 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Fourth Challenge on Image Super-Resolution ($\times$4) at NTIRE 2026: Benchmark Results and Method Overview
Apr 16, 2026This paper presents the NTIRE 2026 image super-resolution ($\times$4) challenge, one of the associated competitions of the NTIRE 2026 Workshop at CVPR 2026. The challenge aims to reconstruct high-resolution (HR) images from low-resolution (LR) inputs generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective super-resolution solutions and analyze recent advances in the field. To reflect the evolving objectives of image super-resolution, the challenge includes two tracks: (1) a restoration track, which emphasizes pixel-wise fidelity and ranks submissions based on PSNR; and (2) a perceptual track, which focuses on visual realism and evaluates results using a perceptual score. A total of 194 participants registered for the challenge, with 31 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, main results, and methods of participating teams. The challenge provides a unified benchmark and offers insights into current progress and future directions in image super-resolution.
GriDiT: Factorized Grid-Based Diffusion for Efficient Long Image Sequence Generation
Dec 24, 2025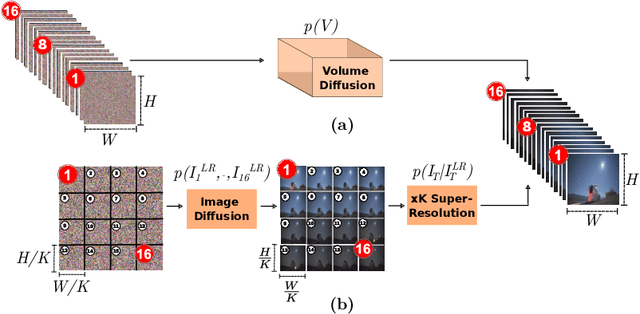
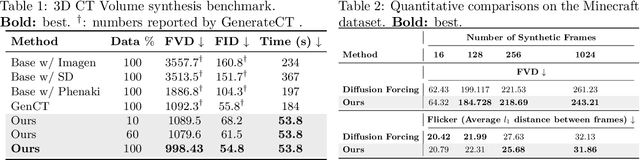
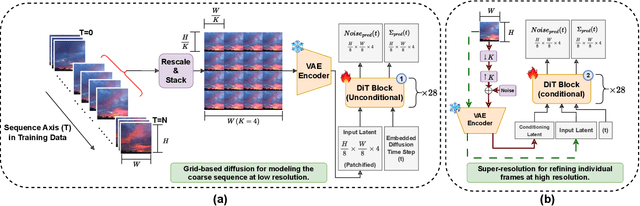
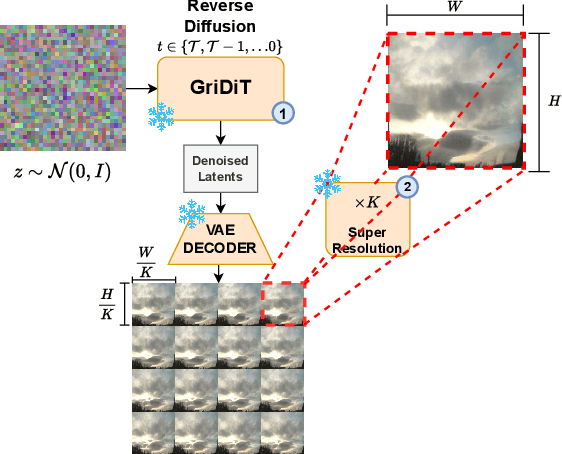
Modern deep learning methods typically treat image sequences as large tensors of sequentially stacked frames. However, is this straightforward representation ideal given the current state-of-the-art (SoTA)? In this work, we address this question in the context of generative models and aim to devise a more effective way of modeling image sequence data. Observing the inefficiencies and bottlenecks of current SoTA image sequence generation methods, we showcase that rather than working with large tensors, we can improve the generation process by factorizing it into first generating the coarse sequence at low resolution and then refining the individual frames at high resolution. We train a generative model solely on grid images comprising subsampled frames. Yet, we learn to generate image sequences, using the strong self-attention mechanism of the Diffusion Transformer (DiT) to capture correlations between frames. In effect, our formulation extends a 2D image generator to operate as a low-resolution 3D image-sequence generator without introducing any architectural modifications. Subsequently, we super-resolve each frame individually to add the sequence-independent high-resolution details. This approach offers several advantages and can overcome key limitations of the SoTA in this domain. Compared to existing image sequence generation models, our method achieves superior synthesis quality and improved coherence across sequences. It also delivers high-fidelity generation of arbitrary-length sequences and increased efficiency in inference time and training data usage. Furthermore, our straightforward formulation enables our method to generalize effectively across diverse data domains, which typically require additional priors and supervision to model in a generative context. Our method consistently outperforms SoTA in quality and inference speed (at least twice-as-fast) across datasets.
