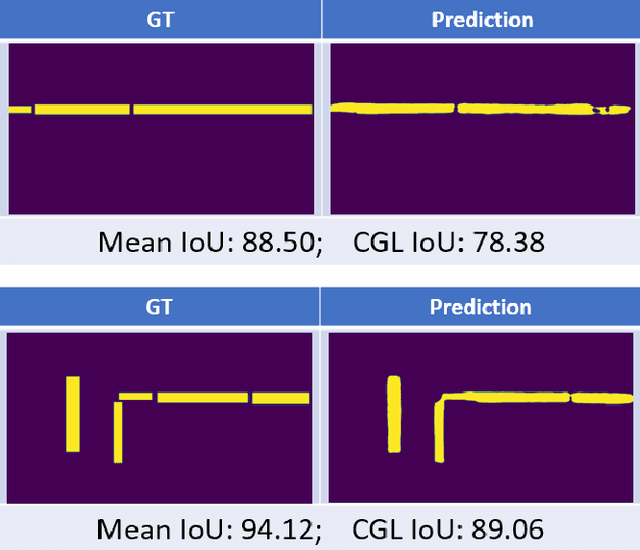
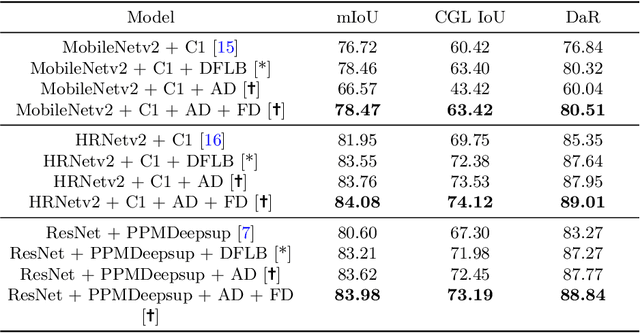
The primary goal of artificial intelligence is to mimic humans. Therefore, to advance toward this goal, the AI community attempts to imitate qualities/skills possessed by humans and imbibes them into machines with the help of datasets/tasks. Earlier, many tasks which require knowledge about the objects present in an image are satisfactorily solved by vision models. Recently, with the aim to incorporate knowledge about non-object image regions (hideouts, turns, and other obscured regions), a task for identification of potential hideouts termed Covert Geo-Location (CGL) detection was proposed by Saha et al. It involves identification of image regions which have the potential to either cause an imminent threat or appear as target zones to be accessed for further investigation to identify any occluded objects. Only certain occluding items belonging to certain semantic classes can give rise to CGLs. This fact was overlooked by Saha et al. and no attempts were made to utilize semantic class information, which is crucial for CGL detection. In this paper, we propose a multitask-learning-based approach to achieve 2 goals - i) extraction of features having semantic class information; ii) robust training of the common encoder, exploiting large standard annotated datasets as training set for the auxiliary task (semantic segmentation). To explicitly incorporate class information in the features extracted by the encoder, we have further employed attention mechanism in a novel manner. We have also proposed a better evaluation metric for CGL detection that gives more weightage to recognition rather than precise localization. Experimental evaluations performed on the CGL dataset, demonstrate a significant increase in performance of about 3% to 14% mIoU and 3% to 16% DaR on split 1, and 1% mIoU and 1% to 2% DaR on split 2 over SOTA, serving as a testimony to the superiority of our approach.