NTIRE 2025 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 20, 2025This paper presents the NTIRE 2025 image super-resolution ($\times$4) challenge, one of the associated competitions of the 10th NTIRE Workshop at CVPR 2025. The challenge aims to recover high-resolution (HR) images from low-resolution (LR) counterparts generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective network designs or solutions that achieve state-of-the-art SR performance. To reflect the dual objectives of image SR research, the challenge includes two sub-tracks: (1) a restoration track, emphasizes pixel-wise accuracy and ranks submissions based on PSNR; (2) a perceptual track, focuses on visual realism and ranks results by a perceptual score. A total of 286 participants registered for the competition, with 25 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, the main results, and methods of each team. The challenge serves as a benchmark to advance the state of the art and foster progress in image SR.
PNeRV: A Polynomial Neural Representation for Videos
Jun 27, 2024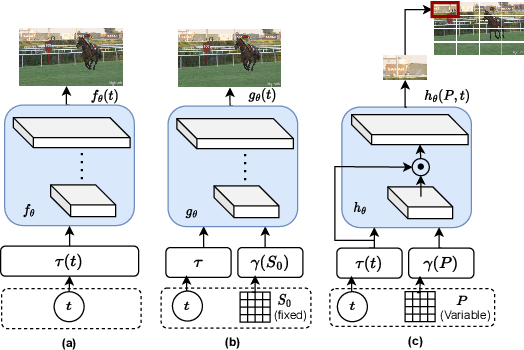

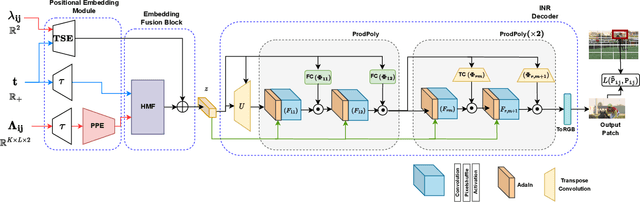

Extracting Implicit Neural Representations (INRs) on video data poses unique challenges due to the additional temporal dimension. In the context of videos, INRs have predominantly relied on a frame-only parameterization, which sacrifices the spatiotemporal continuity observed in pixel-level (spatial) representations. To mitigate this, we introduce Polynomial Neural Representation for Videos (PNeRV), a parameter-wise efficient, patch-wise INR for videos that preserves spatiotemporal continuity. PNeRV leverages the modeling capabilities of Polynomial Neural Networks to perform the modulation of a continuous spatial (patch) signal with a continuous time (frame) signal. We further propose a custom Hierarchical Patch-wise Spatial Sampling Scheme that ensures spatial continuity while retaining parameter efficiency. We also employ a carefully designed Positional Embedding methodology to further enhance PNeRV's performance. Our extensive experimentation demonstrates that PNeRV outperforms the baselines in conventional Implicit Neural Representation tasks like compression along with downstream applications that require spatiotemporal continuity in the underlying representation. PNeRV not only addresses the challenges posed by video data in the realm of INRs but also opens new avenues for advanced video processing and analysis.
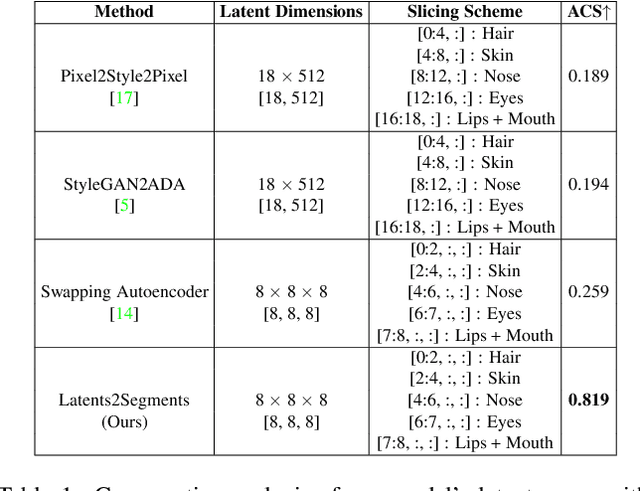
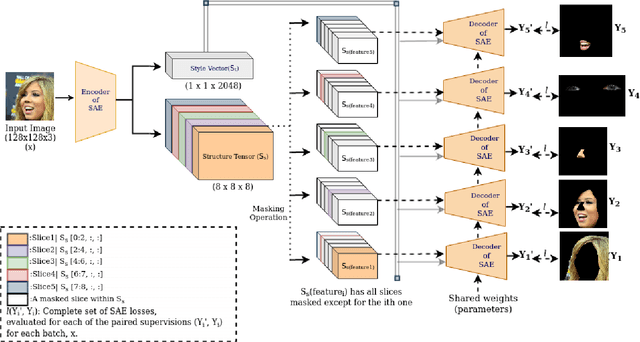
Latents2Semantics: Leveraging the Latent Space of Generative Models for Localized Style Manipulation of Face Images
Dec 22, 2023With the metaverse slowly becoming a reality and given the rapid pace of developments toward the creation of digital humans, the need for a principled style editing pipeline for human faces is bound to increase manifold. We cater to this need by introducing the Latents2Semantics Autoencoder (L2SAE), a Generative Autoencoder model that facilitates highly localized editing of style attributes of several Regions of Interest (ROIs) in face images. The L2SAE learns separate latent representations for encoded images' structure and style information. Thus, allowing for structure-preserving style editing of the chosen ROIs. The encoded structure representation is a multichannel 2D tensor with reduced spatial dimensions, which captures both local and global structure properties. The style representation is a 1D tensor that captures global style attributes. In our framework, we slice the structure representation to build strong and disentangled correspondences with different ROIs. Consequentially, style editing of the chosen ROIs amounts to a simple combination of (a) the ROI-mask generated from the sliced structure representation and (b) the decoded image with global style changes, generated from the manipulated (using Gaussian noise) global style and unchanged structure tensor. Style editing sans additional human supervision is a significant win over SOTA style editing pipelines because most existing works require additional human effort (supervision) post-training for attributing semantic meaning to style edits. We also do away with iterative-optimization-based inversion or determining controllable latent directions post-training, which requires additional computationally expensive operations. We provide qualitative and quantitative results for the same over multiple applications, such as selective style editing and swapping using test images sampled from several datasets.
Exploring the Effectiveness of Mask-Guided Feature Modulation as a Mechanism for Localized Style Editing of Real Images
Dec 10, 2022The success of Deep Generative Models at high-resolution image generation has led to their extensive utilization for style editing of real images. Most existing methods work on the principle of inverting real images onto their latent space, followed by determining controllable directions. Both inversion of real images and determination of controllable latent directions are computationally expensive operations. Moreover, the determination of controllable latent directions requires additional human supervision. This work aims to explore the efficacy of mask-guided feature modulation in the latent space of a Deep Generative Model as a solution to these bottlenecks. To this end, we present the SemanticStyle Autoencoder (SSAE), a deep Generative Autoencoder model that leverages semantic mask-guided latent space manipulation for highly localized photorealistic style editing of real images. We present qualitative and quantitative results for the same and their analysis. This work shall serve as a guiding primer for future work.
Hybrid Transformer Based Feature Fusion for Self-Supervised Monocular Depth Estimation
Nov 20, 2022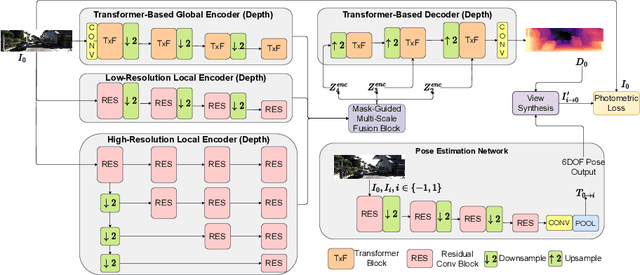
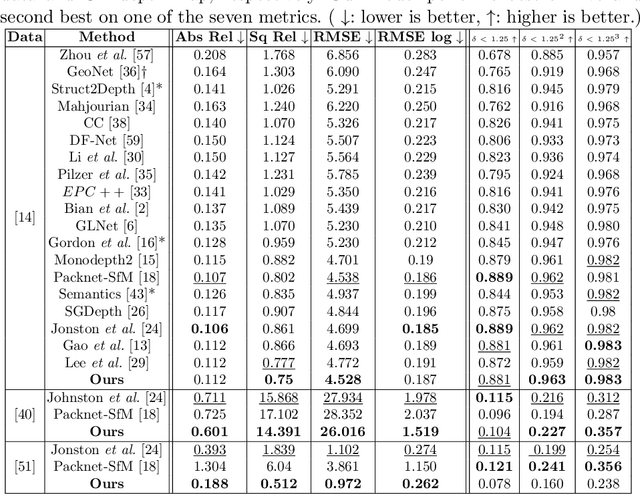
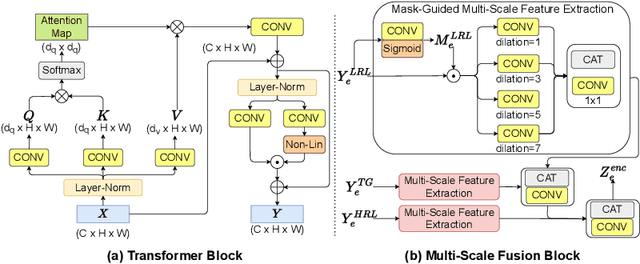

With an unprecedented increase in the number of agents and systems that aim to navigate the real world using visual cues and the rising impetus for 3D Vision Models, the importance of depth estimation is hard to understate. While supervised methods remain the gold standard in the domain, the copious amount of paired stereo data required to train such models makes them impractical. Most State of the Art (SOTA) works in the self-supervised and unsupervised domain employ a ResNet-based encoder architecture to predict disparity maps from a given input image which are eventually used alongside a camera pose estimator to predict depth without direct supervision. The fully convolutional nature of ResNets makes them susceptible to capturing per-pixel local information only, which is suboptimal for depth prediction. Our key insight for doing away with this bottleneck is to use Vision Transformers, which employ self-attention to capture the global contextual information present in an input image. Our model fuses per-pixel local information learned using two fully convolutional depth encoders with global contextual information learned by a transformer encoder at different scales. It does so using a mask-guided multi-stream convolution in the feature space to achieve state-of-the-art performance on most standard benchmarks.
Latents2Segments: Disentangling the Latent Space of Generative Models for Semantic Segmentation of Face Images
Jul 06, 2022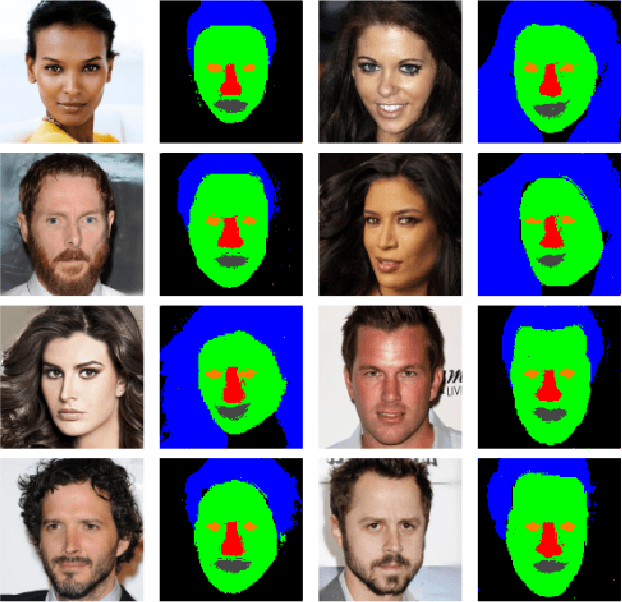

With the advent of an increasing number of Augmented and Virtual Reality applications that aim to perform meaningful and controlled style edits on images of human faces, the impetus for the task of parsing face images to produce accurate and fine-grained semantic segmentation maps is more than ever before. Few State of the Art (SOTA) methods which solve this problem, do so by incorporating priors with respect to facial structure or other face attributes such as expression and pose in their deep classifier architecture. Our endeavour in this work is to do away with the priors and complex pre-processing operations required by SOTA multi-class face segmentation models by reframing this operation as a downstream task post infusion of disentanglement with respect to facial semantic regions of interest (ROIs) in the latent space of a Generative Autoencoder model. We present results for our model's performance on the CelebAMask-HQ and HELEN datasets. The encoded latent space of our model achieves significantly higher disentanglement with respect to semantic ROIs than that of other SOTA works. Moreover, it achieves a 13% faster inference rate and comparable accuracy with respect to the publicly available SOTA for the downstream task of semantic segmentation of face images.